全文检索基础
1. Windows系统中的有搜索功能:打开“我的电脑”,按“F3”就可以使用查找的功能,查找指定的文件或文件夹。搜索的范围是整个电脑中的文件资源。
2. 在BBS、BLOG、新闻等系统中提供的搜索文章的功能,如这里的贴吧的例子。搜索的范围是系统内的文章数据(都在数据库中)
3. 搜索引擎,如Baidu或Google等,可以查询到互联网中的网页、PDF、DOC、PPT、图片、音乐、视频等。下图是使用百度搜索的效果:
以上的查询功能都类似。都是查询的文本内容,都是相同的查询方式,即找出含有指定字符串的资源,不同的只是查询范围(分别为硬盘、所有帮助文件、数据库、互联网)对于搜索,按被搜索的资源类型,分为两种:可以转为文本的、多媒体类型。我们上一节提到的搜索功能都是搜索的可以转为文本的资源(第一种)。注意,百度或谷歌提供的音乐或视频搜索不是多媒体搜索,他们是按文件名搜索。在智能手机上有一款音乐搜索的软件”猎曲奇兵”,可以让他听10秒钟的音乐,然后他就能上网找出这段音乐的名称、演奏者等信息。这是多媒体搜索, 图片搜索:Google有一款工具. 你只要把图片给它,它立即帮你找出有类似图片信息的图片
什么是全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对必要的词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。
按搜索的方式,上一节提到的搜索功能都是不处理语义,只是找出包含指定词的所有资源(只对词进行匹配)。下图就是显示“中国的首都是哪里”这个搜索要求对应的结果,可以看到,是没有“北京”这个结果的,结果页面都是出现了这些词的网页:
全文检索的应用场景:
我们使用Lucene,主要是做站内搜索,即对一个系统内的资源进行搜索。如BBS、BLOG中的文章搜索,网上商店中的商品搜索等。所以,学完Lucene后我们就可以为自已的项目增加全文检索的功能。跟这个学习内容相关的练习为:给商城商品进行多条件搜索.搜索完毕后,高亮符合条件的信息
全文检索与数据查询的区别:
1. 相关度排序: 查出的结果没有相关度排序,不知道我想要的结果在哪一页。我们在使用百度搜索时,一般不需要翻页,为什么?因为百度做了相关度排序:为每一条结果打一个分数,这条结果越符合搜索条件,得分就越高,叫做相关度得分,结果列表会按照这个分数由高到低排列,所以第1页的结果就是我们最想要的结果
2. 查询的方式: 全文检索的速度大大快于SQL的like搜索的速度。这是因为查询方式不同造成的,以查字典举例:数据库的like就是一页一页的翻,一行一行的找,而全文检索是先查目录,得到结果所在的页码,再直接翻到这一页
