Lucene简介
Lucene最初由鼎鼎大名Doug Cutting开发,2000年开源,现在也是开源全文检索方案的不二选择,它的特点概述起来就是:全Java实现、开源、高性能、功能完整、易拓展,功能完整体现在对分词的支持、各种查询方式(前缀、模糊、正则等)、打分高亮、列式存储(DocValues)等等。
而且Lucene虽已发展10余年,但仍保持着一个活跃的开发度,以适应着日益增长的数据分析需求,最新的6.0版本里引入block k-d trees,全面提升了数字类型和地理位置信息的检索性能,另基于Lucene的Solr和ElasticSearch分布式检索分析系统也发展地如火如荼,ElasticSearch也在我们项目中有所应用
·索引原理
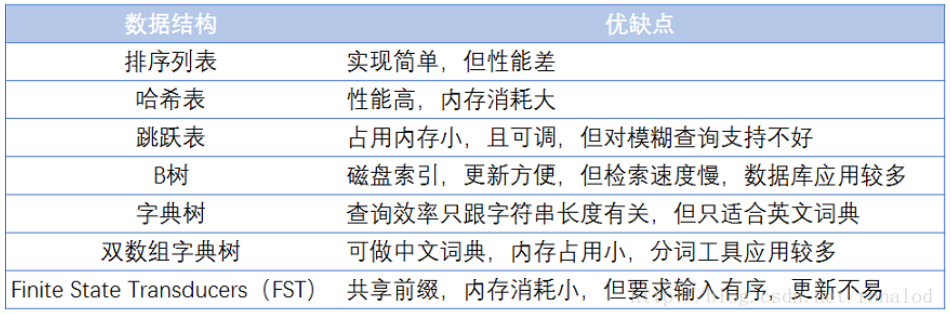
全文检索技术由来已久,绝大多数都基于倒排索引来做,曾经也有过一些其他方案如文件指纹。倒排索引,顾名思义,它相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
创建一个对文件的lucene 进行检索

再创建一个存放索引的文件夹
这里 我使用的是 lucene的版本是 3.5


1 <!-- Lucene解析库 --> 2 <dependency> 3 <groupId>org.apache.lucene</groupId> 4 <artifactId>lucene-queryparser</artifactId> 5 <version>3.5.0</version> 6 </dependency> 7 <!-- Lucene核心库 --> 8 <dependency> 9 <groupId>org.apache.lucene</groupId> 10 <artifactId>lucene-core</artifactId> 11 <version>3.5.0</version> 12 </dependency>
对文件夹中的文件进行添加索引
1 public void creatIndex() throws IOException { 2 IndexWriter writer=null; 3 try { 4 Directory directory= FSDirectory.open(new File("E:\Lucence\Lucence\index")); 5 IndexWriterConfig config= 6 new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35)); 7 writer=new IndexWriter(directory,config); 8 File file=new File("E:\Lucence\Lucence\LucenceTest"); 9 for (File f:file.listFiles() 10 ) { 11 Document document=new Document(); 12 document.add(new Field("filename",f.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED)); 13 document.add(new Field("filePath",f.getPath(),Field.Store.YES,Field.Index.NOT_ANALYZED)); 14 document.add(new Field("fileContent",new FileReader(f))); 15 writer.addDocument(document); 16 } 17 } catch (Exception e) { 18 e.printStackTrace(); 19 }finally { 20 try { 21 writer.close(); 22 } catch (IOException e) { 23 e.printStackTrace(); 24 } 25 }
对文件进行检索查询
1 public void searchIndex(){ 2 IndexReader reader=null; 3 try { 4 Directory directory= FSDirectory.open(new File("E:\Lucence\Lucence\index")); 5 reader=IndexReader.open(directory); 6 IndexSearcher searcher=new IndexSearcher(reader); 7 QueryParser queryParser=new QueryParser(Version.LUCENE_35,"fileContent",new StandardAnalyzer(Version.LUCENE_35)); 8 Query query=queryParser.parse("java"); 9 TopDocs topDocs=searcher.search(query,2); 10 ScoreDoc[] scoreDocs = topDocs.scoreDocs; 11 for (ScoreDoc s:scoreDocs 12 ) { 13 Document document=searcher.doc(s.doc); 14 System.out.println("文件名称======>>>>>"+document.get("filename")); 15 } 16 } catch (Exception e) { 17 e.printStackTrace(); 18 } 19 }