一、关系图
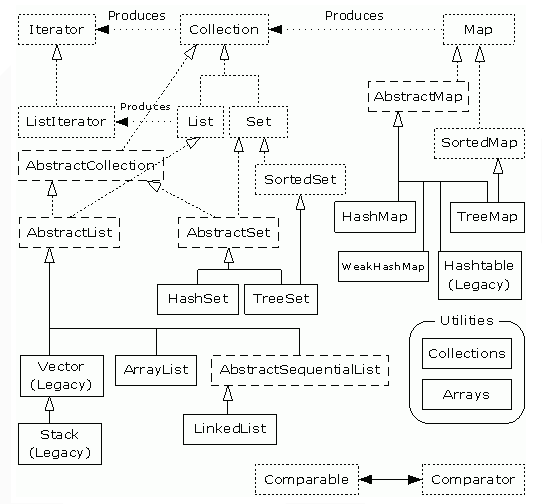
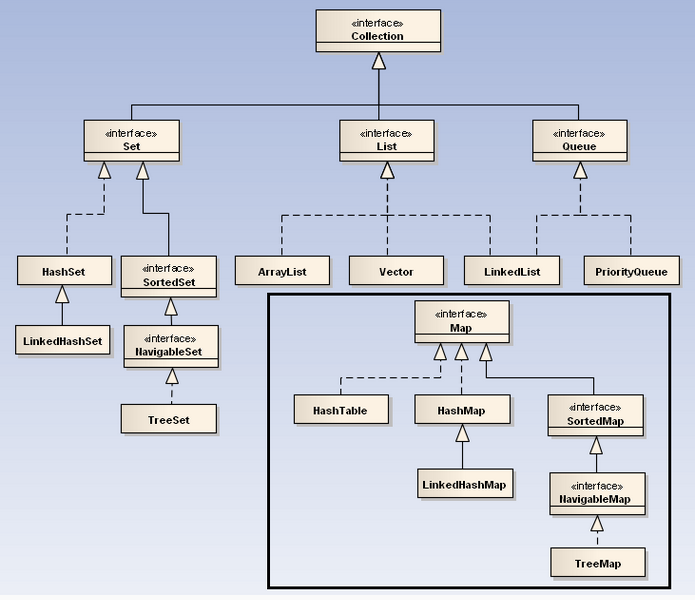
二、几个比较重要的接口和类简介

1、List(有序、索引、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法。
ArrayList(数组、快速访问)
ArrayList可以理解成一个可增长的数组,因此可以通过索引快速访问。
LinkedList(链表、快速插入、删除)
LinkedList是双向链接的,拥有链表的快速插入和删除的特性。
Vector
ArrayList的线程安全版,但是性能较低。
2、Set(唯一、无序)
HashSet
HashSet是通过HashMap实现的,Set使用了Map中的key,因此Set具有唯一性。而HashMap中通过HashCode和 equals方法来确保唯一。 HashSet的contains和remove依据都是hashCode方法,如果该方法返回值相同,才判断 equals方法。
TreeSet
TreeSet是通过TreeMap实现的,能进行排序。
3、Map(键值对、键唯一)
Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复。
HashMap
Hashmap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空,同时效率较低。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时 用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据
较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现。
三、面试过程中可能问到的问题
几个面试常见问题:
1.Q:ArrayList和Vector有什么区别?HashMap和HashTable有什么区别?
