一、简单动态页面爬取
我们之前进行的页面爬取工作都是基于静态的页面。但是现在的很多页面都采用了动态页面,这些动态页面又有百分之七十是由javascript写的,因此我们了解如何从javascript页面爬取信息就显得非常的重要。
先认识具体情况之前,我们需要先了解什么是ajax,ajax它的英文全称是asynchronous javascript and xml,是一种异步JavaScript和xml。我们可以通过ajax进行页面数据请求,它返回的数据格式是json类型的。
然后我们就可以根据页面的ajax格式进行数据爬取。以下是一个简单的页面爬取。
import json from Chapter3 import download import csv def simpletest(): ''' it will write the date to the country.csv the json data has the attribute records, and the records has area, country and capital value :return: ''' fileds = ('area', 'country', 'capital') writer = csv.writer(open("country.csv", "w")) writer.writerow(fileds) d = download.Downloader() html = d("http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=A") try: ajax = json.loads(html) except Exception as e: print str(e) else: for record in ajax['records']: row = [record[filed] for filed in fileds] writer.writerow(row) if __name__ == "__main__": simpletest()
不知道是不是这个网站的问题,现在已经不能从上面的网址下载数据了,执行上面的程序,以下会是结果图: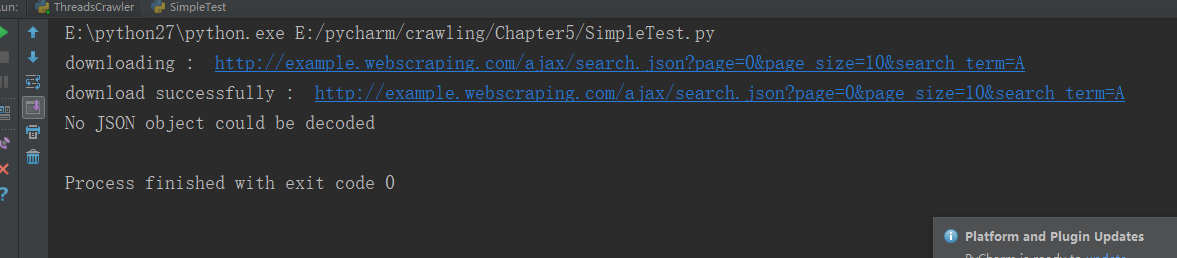
二、渲染动态页面
在开始之前呢,首先要先下载pyside,直接用 pip install pyside 命令行即可。
然后我们就可以利用PySide来进行数据爬取。
from PySide.QtWebKit import * from PySide.QtGui import * from PySide.QtCore import * import lxml.html def simpletest(): ''' get content of the div # result in http://example.webscraping.com/places/default/dynamic :return: content ''' app = QApplication([]) webview = QWebView() loop = QEventLoop() # finish the loop if we have finished load the html webview.loadFinished.connect(loop.quit) webview.load(QUrl("http://example.webscraping.com/places/default/dynamic")) loop.exec_() htmled = webview.page().mainFrame().toHtml() # get the special content tree = lxml.html.fromstring(htmled) return tree.cssselect('#result')[0].text_content() content = simpletest() print content
我们回顾简单动态页面爬取的内容,之前的那种方式不成功,我想主要的原因是我的网址写错了,所以学习了pyside之后,我们可以使用这种全新的方式进行数据爬取。以下是具体代码:
def getallcountry(): ''' open the html and set search term = a and page_size = 10 and then click auto by javascript :return: ''' app = QApplication([]) webview = QWebView() loop = QEventLoop() # finish the loop if we have finished load the html webview.loadFinished.connect(loop.quit) webview.load(QUrl("http://example.webscraping.com/places/default/search")) loop.exec_() # show the webview webview.show() frame = webview.page().mainFrame() # set search text is b frame.findFirstElement('#search_term').setAttribute('value', 'b') # set page_size is 10 frame.findFirstElement('#page_size option:checked').setPlainText('10') # click search button auto frame.findFirstElement('#search').evaluateJavaScript('this.click()') app.exec_()
以下是结果图:

上面的过程我们只是利用pyside能够在页面得到结果,但是还没有将数据爬取下来。因为ajax响应事件有一定的延迟,所以我们有以下三种方式可以进行数据爬取:
1、等待一定时间(低效)
2、重写QT的网络管理器,跟踪url请求的完成时间(不适用于客户端出问题的情况)
3、轮询页面,等待特定内容出现(检查时会浪费cpu时间)
总的来说,第三种方法是比较可靠并且方便的。以下是它的概念代码:它的主要思想在于while循环,如果没有找到elements,就不断的尝试。

为了将以上的几种方法变得更加具有通用性,我们可以把他们写在 一个类中。这个类包含的功能有:下载,获取html,找到相应的元素,设置属性值,设置文本值,点击,轮询页面,等待下载
