- 取样,从N个数中取出M个数. 当要求这M个数不重复时,就不是简单的 low + int (rand * (high + 1 - low)). 这时最简单的方法是
1 //Algorithm S 2 intialize set S to empty 3 Size := 0 4 while Size < M do 5 T := RandInt(1, N) 6 if T is not in S then 7 insert T in S 8 Size := Size + 1
- Algorithm S 在极端情况下,却会有很低的效率. 如 N = 100, M = 100, 当Size = 99时, 第100次产生 T 还要进行平均达100次的rand. Bob Floyd的取样算法每产生一个随机数只需要调用一次rand. 这种方法的正确性在于生成序列的过程中每个元素的被选中的概率都是 M / N.
Floyd's algorithm 的递归版伪代码如下:
1 //Algorithm F1 2 funciton Sample(M, N) 3 if M = 0 then 4 return the empty set 5 else 6 S := Sample(M - 1, N - 1) 7 T := RandInt(1, N) 8 if T is not in S then 9 insert T in S 10 else 11 insert N in S 12 return S
非递归版为
1 //Algorithm F2 2 initialize set S to empty 3 for J := N - M + 1 to N do 4 T := RandInt(1, J) 5 if T is not in S then 6 insert T in S 7 else 8 insert J in S
还有种有意思的解法
1 //Knuth's Seminumerical Algorithm 2 Select := M; Remaining := N 3 for I := 1 to N do 4 if RandReal(0, 1) < Select/ Remaining then 5 print I; Select = Select - 1 6 Remaining := Remaining - 1
- 考虑不仅要求的数是随机的,而且生成的数的次序也要求是随机的. Floyd 的随机排列算法如下:
1 //Algorithm P 2 initialize sequence S to empty 3 for J := N - M + 1 to N do 4 T := RandInt(1, J) 5 if T is not in S then 6 prefix T to S 7 else 8 insert J in S after T
即将Algorithm F2中的都在尾插入改为,将T插到最前或者将J插到S中的T之后. 所以每一个Algorithm F2产生的序列都唯一对应一个Algorithm P产生的序列.而由于Algorithm F2产生的序列的排列方式为(N - M + 1) ^ M种, 并不是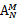 , 所以这种算法不能产生所有的随机排布.
, 所以这种算法不能产生所有的随机排布.
, 所以这种算法不能产生所有的随机排布. 同时,也有一种基于swap的算法
1 //Algorithm N 2 for I := 1 to N do 3 X[I] := I 4 for I := 1 to M do 5 J := RandInt(1, N) 6 Swap(X[j], X[I])
这个算法的空间复杂度是O(N), 时间复杂度也是O(N). 当N比M大很多时,不如Floyd的Algorithm P的空间O(M), 时间O(M)