EP因子即市盈率因子,常被投资者使用的几个估值因子之一。一般使用PE,即Price to Earning,维基百科上的解释:市盈率指每股市价除以每股收益盈利(Earning Per Share,EPS),通常作为股票是便宜抑或昂贵的指标(通货膨胀会使每股收益虚增,从而扭曲市盈率的比较价值)。市盈率把企业的股价与其制造财富的能力联系起来。市盈率越低,代表投资者能够以相对低价格购入股票。
PE因子的计算
市盈率PE的定义:
未来函数:
公式系统对数据的运算是基于一系列函数,函数必须满足时序不变形,即时间靠后的数据不对时间靠前的数据产生影响(判断是否是未来函数的以及)。对未来函数也可以理解为:某一量依赖另一量,如量A和量B,B变化使A变化,那么A是B的函数,如果B是稍后的量,A是稍早的量,A跟着B变,A是B的未来函数(来自:百度百科)
因此为了防止未来函数,每股收益以公告日期为准
计算PE
# 计算市盈率:compute_pe
# 市盈率 = 股价/每股收益(EPS)
# 市盈率 = 市值 / 净利润
import os
from stock_util import get_all_codes
from database import DB_CONN
from pymongo import DESCENDING,UpdateOne
from tqdm import tqdm
finance_report_collection = DB_CONN['finance_report']
daliy_collection = DB_CONN['daily']
def compute_pe():
"""
计算股票在某只的市盈率
"""
#获取所有的股票列表
codes = get_all_codes()
print(codes )
#计算市盈率
for code in tqdm(codes):
print('计算市盈率,%s' %code)
daily_cursor = daliy_collection.find(
{'code':code},
projection={'date':True,'close':True})
update_requests = []
for daily in daily_cursor:
_date = daily['date']
#判断是否已经存在pe
pe_exists = daliy_collection.find(
{'code':code,'date':_date,'pe':{'$exists':True}}
)
if pe_exists:
continue
#找到该股票距离当前日期最近的年报,通过公告日期查询,防止未来函数
finance_report = finance_report_collection.find_one(
{'code':code,'report_date':{'$regex':'d{4}-12-31'},'annouced_date':{'$lte':_date}},
sort=[('annouced_date',DESCENDING)]
)
if finance_report is None:
continue
#计算滚动市盈率并保存到daily中
eps = 0
if finance_report['eps'] !='-':
eps = finance_report['eps']
#计算pe
if eps != 0:
update_requests.append(UpdateOne(
{'code':code,'date':_date},
{'$set':{'pe':round(daily['close']/eps,4)}}))
if len(update_requests)>0:
update_result = daliy_collection.bulk_write(update_requests,ordered=False)
print('更新PE,%s,更新:%d' %(code,update_result.modified_count))
if __name__ == "__main__":
compute_pe()
# os.system('shutdown -s -t 60')
将每只股票所计算得到的市盈率PE值,更新到daily数据库中,与此同时,通过tqdm库实现股票代码列表进度条可视化展示,判断之前是否计算过pe值,防止重复计算,减少无用功,并运行结果图:

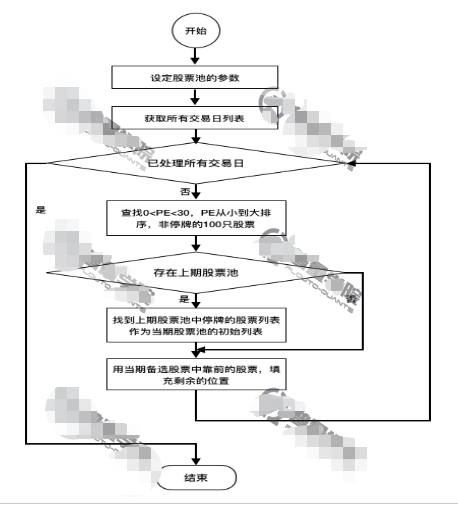
构建低PE股票池
条件
- 0< PE < 30
- PE从小到大排序,剔除停牌,取前100只
- 再平衡周期:7个交易日
流程图如下:
代码实现:
""""
实现股票池,条件0<PE<30,按照PE正序排列,最多取100只股票
再平衡周期为7个交易日
"""
from stock_util import get_trading_date
from database import DB_CONN
from pymongo import ASCENDING,DESCENDING
import pandas as pd
import matplotlib.pyplot as plt
daily = DB_CONN['daily']
daily_hfq = DB_CONN['daily_hfq']
def stock_pool(begin_date,end_date):
"""
股票池的选股逻辑
:param begin_date:开始日期
:param end_date:结束日期
:return:tuple:所有调整日,以及调整日和代码列表对应的dict
"""
"""
设置股票池参数
"""
#调整周期为7个交易日,可以改变参数
adjust_interval = 7
#PE的范围
pe_range = (0,30)
#PE 的排序方式,ASCENDING升序,DESCENDING降序
sort = ASCENDING
#股票池内的股票数量
pool_size = 100
#返回值:调整日和当前股票代码列表
adjust_date_codes_dict = dict()