3. 定位不一样:一个更侧重高效、安全的存储、一个是侧重准确、方便的搜索
所以全文检索是数据的一个有利的补充,而不是相互排斥的关系:
例如我们的练习,基于商城的全文检索系统:我们可以在项目中构建一个对于商品的全文检索功能,让买家先搜索索引库中的内容(可以多条件匹配查询),得到商品的基本信息.感兴趣在通过连接.读取数据库的完成数据, 这样既可以实现高效的查询效率,又可以为分流查询请求
Lucene相关概念介绍:
1. Lucene Core, our flagship sub-project, provides Java-based indexing and search technology, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities
2. Lucene是一个用开源的全文检索框架
3. Lucene的主页为:http://lucene.apache.org/。本文档中所使用的Lucene为3.0.1的版本。
Lucene环境搭建
搭建Lucene的开发环境只需要加入Lucene的Jar包,要加入的jar包至少要有
a) lucene-core-3.0.1.jar(核心包)
b) contribanalyzerscommonlucene-analyzers-3.0.1.jar(分词器)
c) contribhighlighterlucene-highlighter-3.0.1.jar(高亮)
d) contribmemorylucene-memory-3.0.1.jar(高亮)
使用Lucene的API操作索引库
索引库是一个目录,里面是一些二进制文件,就如同数据库,所有的数据也是以文件的形式存在文件系统中的。我们不能直接操作这些二进制文件,而是使用Lucene提供的API完成相应的操作,就像操作数据库应使用SQL语句一样
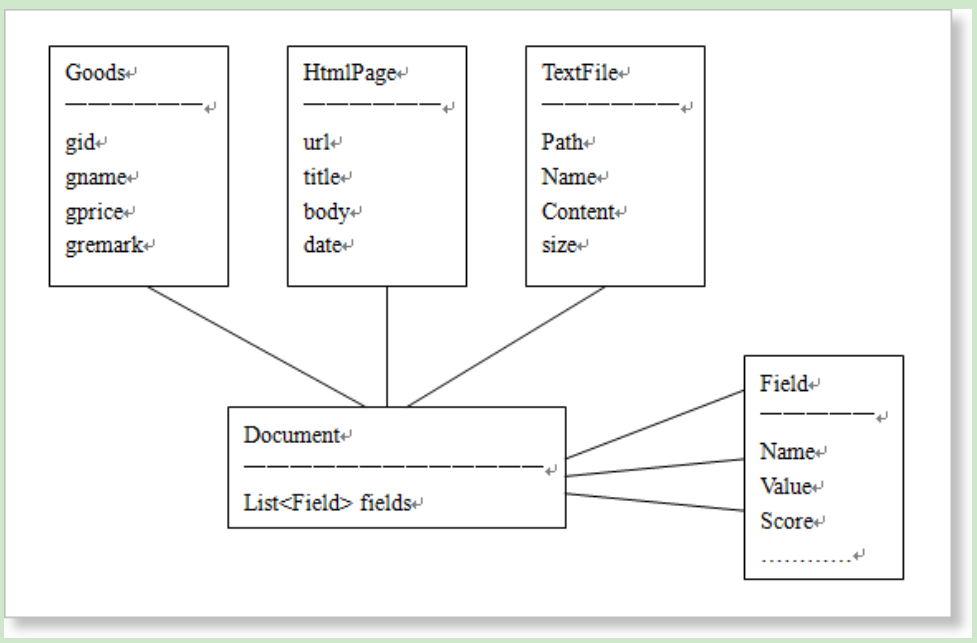
对索引库的操作可以分为两种:管理与查询。管理索引库使用IndexWriter,从索引库中查询使用IndexSearcher。Lucene的数据结构为Document与Field。Document代表一条数据,Field代表数据中的一个属性。一个Document中有多个Field,Field的值为String型,因为Lucene只处理文本。
我们只需要把在我们的程序中的对象转成Document,就可以交给Lucene管理了,搜索的结果中的数据列表也是Document的集合。
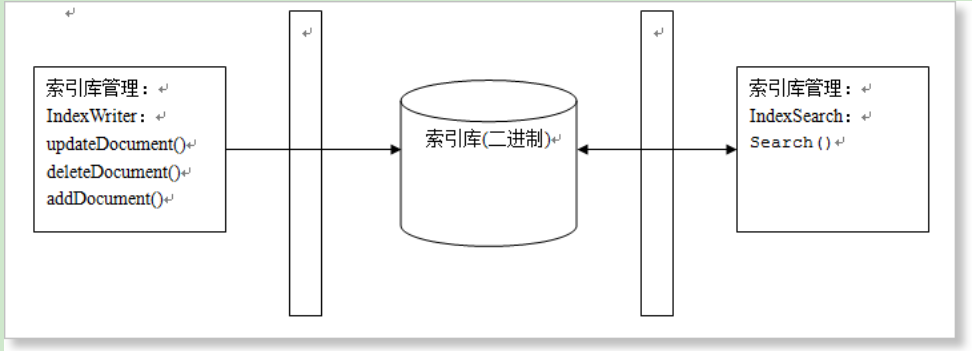
索引库内部存储结构图如下: