一.定义
官网介绍:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
窗口函数属于sql中比较高级的函数,mysql从8.0版本才支持窗口函数,mysql5.6,5.7都有窗口函数,oracle 里面一直支持窗口函数,hive也支持窗口函数
窗口函数=函数+窗口
窗口:函数在运算时,我们可以指定函数运算的数据范围
Hive中以下函数是窗口函数:
窗口函数:
LEAD LEAD(col,n, default_val):往后第n行数据 col 列名 ;n 往后第几行 默认为1 ; 默认值 默认null
LAG LAG(col,n,default_val):往前第n行数据 ; col 列名 n 往前第几行 默认为1; 默认值 默认null
FIRST_VALUE 在当前窗口下的第一个值 FIRST_VALUE (col,true/false) 如果设置为true,则跳过空值。
LAST_VALUE 在当前窗口下的最后一个值 FIRST_VALUE (col,true/false)如果设置为true,则跳过空值。
标准聚合函数
- COUNT
- SUM
- MIN
- MAX
- AVG
分析排名函数
-
RANK() 排序相同时会重复,总数不会变
-
DENSE_RANK() 排序相同时会重复,总数会减少
-
ROW_NUMBER() 会根据顺序计算
-
NTILE():根据窗口排序,将数据分为n组,若查找前50%,则条件为n/2组
二.语法
(1)窗口函数 over([partition by 字段] [order by 字段] [ 窗口语句])
partition by 给查出来的结果集按照某个字段分区,分区以后,开窗的大小最大不会超过分区数据的大小
一旦分区之后,我们必须在单个分区内指定窗口。
order by 给分区内的数据按照某个字段排序
(2)窗口语句
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
常见用法:rows between unbounded preceding and unbounded following
两种特殊情况
当指定ORDER BY缺少WINDOW子句时,WINDOW规范默认为RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
如果同时缺少ORDER BY和WINDOW子句,则WINDOW规范默认为ROW BETWEENUND UNBOUNDED PRECEDING和UNBOUNDED FOLLOWING。
三.需求练习一
需求说明
根据用户的消费记录统计一下需求
