1、多类分类
二分类器只能区分两个类别,多分类器则可以区分多余两个类别
一些算法(比如随机森林分类器或者朴素贝叶斯分类器)可以直接处理多分类问题,而其他的一些算法(比如SVM分类器或者线性分类器)择时严格的二分类器。当然也有许多策略让二分类器去执行多分类问题
"一对所有"(OvA)策略:创建一个将图片分为10类(0到9)的系统的一个方法:训练10个二分类器,每一个对应一个数字(探测器0,探测器1,探测器2,以此类推),然后当你想对某张图片进行分类的时候,让每一个分类器对这张图片进行分类,选出决策分数最高的那个分类器。
“一对一”(OvO)策略:对每一对数字都训练一个二分类器,一个分类器用来处理数字0和数字1,一个用来处理数字0和数字2,以此类推,如果有N个类,那么就需要N*(N-1)/2个分类器。让这张图片在这些分类器上都跑一遍,看哪个类胜出。OvO策略的主要优点是:每个分类器都只需要在训练集的部分数据上面进行训练。这部分数据是它所需要区分的那两个类对应的数据。
Sklearn可以探测出你想用一个二分类器去实现多分类的任务,他会自动执行OvA(除了SVM分类器,它使用OvO)。现在让试下SGDCLassifier
sgd_clf.fit(X_train,y_train)
sgd_clf.predict([some_digit])
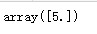
SGDClassifier分类器将对数字0~9产生10个探测器,在训练集上训练10个二分类器,每个分类器都产生这张图片的决策数值,选择数值最高的那个类。
为证明这一点,可以调用decision_function()方法,会返回10个数值,每个数值对一个一个类
some_digit_scores = sgd_clf.decision_function([some_digit])
some_digit_scores

最高值是对应类别5:
np.argmax(some_digit_scores)

一个分类器训练好之后,它会保存目标类别列表到属性classes_中去,按照值排序。在本例子当中,在 classes_ 数组当中的每个类的索引方便地匹配了类本身,比如,索引为 5 的类恰好是类别 5 本身。但通常不会这么幸运
sgd_clf.classes_

sgd_clf.classes_[5]

现在来看下如何强制Sklearn 使用OvO策略或者OvA策略。可以使用OneVsOneClassifier类或者OneVsRestClassifer类。创建一个样例,传递一个二分类器给他的构造函数。
from sklearn.multiclass import OneVsOneClassifier ovo_clf = OneVsOneClassifier(SGDClassifier(random_state = 42)) ovo_clf.fit(X_train,y_train) ovo_clf.predict([some_digit])

len(ovo_clf.estimators_)

可以看到OvO策略下对数字0~9分类会产生10*(10 -1 )/2 = 45个检测器
使用RandomForestClassifier分类器试试:
forest_clf.fit(X_train,y_train)
forest_clf.predict([some_digit])

由于RandomForestClassifier可以直接进行多分类,因此没必要去执行OvO或者OvA。可以调用predict_proba()可以得到样例对应的类别的概率值的列表
forest_clf.predict_proba([some_digit])

在数组的索引 5 上的 0.8,意味着这个模型以80% 的概率估算这张图片代表数字 5。它也认为这个图片可能是数字 0 或者数字 3,分别都是 10% 的几率。
现在使用交叉验证来对SGDCLassifier进行精度评估
cross_val_score(sgd_clf,X_train,y_train,cv = 3,scoring = 'accuracy')

在所有的测试者上,他有86%的精度。如何将精度提高到90%以上呢?
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) cross_val_score(sgd_clf,X_train_scaled,y_train,cv = 3,scoring = 'accuracy')

2、误差分析
使用混淆矩阵,首先要使用cross_val_predict进行预测,然后调用confusion_matrix()函数
y_train_pred = cross_val_predict(sgd_clf,X_train_scaled,y_train,cv = 3) conf_mx = confusion_matrix(y_train,y_train_pred) conf_mx

plt.matshow(conf_mx,cmap = plt.cm.gray)
plt.show()

关注下包含错误数据的图像呈现,首先需要将混淆矩阵的每一个值除以相应类别图片的总数目,并用0来填充对角线,这样就只保留了被错误分类的数据。
row_sums = conf_mx.sum(axis = 1,keepdims = True)
norm_conf_mx = conf_mx/row_sums
np.fill_diagonal(norm_conf_mx,0) plt.matshow(norm_conf_mx,cmap= plt.cm.gray) plt.show()