from PySide.QtCore import * from PySide.QtGui import * from PySide.QtWebKit import * import time import sys class BrowserRender(QWebView): def __init__(self, show=True): ''' if the show is true then we can see webview :param show: ''' self.app = QApplication(sys.argv) QWebView.__init__(self) if show: self.show() def download(self, url, timeout=60): ''' download the url if timeout is false :param url: the download url :param timeout: the timeout time :return: html if not timeout ''' loop = QEventLoop() timer = QTimer() timer.setSingleShot(True) timer.timeout.connect(loop.quit) self.loadFinished.connect(loop.quit) self.load(QUrl(url)) timer.start(timeout*1000) loop.exec_() if timer.isActive(): timer.stop() return self.html() else: print "Request time out "+url def html(self): ''' shortcut to return the current html :return: ''' return self.page().mainFrame().toHtml() def find(self, pattern): ''' find all elements that match the pattern :param pattern: :return: ''' return self.page().mainFrame().findAllElements(pattern) def attr(self, pattern, name, value): ''' set attribute for matching pattern :param pattern: :param name: :param value: :return: ''' for e in self.find(pattern): e.setAttribute(name, value) def text(self, pattern, value): ''' set plaintext for matching pattern :param pattern: :param value: :return: ''' for e in self.find(pattern): e.setPlainText(value) def click(self, pattern): ''' click matching pattern :param pattern: :return: ''' for e in self.find(pattern): e.evaluateJavaScript("this.click()") def wait_load(self, pattern, timeout=60): ''' wait untill pattern is found and return matches :param pattern: :param timeout: :return: ''' deadtiem = time.time() + timeout while time.time() < deadtiem: self.app.processEvents() matches = self.find(pattern) if matches: return matches print "wait load timed out" br = BrowserRender() br.download("http://example.webscraping.com/places/default/search") br.attr('#search_term', 'value', '.') br.text('#page_size option:checked', '1000') br.click('#search') elements = br.wait_load('#results a') countries = [e.toPlainText().strip() for e in elements] print countries
在调用的时候,一定要注意要把pattern写对,我就把#results a 写成了#result a,导致一直出现time out现象
三、selenium
selenium 是一个简单的能够与页面交互的接口,它提供了使得浏览器自动化的API接口。selenium的使用非常的简单,它相当于已经把我们想要的函数都已经封装起来了,我们所需要的就是调用相应的函数。
以下是我们selenium来实现browsrender实现的内容。
from selenium import webdriver def simpleuse(): driver = webdriver.Chrome() driver.get("http://example.webscraping.com/places/default/search") driver.find_element_by_id("search_term").send_keys('.') js = "document.getElementById('page_size').options[1].text='1000'" driver.execute_script(js) driver.find_element_by_id('search').click() driver.implicitly_wait(30) links = driver.find_element_by_css_selector("#results a") countries = [link.text for link in links] print countries
driver.close() if __name__ == "__main__": simpleuse()
明明配置了chromedriver,但是它一直显示未在path中找到可执行文件:
这个问题还没解决,等待后续吧。
这个问题已经解决了,只需要去官网上下载对应版本的chromedriver.exe,然后将保存它的绝对路径加入 webdriver.chrome(绝对路径)即可。现在的代码变成如下:
from selenium import webdriver def simpleuse(): driver = webdriver.Chrome('E:chromedriverchromedriver.exe') driver.get("http://example.webscraping.com/places/default/search") driver.find_element_by_id("search_term").send_keys('.') js = "document.getElementById('page_size').options[1].text='1000'" driver.execute_script(js) driver.find_element_by_id('search').click() driver.implicitly_wait(30) links = driver.find_elements_by_css_selector("#results a") countries = [link.text for link in links] print countries driver.close() if __name__ == "__main__": simpleuse()
四、小结
首先,先采用逆向工程分析页面,然后使用json即可对页面进行解析。然后呢,使用了pyside进行动态页面渲染,最后了为了简便写法使用了selenium。