name orderdate cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
需求1: 查询在2017年4月份购买过的顾客及总人数
需求3: 查询顾客的购买明细及月购买总额
需求3: 上述的场景, 将每个顾客的cost按照日期进行累加
需求4: 查询顾客购买明细以及上次的购买时间和下次购买时间
需求5: 查询顾客每个月第一次的购买时间 和 每个月的最后一次购买时间
数据准备
消费记录数据:business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
导数据
load data local inpath "/opt/module/hive/datas/business.txt" into table business;
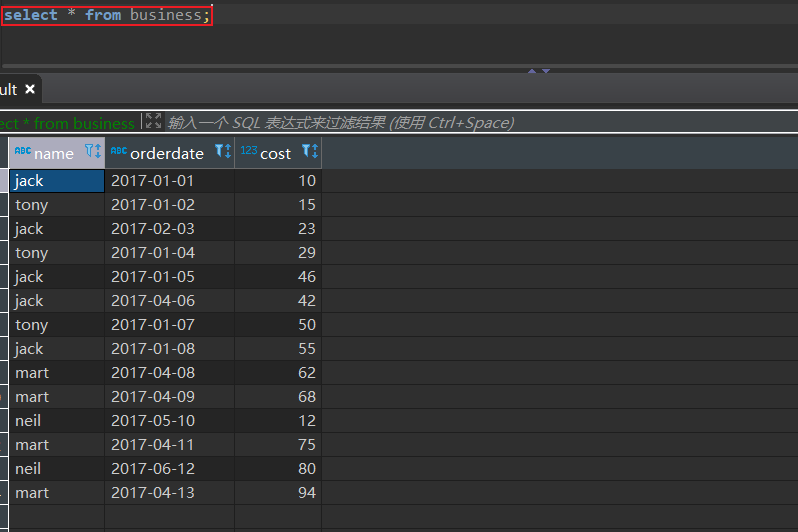
查询验证表数据
select * from business;
作为练习可以使用本地模式:set hive.exec.mode.local.auto=true;
count,sum
需求1
查询在2017年4月份购买过的顾客及总人数
select
name,
count(*) over()
from business
where substring(orderdate,1,7)='2017-04'
group by name;
结果

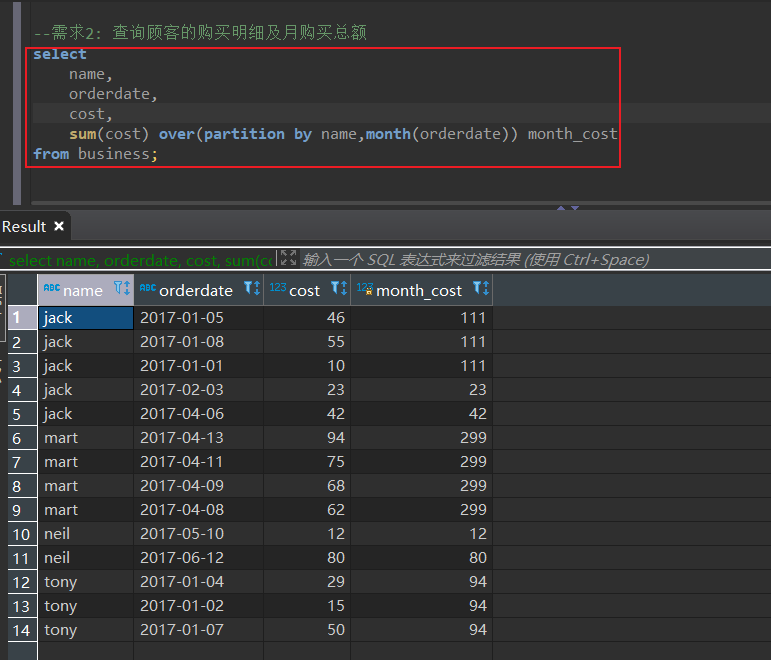
需求2
查询顾客的购买明细及月购买总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) month_cost
from business;
lag,lead
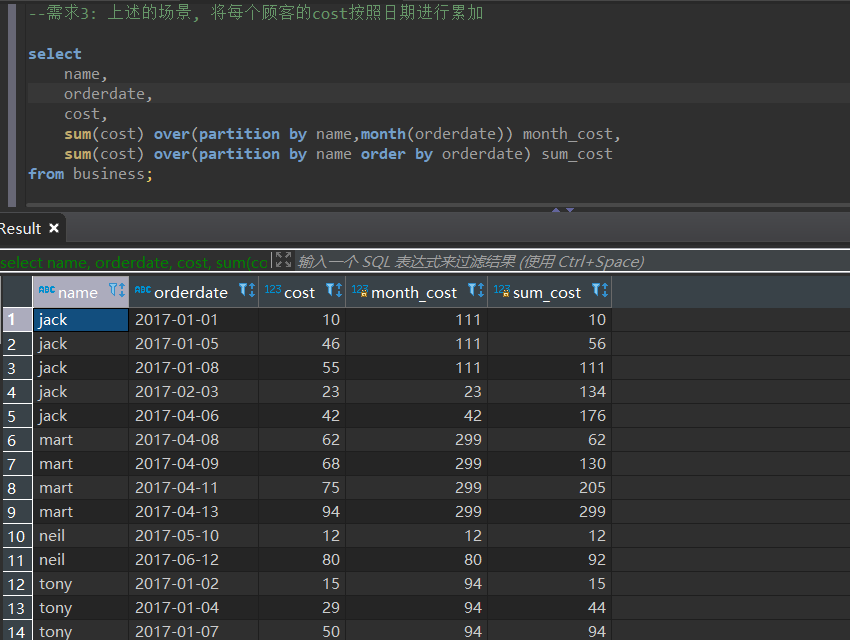
需求3
上述的场景,将每个顾客的cost按照日期进行累加
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) month_cost,
sum(cost) over(partition by name order by orderdate) sum_cost
from business;
需求4
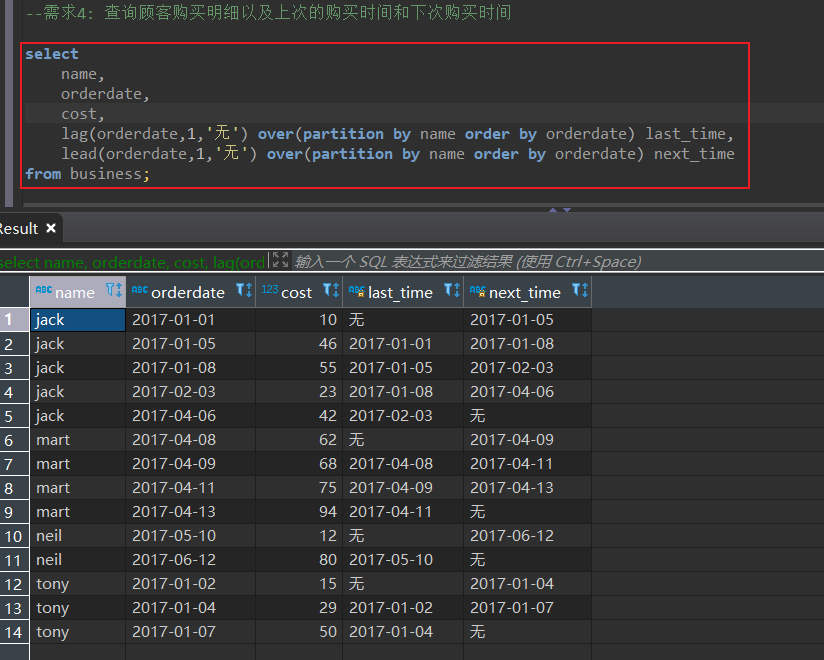
查询顾客购买明细以及上次的购买时间和下次购买时间
select
name,
orderdate,
cost,
lag(orderdate,1,'无') over(partition by name order by orderdate) last_time,
lead(orderdate,1,'无') over(partition by name order by orderdate) next_time
