1 全文检索工具,方便实现全文检索功能。
2 全文检索, 先对要搜索的文档进行分词,形成索引,根据索引经行检索。
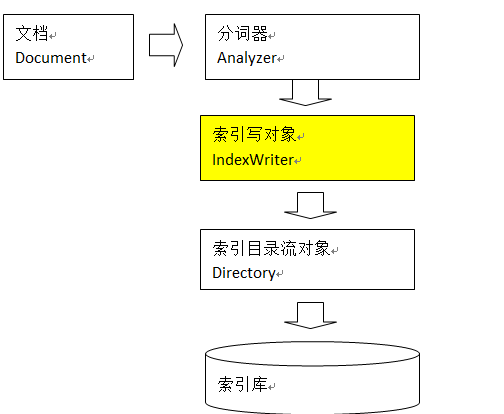
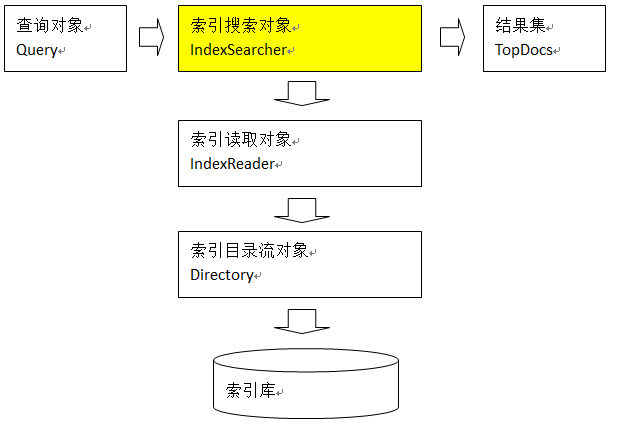
3 全文检索流程
索引流程:采集数据, 处理数据,创建索引
搜索流程:输入查询条件,Lucene查询器查询索引, 索引库取出结果
4 IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。


public class IndexManager { @Test public void createIndex() throws Exception { BookDao bookDao = new BookDaoImpl(); List<Book> books = bookDao.queryBooks(); List<Document> documents = new ArrayList<>(); Document document = null; for (Book book : books) { document = new Document(); Field id = new TextField("id", book.getId().toString(), Store.YES); Field name = new TextField("name", book.getName(), Store.YES); Field price = new TextField("price", book.getPrice().toString(), Store.YES); Field detail = new TextField("detail", book.getDetail(), Store.YES); document.add(id); document.add(name); document.add(price); document.add(detail); documents.add(document); } Analyzer analyzer = new StandardAnalyzer(); IndexWriter indexWriter = null; IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); Directory directory = FSDirectory.open(new File("E:\index\")); indexWriter = new IndexWriter(directory, config); for (Document d : documents) { indexWriter.addDocument(d); } indexWriter.close(); } }
5 搜索输入语法 and or not 大写
public void indexSearch() throws Exception { QueryParser queryParser = new QueryParser("detail", new StandardAnalyzer()); Query query = queryParser.parse("detail:好 AND 大"); Directory directory = FSDirectory.open(new File("E:\index\")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(indexReader); TopDocs docs = searcher.search(query, 10); ScoreDoc[] scoreDocs = docs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docId = scoreDoc.doc; Document document = searcher.doc(docId); System.out.println(document.get("id")); System.out.println(document.get("name")); System.out.println(document.get("detail")); } indexReader.close(); }
5 field 属性
1 是否分词 tokenized 分词为了索引,(商品名称,描述,价格),不分词也可以索引(商品id)
2 是否索引ndexed
3 是否存储 stored 是否将field存到文档域中,存储目的显示。 名称,价格,id,图片地址
@Test public void createIndex() throws Exception { BookDao bookDao = new BookDaoImpl(); List<Book> books = bookDao.queryBooks(); List<Document> documents = new ArrayList<>(); Document document = null; for (Book book : books) { document = new Document(); Field id = new StringField("id", book.getId().toString(), Store.YES); Field name = new TextField("name", book.getName(), Store.YES); Field price = new FloatField("price", book.getPrice(), Store.YES); Field detail = new TextField("detail", book.getDetail(), Store.NO); document.add(id); document.add(name); document.add(price); document.add(detail); documents.add(document); } Analyzer analyzer = new StandardAnalyzer(); IndexWriter indexWriter = null; IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); Directory directory = FSDirectory.open(new File("E:\index\")); indexWriter = new IndexWriter(directory, config); for (Document d : documents) { indexWriter.addDocument(d); } indexWriter.close(); } }
6 修改索引
@Test public void updateIndex() throws Exception { Analyzer analyzer = new StandardAnalyzer(); IndexWriter indexWriter = null; IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); Directory directory = FSDirectory.open(new File("E:\index\")); indexWriter = new IndexWriter(directory, config); Document document = new Document(); document.add(new TextField("name", "fdrr", Store.YES)); indexWriter.updateDocument(new Term("name", "fddd"), document); indexWriter.close(); }
7 相关度排序
就是查询关键字和查询结构的匹配相关度,匹配度越高越靠前,通过打分经行排序
打分两个步骤:1 计算词的权重 2 根据权重打分
词的权重:词就是term , 一个term对一个文档的重要性就是权重
影响词的权重 1 tf 词在同一个文档出现频率,tf越高词的权重越高
2 df 词在多个文档出现频率,tf越高词的权重越低
8 设置boost值影响打分。
boost 加权值 默认。1.0f 可以在创建索引时,也可以在查询时。
在MultiFieldQueryParser创建时设置boost值。
solr
1 基于Lucene的全文检索服务器,
索引: solr客户端向solr服务器发送post请求,请求内容包括field信息的xml文档,通过文档实现对索引维护。
搜索: get请求,服务器返回一个xml文档