A:Vector和HashTable是线程同步的(synchronized)。性能上,ArrayList和HashMap分别比Vector和Hashtable要好。
2.Q:大致讲解java集合的体系结构
A:List、Set、Map是这个集合体系中最主要的三个接口。
其中List和Set继承自Collection接口。
Set不允许元素重复。HashSet和TreeSet是两个主要的实现类。
List有序且允许元素重复。ArrayList、LinkedList和Vector是三个主要的实现类。
Map也属于集合系统,但和Collection接口不同。Map是key对value的映射集合,其中key列就是一个集合。key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是三个主要的实现类。
SortedSet和SortedMap接口对元素按指定规则排序,SortedMap是对key列进行排序。
3.Q:Comparable和Comparator区别
A:调用java.util.Collections.sort(List list)方法来进行排序的时候,List内的Object都必须实现了Comparable接口。
java.util.Collections.sort(List list,Comparator c),可以临时声明一个Comparator 来实现排序。
Collections.sort(imageList, new Comparator() {
public int compare(Object a, Object b) {
int orderA = Integer.parseInt( ( (Image) a).getSequence());
int orderB = Integer.parseInt( ( (Image) b).getSequence());
return orderA - orderB;
}
});
如果需要改变排列顺序
改成return orderb - orderA 即可。
4.Q:简述equals()和hashCode()
A: 1) 首先equals()和hashcode()这两个方法都是从object类中继承过来的。
2) 其次是hashcode() 方法,在object类中定义如下:
public native int hashCode();
说明是一个本地方法,它的实现是根据本地机器相关的。当然我们可以在自己写的类中覆盖hashcode()方法,比如String、Integer、Double。。。。等等这些类都是覆盖了hashcode()方法的。
3) equals()相等的两个对象,hashcode()一定相等;
equals()不相等的两个对象,却并不能证明他们的hashcode()不相等。换句话说,equals()方法不相等的两个对象,hashcode()有可能相等。(我的理解是 由于哈希码在生成的时候产生冲突造成的)。
反过来:hashcode()不等,一定能推出equals()也不等;hashcode()相等,equals()可能相等,也可能不等。
4) 谈到hashcode()和equals()就不能不说到hashset,hashmap,hashtable中的使用,具体是怎样呢,请看如下分析:
Hashset是继承Set接口,Set接口又实现Collection接口,这是层次关系。那么hashset是根据什么原理来存取对象的呢?
在hashset中不允许出现重复对象,元素的位置也是不确定的。在hashset中又是怎样判定元素是否重复的呢?这就是问题的关键所在,经过一下午的查询求证终于获得了一点启示,和大家分享一下,在java的集合中,判断两个对象是否相等的规则是:
1),判断两个对象的hashCode是否相等
如果不相等,认为两个对象也不相等,完毕
如果相等,转入2)
(这一点只是为了提高存储效率而要求的,其实理论上没有也可以,但如果没有,实际使用时效率会大大降低,所以我们这里将其做为必需的。后面会重点讲到这个问题。)
2),判断两个对象用equals运算是否相等
如果不相等,认为两个对象也不相等
如果相等,认为两个对象相等(equals()是判断两个对象是否相等的关键)
为什么是两条准则,难道用第一条不行吗?不行,因为前面已经说了,hashcode()相等时,equals()方法也可能不等,所以必须用第2条准则进行限制,才能保证加入的为非重复元素。
比如下面的代码:
public static void main(String args[]){
String s1=new String("zhaoxudong");
String s2=new String("zhaoxudong");
System.out.println(s1==s2);//false
System.out.println(s1.equals(s2));//true
System.out.println(s1.hashCode());//s1.hashcode()等于s2.hashcode()
System.out.println(s2.hashCode());
Set hashset=new HashSet();
hashset.add(s1);
hashset.add(s2);
/*实质上在添加s1,s2时,运用上面说到的两点准则,可以知道hashset认为s1和s2是相等的,是在添加重复元素,所以让s2覆盖了s1;*/
Iterator it=hashset.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
最后在while循环的时候只打印出了一个”zhaoxudong”。
输出结果为:false
true
-967303459
-967303459
这是因为String类已经重写了equals()方法和hashcode()方法,所以在根据上面的第1.2条原则判定时,hashset认为它们是相等的对象,进行了重复添加。
但是看下面的程序:
import java.util.*;
public class HashSetTest
{
public static void main(String[] args)
{
HashSet hs=new HashSet();
hs.add(new Student(1,"zhangsan"));
hs.add(new Student(2,"lisi"));
hs.add(new Student(3,"wangwu"));
hs.add(new Student(1,"zhangsan"));
Iterator it=hs.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
class Student
{
int num;
String name;
Student(int num,String name)
{
this.num=num;
this.name=name;
}
public String toString()
{
return num+":"+name;
}
}
输出结果为:
1:zhangsan
1:zhangsan
3:wangwu
2:lisi
问题出现了,为什么hashset添加了相等的元素呢,这是不是和hashset的原则违背了呢?回答是:没有
因为在根据hashcode()对两次建立的new Student(1,"zhangsan")对象进行比较时,生成的是不同的哈希码值,所以hashset把他当作不同的对象对待了,当然此时的equals()方法返回的值也不等(这个不用解释了吧)。那么为什么会生成不同的哈希码值呢?上面我们在比较s1和s2的时候不是生成了同样的哈希码吗?原因就在于我们自己写的Student类并没有重新自己的hashcode()和equals()方法,所以在比较时,是继承的object类中的hashcode()方法,呵呵,各位还记得object类中的hashcode()方法比较的是什么吧!!