#返回值:所有的调整日列表
all_adjust_dates = []
#获取所有交易日列表,获取指定时间范围内的所有交易日列表,按照日期正序排列
all_dates = get_trading_date(begin_date=begin_date,end_date=end_date)
#上一期的所有股票代码
last_phase_codes = []
#在调整日调整股票池
for _index in range(0,len(all_dates),adjust_interval):
print(_index)
#保存调整日
adjust_date = all_dates[_index]
all_adjust_dates.append(adjust_date)
print('调整日期:%s' % adjust_date,flush=True)
#查询出调整当日,0 < PE < 30,且非停牌的股票
#最重要的一点是:按照pe正序排列,只取前100只
daily_cursor = daily.find(
{'date':adjust_date,'pe':{'$lt':pe_range[1],'$gt':pe_range[0]},'is_trading':True},
sort=[('pe',sort)],
projection={'code':True},
limit=pool_size
)
#拿到所有的股票代码
codes = [x['code'] for x in daily_cursor]
print(adjust_date)
print(codes)
#本期股票列表
this_phase_codes =[]
#如果上期股票代码列表不为空,则查询出上次股票池中正在停牌的股票
##如果不是第一次设立的股票池,可以把股票池全部清掉,重新设立新的股票池,但如果有股票停牌了,需要保存
##也就是股票池中为何要将停牌股票存入股票池的初始化呢???大大的问号
if len(last_phase_codes)>0:
suspension_cursor = daily.find(
# 查询是股票代码、日期和是否为交易,这里is_trading=False
{'code':{'$in':last_phase_codes},'date':adjust_date,'is_trading':False},
#只需要股票代码
projection={'code':True}
)
#获得股票代码
suspension_codes = [x['code'] for x in suspension_cursor]
#保留股票池中正在停盘的股票
this_phase_codes = suspension_codes
#打印所有停盘的股票代码
print('上期停盘',flush=True)
print(this_phase_codes,flush=True)
#用新的股票将剩余位置补齐
this_phase_codes += codes[0:pool_size - len(this_phase_codes)]
#将本次股票设为下次运行时的上次股票
last_phase_codes = this_phase_codes
# print(last_phase_codes)
#建立该调整日和股票列表的对应关系
adjust_date_codes_dict[adjust_date]= this_phase_codes
print('最终出票',flush=True)
print(this_phase_codes,flush=True)
#返回结果
return all_adjust_dates,adjust_date_codes_dict
def find_out_stocks(last_phase_codes,this_phase_codes):
"""
找到上期入选,本期被调出的股票,这些股票必须卖出
:param last_phase_codes:上期股票列表
:param this_phase_codes:本期股票列表
:return :被调出的股票列表
"""
out_stocks = []
for code in last_phase_codes:
if code not in this_phase_codes:
out_stocks.append(code)
return out_stocks
def statistic_stock_pool():
"""
统计股票池的收益
"""
# 找到指定时间范围的股票池数据,这里的时间范围可以改变
adjust_dates,codes_dict = stock_pool('2019-01-02','2019-12-31')
print(codes_dict)
#用DataFrame保存收益,profit是股票池的收益,hs300是用来对比沪深300的涨跌幅
df_profit = pd.DataFrame(columns=['profit','hs300'])
#统计开始的第一天,股票池的收益和沪深300的涨跌幅都为0
df_profit.loc[adjust_dates[0]] = {'profit':0,'hs300':0}
#找到沪深300第一天的值,后面的累计涨跌幅都要和它比较
hs300_begin_value = daily.find_one({'code':'000300','index':True,'date':adjust_dates[0]})['close']
"""
通过净值的方式计算累计收益
累计收益 = 期末净值 - 1
第N期净值的计算方法:
net_value(n) = net_value(n-1) + net_value(n-1)*profit(n)
=net_value(n-1)*(1 + profit(n))
"""
#设定初始净值为1
net_value = 1
#在所有调整日上统计收益,循环时从1开始,因为每次计算要用到当期和上期
for _index in range(1,len(adjust_dates)-1):
print(_index)
#上一期的调整日
