极客时间:《从 0 开始学架构》:高性能数据库集群:分库分表
1、引言
上节讲到了数据库的读写分离,但读写分离仅分散了读写操作的压力,但没有分散存储的压力,当数据量达到成千上万条时,单台数据库服务器的存储能力就会称为系统的瓶颈。主要体现在以下几个方面:
- 数据量太大,读写的性能会下降,即使有索引,索引也会变得很大,性能同样会下降。
- 数据文件会变得很大,数据库备份和恢复需要耗费很长时间。
- 数据文件越大,极端情况下丢失数据的风险越高(例如,机房火灾导致数据库主备机都发生故障)。
基于以上原因,导致单个数据库服务器存储的数据量不能太大,需要控制在一定的范围内。但为满足业务数据存储的需求,就要考虑将存储分散到多台数据库服务器上。
常见的分散存储的方法“分库分表”,其中包括“分库”和“分表”
2、业务分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。,即将不同模块或类型的数据分散到不同数据库服务器上,类似于这样的:
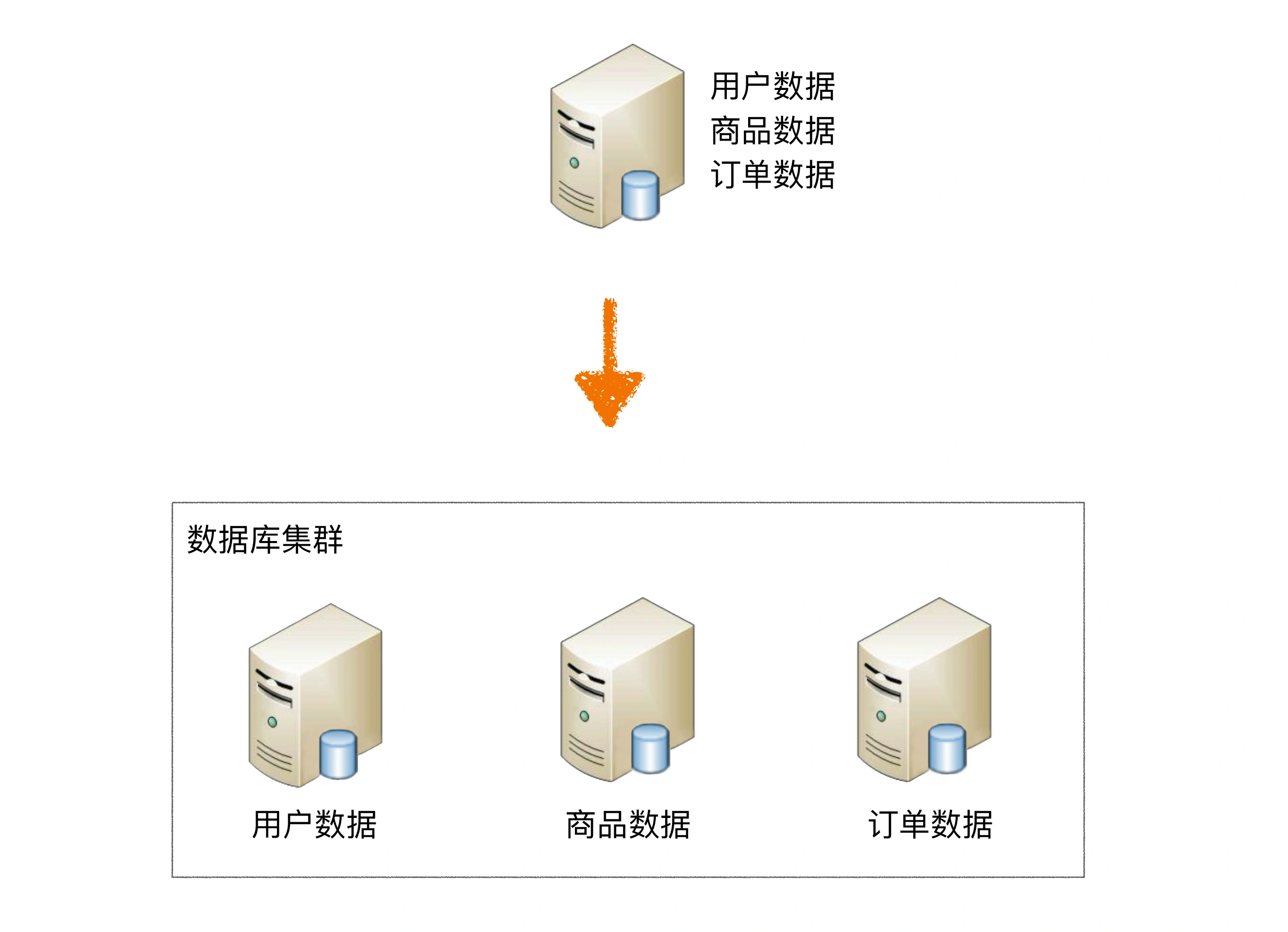
虽然业务分库能够分散存储和访问压力,但也带来了其他问题:
- 1、join操作问题
业务分库后,原本在同一个数据库中的表分散到了多个数据库中,导致无法使用SQL的join查询
- 2、事务问题
原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同的数据库中,无法通过事务统一修改。虽然数据库厂商提供了一些分布式事务的解决方案(例如,MySQL 的 XA),但性能实在太低,与高性能存储的目标是相违背的。
- 3、成本问题
原因很简单,业务分库本来原来1台服务器能搞定的事,现在需要三台,如果需要考虑备份,2台变成了6台
Tips:
不建议小公司初创业务,就开始这样拆分,除了成本的因素外,业务初创期间最终的是快速实现,快速验证,业务分库会拖慢业务节奏;初创业务存在很大的不确定性;表之间的join查询操作、数据库事务无法简单实现
一定在架构设计过程中,遵循“架构设计三原则”:“简单原则”、“适合原则”、“演化原则”,先活下下去,再谋发展