它是一个本地方法,比较的是对象的地址(引用地址),使用new方法创建对象,两次生成的当然是不同的对象了(这个大家都能理解吧。。。),造成的结果就是两个对象的hashcode()返回的值不一样。所以根据第一个准则,hashset会把它们当作不同的对象对待,自然也用不着第二个准则进行判定了。那么怎么解决这个问题呢??
答案是:在Student类中重新hashcode()和equals()方法。
例如:
class Student
{
int num;
String name;
Student(int num,String name)
{
this.num=num;
this.name=name;
}
public int hashCode()
{
return num*name.hashCode();
}
public boolean equals(Object o)
{
Student s=(Student)o;
return num==s.num && name.equals(s.name);
}
public String toString()
{
return num+":"+name;
}
}
根据重写的方法,即便两次调用了new Student(1,"zhangsan"),我们在获得对象的哈希码时,根据重写的方法hashcode(),获得的哈希码肯定是一样的(这一点应该没有疑问吧)。
当然根据equals()方法我们也可判断是相同的。所以在向hashset集合中添加时把它们当作重复元素看待了。所以运行修改后的程序时,我们会发现运行结果是:
1:zhangsan
3:wangwu
2:lisi
可以看到重复元素的问题已经消除。
关于在hibernate的pojo类中,重新equals()和hashcode()的问题:
1),重点是equals,重写hashCode只是技术要求(为了提高效率)
2),为什么要重写equals呢,因为在java的集合框架中,是通过equals来判断两个对象是否相等的
3),在hibernate中,经常使用set集合来保存相关对象,而set集合是不允许重复的。我们再来谈谈前面提到在向hashset集合中添加元素时,怎样判断对象是否相同的准则,前面说了两条,其实只要重写equals()这一条也可以。
但当hashset中元素比较多时,或者是重写的equals()方法比较复杂时,我们只用equals()方法进行比较判断,效率也会非常低,所以引入了hashcode()这个方法,只是为了提高效率,但是我觉得这是非常有必要的(所以我们在前面以两条准则来进行hashset的元素是否重复的判断)。
比如可以这样写:
public int hashCode(){
return 1;}//等价于hashcode无效
这样做的效果就是在比较哈希码的时候不能进行判断,因为每个对象返回的哈希码都是1,每次都必须要经过比较equals()方法后才能进行判断是否重复,这当然会引起效率的大大降低。
我有一个问题,如果像前面提到的在hashset中判断元素是否重复的必要方法是equals()方法(根据网上找到的观点),但是这里并没有涉及到关于哈希表的问题,可是这个集合却叫hashset,这是为什么??
我想,在hashmap,hashtable中的存储操作,依然遵守上面的准则。所以这里不再多说。这些是今天看书,网上查询资料,自己总结出来的,部分代码和语言是引述,但是千真万确是自己总结出来的。有错误之处和不详细不清楚的地方还请大家指出,我也是初学者,所以难免会有错误的地方,希望大家共同讨论。