last_adjust_date = adjust_dates[_index-1]
#当前调整日
current_adjust_date = adjust_dates[_index]
#上一期的股票代码
codes = codes_dict[last_adjust_date]
print(codes)
#构建股票代码和后复权买入价格的股票
buy_daily_cursor = daily_hfq.find(
{'code':{'$in':codes},'date':last_adjust_date},
projection={'close':True,'code':True}
)
"""
>>>dict() # 创建空字典
{}
>>> dict(a='a', b='b', t='t') # 传入关键字
{'a': 'a', 'b': 'b', 't': 't'}
>>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典
{'three': 3, 'two': 2, 'one': 1}
>>> dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典
{'three': 3, 'two': 2, 'one': 1}
>>>
"""
#使用迭代对象方式来构造字典
code_buy_close_dict = dict([(buy_daily['code'],buy_daily['close'] )for buy_daily in buy_daily_cursor])
# 找到上期股票的在当前调整日时的收盘价
# 1、这里用的是后复权的价格,保持价格的连续性
# 2、当前的调整日,也就是上期的结束日
sell_daily_cursor = daily_hfq.find(
{'code':{'$in':codes},'date':current_adjust_date},
# 只需要用到收盘价来计算收益
projection={'code':True,'close':True}
)
#初始化所有股票的收益之和
profit_sum = 0
#参与收益统计的股票数量
count= 0
# 循环累加所有股票的收益
for sell_daily in sell_daily_cursor:
print(sell_daily)
# 股票代码
code = sell_daily['code']
#如果该股票存在股票池开始时的收盘价,则参与收益统计
if code in code_buy_close_dict:
#进入股票池的价格
buy_close = code_buy_close_dict[code]
#当前价格
sell_close = sell_daily['close']
# 累加所有股票的收益
profit_sum += (sell_close - buy_close) / buy_close
#参与收益计算的股票数加1
count+=1
#如果股票数量大于0,才统计当前收益
if count>0:
#计算平均收益
profit = round(profit_sum/count,4)
#当前沪深300的值
hs300_close = daily.find_one(
{'code':'000300','index':True,'date':current_adjust_date}
)['close']
print(current_adjust_date)
print(hs300_close)
#计算净值和累计收益,放到DataFrame中
net_value = net_value * (1 + profit)
df_profit.loc[current_adjust_date] = {
#乘100,改为百分比
'profit':round((net_value -1) * 100,4),
'hs300':round((hs300_close - hs300_begin_value)* 100 / hs300_begin_value,4)
}
print(df_profit)
#绘制曲线
df_profit.plot(title='Stock Pool Evaluation Result',kind='line')
plt.show()
#股票池入口函数
if __name__ == "__main__":
#统计股票池收益
statistic_stock_pool()
股票收益统计效果展示:
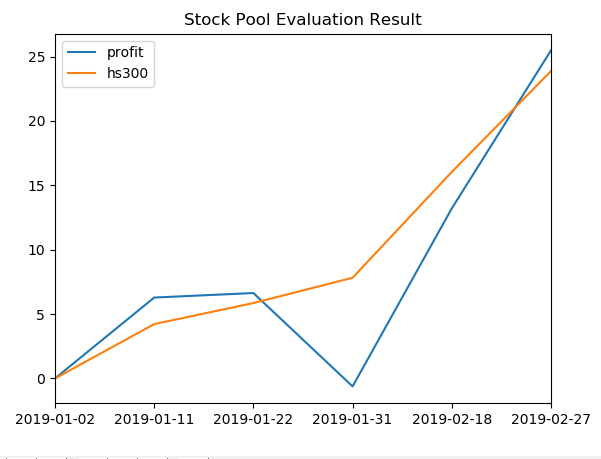
由于之前对数据字段'is_trading'等未全部添加,导致数据的不完整。
鉴于上,存在的几个疑问:
- 为何将上期股票池中的停牌股票列表作为当期股票池的初始列表???
那是因为股票池中的股票已经买入,第二天它停盘了,则需要保留,无法卖出
- “再平衡周期:7个交易日”,这个平衡周期作用是什么???
一个简单的理解,假如有一批闲置资金,50%投资了股票指数基金,50%投资了低风险固定收益产品,每隔固定一段时间(再平衡周期),对资产进行再平衡,使股票资产和固定资产的比例恢复到50%对50%.
拿本讲股票池为例,除上期股票列表中的停牌股票以外,需要全部更新新的股票列表为本期股票列表,换句话说,卖出除上期股票列表中的停牌股票以外的所有股票,再买入更新过后的股票。当然这只是非常简单的策略。这样做的优点:
- 再平衡可以提高实现资产长期回报率目标的概率。
- 再平衡有利于风险控制。
- 再平衡可以减少非理性交易。
缺点:
1、频繁操作容易带来很高的交易成本。
2、投资者很容易设定偏颇的资产配置比例。
3、遭遇单边行情。
4、许多投资者并不会真正理性地执行再平衡。
5、没有人真正知道该以什么样的频次做再平衡。
参考:再平衡的优缺点,再平衡周期对投资组合长期收益率影响大吗?——资产配置系列3
总结:
本股票池策略的逻辑:
根据PE指标按下列条件筛选出股票,并放入股票池中:
1、 0< PE < 30,并对筛选出来的股票按PE正序排序
2、 再平衡周期,更新股票池
此外,在统计股票池收益时,通过净值的方式计算累计收益,最后与沪深300收益进行比较