3、分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。此时就要对单表进行拆分。
单表数据拆分有两种方式:垂直分表和水平分表,示意图如下:
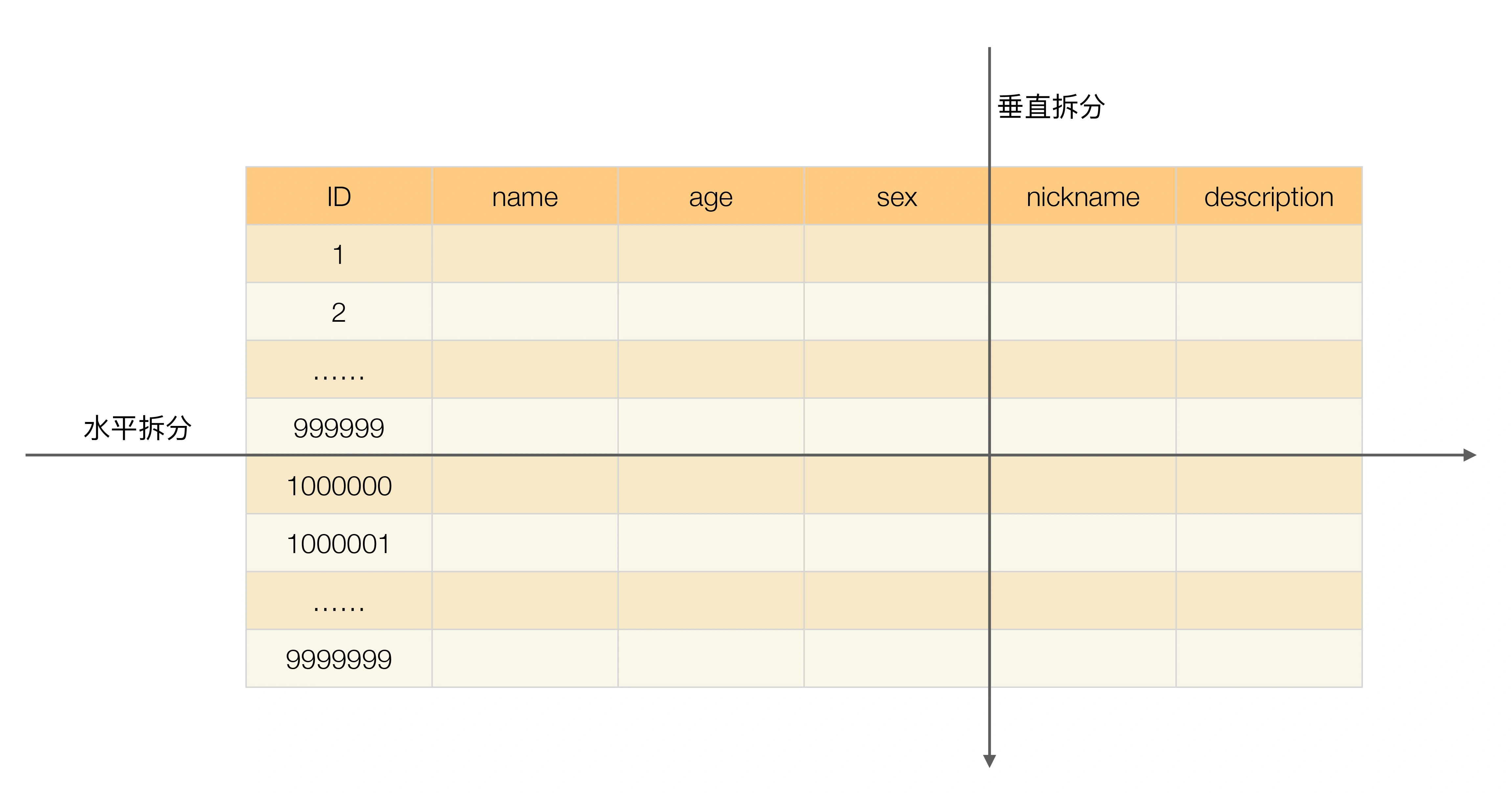
- 从上往下切就是垂直切分,示意图中的垂直切分,会把表切分为两个表,一个表包含 ID、name、age、sex 列,另外一个表包含 ID、nickname、description 列。
- 从左往右切就是水平切分,示意图中的水平切分,会把表分为两个表,两个表都包含 ID、name、age、sex、nickname、description 列,但是一个表包含的是 ID 从 1 到 999999 的行数据,另一个表包含的是 ID 从 1000000 到 9999999 的行数据。
分表能够有效地分散存储压力和带来性能提升,但和分库一样,也会引入各种复杂性。
- 1、垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
垂直分表引入的复杂性主要体现在表操作的数量要增加。原本可以一次性查询就可以的,现在需要两次查询才行
- 2、水平分表
水平分表适合表行数特别大的表
水平分表相比垂直分表,会引入更多的复杂性,主要表现在下面几个方面:
- 路由
水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算,这个算法会引入一定的复杂性。
PS:
常见的路由算法:
- 范围路由
定义:选取有序的数据列(例如,整形、时间戳等)作为路由的条件,不同分段分散到不同的数据库表中。以最常见的用户 ID 为例,路由算法可以按照 1000000 的范围大小进行分段,1 ~ 999999 放到数据库 1 的表中,1000000 ~ 1999999 放到数据库 2 的表中,以此类推。
复杂点:范围路由设计的复杂点主要体现在分段大小的选取上,分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
