支持向量机(SVM)能够做线性或非线性的分类、回归,甚至异常值检测。SVM特别适合应用于复杂但中小规模数据集的分类问题。
线性支持向量机分类
依旧以鸢尾花数据集为例,如图,有两个种类能够被非常清晰的、非常容易的用一条直线分开(即线性可分的)。左边显示了三种可能的线性分类器的判定边界,其中虚线表示的线性模型判定边界不能正确的划分类别,虽说另外两个线性模型表现良好,但是他们的判定边界都很靠近样本点,在新的数据集上表现不一定好。右图为SVM分类器所判定的边界,不仅分开了两种类别,而且还尽可能地远离了最靠近的训练数据点。(SVM分类器在两种类别之间保持了一条尽可能宽的街道(如右图中平行虚线),被称为最大间隔分类)。
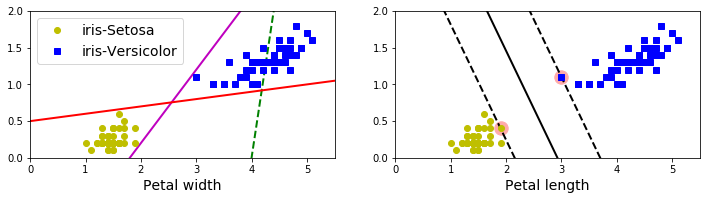
正如右图所示,添加更多的样本点在“街道”外不会影响到判定边界,这是因为判定边界是由位于“街道”边缘的样本点确定的,这些样本点被称为“支持向量”(如上右图圆圈圈起来的点)
代码展示:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn import datasets
from sklearn.pipeline import Pipeline
iris = datasets.load_iris()
X = iris['data'][:,(2,3)]#petal length,petal width
y = iris['target']
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
svm_clf = SVC(kernel='linear',C=float('inf'))
svm_clf.fit(X,y)
#Bad models
x0 = np.linspace(0,5.5,200)
pred_1 = 5 * x0 -20
pred_2 = x0 - 1.8
pred_3 = 0.1 * x0 + 0.5
#svm
def plot_svc_decision_boundary(svm_clf,xmin,xmax):
w = svm_clf.coef_[0]
b = svm_clf.intercept_[0]
#w0*x0 + w1 * x1 + b = 0
#==>x1 = -w0/w1 * x0 - b/w1
x0 = np.linspace(xmin,xmax,200)
decision_boundaray = -w[0] / w[1] * x0 - b/w[1]
margin = 1/w[1]
gutter_up = decision_boundaray + margin
gutter_down = decision_boundaray - margin
svs = svm_clf.support_vectors_
plt.scatter(svs[:,0],svs[:,1] ,s=180, facecolors='#FFAAAA')
plt.plot(x0,decision_boundaray,'k-',linewidth=2)
plt.plot(x0,gutter_up,'k--',linewidth=2)
plt.plot(x0,gutter_down,'k--',linewidth=2)
plt.figure(figsize=(12,2.7))
plt.subplot(121)
plt.plot(x0,pred_1,'g--',linewidth = 2)
plt.plot(x0,pred_2,'m-',linewidth = 2)
plt.plot(x0,pred_3,'r-',linewidth = 2)
plt.plot(X[:,0][y==0],X[:,1][y == 0],'yo',label='iris-Setosa')
plt.plot(X[:,0][y==1],X[:,1][y == 1],'bs',label='iris-Versicolor')
plt.axis([0,5.5,0,2])
plt.xlabel('Petal legth',fontsize=14)
plt.xlabel('Petal width',fontsize=14)
plt.legend(loc='upper left',fontsize=14)
plt.subplot(122)
plot_svc_decision_boundary(svm_clf, 0, 5.5)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.xlabel("Petal length", fontsize=14)
plt.axis([0, 5.5, 0, 2])
plt.show()
注意:
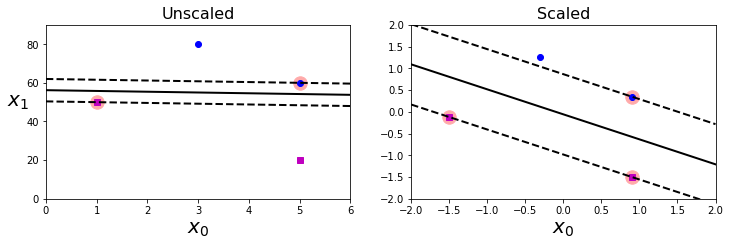
SVM对特征缩放比较敏感,如下图,左图中,垂直的比例要大于水平比例,所以更宽的‘街道’接近水平。但特征缩放后(如使用StandardScaler),判定边界好很多
软间隔分类
有软间隔,那必然有硬间隔。
硬间隔
严格的将所有数据都不在“街道”上,都正确的分布在两边,称为硬间隔
硬间隔分类有两个问题
- 只对线性可分的数据起作用
- 对异常点敏感
下图,显示只有一个异常点的鸢尾花数据集,左边的图很难找到硬间隔,右边的图中判定边界和上图没有异常点的判定边界非常不一样,很难一般化

软间隔
为了避免上述的问题,因此,更加倾向于使用更加软性的模型。
目的在于保持“街道”尽可能大和避免间隔违规(如:数据点出现在“街道”中央甚至在错误的一遍)之间找到一个良好的平衡,这就是软间隔分类
在Scikit_Learn库中的SVM类,可以使用C超参数(惩罚系数)来控制这种平衡:较小的C会导致更宽的“街道”,但更多的间隔违规。
在非线性可分隔的数据集上,使用两个不同的C,软间隔SVM分类器的判定边界的不同
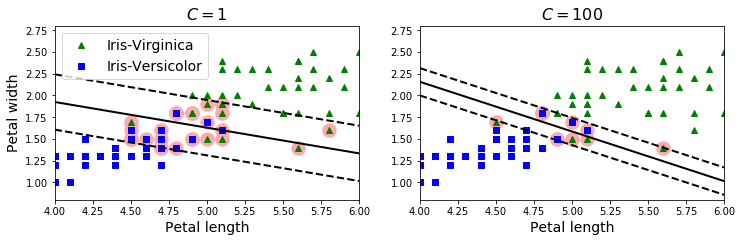
左边的图使用了较小的C值,导致间隔变大,但有许多数据点出现在“街道”上;右边的图使用了较大的C值,导致较少的间隔违规,但同时间隔较小。各有优缺点,但对于泛化能力来说,左边图的分类器会更好一点:在这个训练数据集上减少了预测错误,因为实际上大部分的间隔违规点出现在了判定边界正确的一侧。
使用Scikit_Learn代码加载内置的鸢尾花(iris)数据集,特征缩放,并训练一个线性SVM模型(使用LinearSVC类,超参数C= 1,hinge损失函数)来检测VIrginica鸢尾花,生成的模型如上左图。
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris['data'][:,(2,3)] # petal length, petal width
y = (iris['target'] == 2).astype(np.float64)#virginica
svm_clf = Pipeline([
('scaler',StandardScaler()),
('linear_svc',LinearSVC(C=1,loss='hinge',random_state=42))
])
svm_clf.fit(X,y)
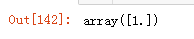
svm_clf.predict([[5.5,1.7]])
注:
可以使用SVC类,实现上述功能(使用SVC(kernel='linear',C=1)),但它比较慢,尤其在较大数据集上,一般不推荐。