from business;
first_value,last_value
需求5
注意:LAST_VALUE和FIRST_VALUE 需要自定义windows字句,否则出现错误
select
name,
orderdate,
first_value(orderdate,false) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) first_time,
last_value(orderdate,false) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) last_time
from business;

四.需求练习二
需求说明
计算成绩排名
name subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
数据准备
原始数据:score.txt
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
建表
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by " ";
导数据
load data local inpath '/opt/module/hive/datas/score.txt' into table score;
验证表数据
select * from score;
rank,dense_rank,row_number
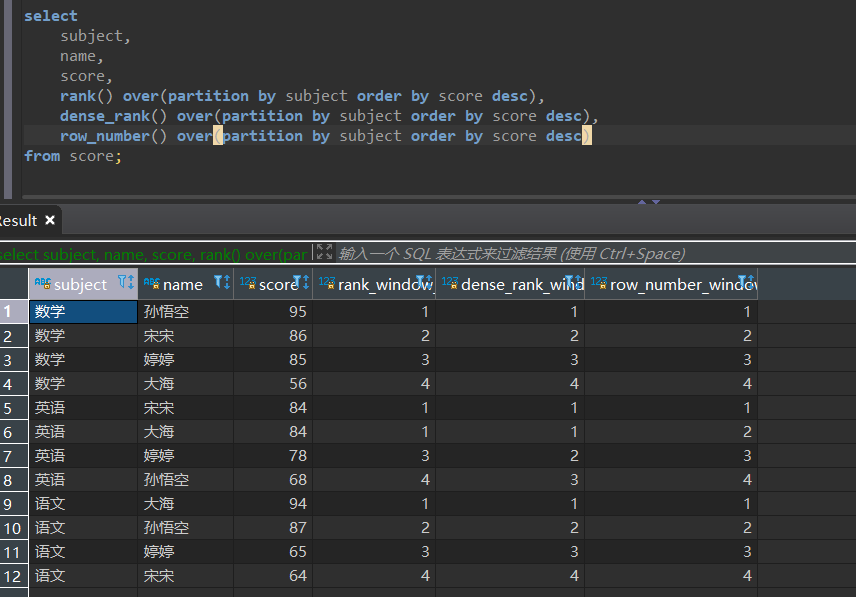
需求1
计算各科成绩排名
select
subject,
name,
score,
rank() over(partition by subject order by score desc),
dense_rank() over(partition by subject order by score desc),
row_number() over(partition by subject order by score desc)
from score;
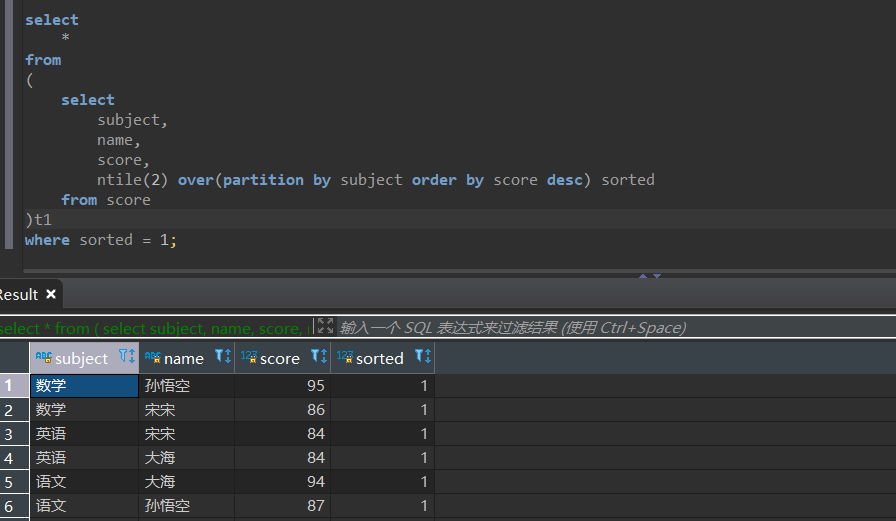
ntile
需求2
查看各科成绩前50%的学生成绩
select
*
from
(
select
subject,
name,
score,
ntile(2) over(partition by subject order by score desc) sorted
from score
)t1
where sorted = 1;