缺点:分布不均匀,假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1000 条,而另外一个分段实际存储的数据量有 900 万条。- Hash路由
定义:选取某个列(或者某几个列组合也可以)的值进行 Hash 运算,然后根据 Hash 结果分散到不同的数据库表中。同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,路由算法可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的字表中。
复杂点:Hash 路由设计的复杂点主要体现在初始表数量的选取上,表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。而用了 Hash 路由后,增加子表数量是非常麻烦的,所有数据都要重分布。
优点:表分布比较均匀
缺点:扩充新的表很麻烦,所有数据都要重分布
*配置路由
定义:配置路由就是路由表,用一张独立的表来记录路由信息。同样以用户 ID 为例,我们新增一张 user_router 表,这个表包含 user_id 和 table_id 两列,根据 user_id 就可以查询对应的 table_id。
复杂点:配置路由设计简单,使用起来非常灵活,尤其是在扩充表的时候,只需要迁移指定的数据,然后修改路由表就可以了。
缺点:必须多查询一次,会影响整体性能;而且路由表本身如果太大(例如,几亿条数据),性能同样可能成为瓶颈,如果我们再次将路由表分库分表,则又面临一个死循环式的路由算法选择问题。
- join 操作
水平分表后,数据分散在多个表中,如果需要与其他表进行 join 查询,需要在业务代码或者数据库中间件中进行多次 join 查询,然后将结果合并。
- count() 操作
水平分表后,虽然物理上数据分散到多个表中,但某些业务逻辑上还是会将这些表当作一个表来处理。常见的处理方式有下面两种:
count()相加:具体做法是在业务代码或者数据库中间件中对每个表进行 count() 操作,然后将结果相加。这种方式实现简单,缺点就是性能比较低。
记录数表:具体做法是新建一张表,假如表名为“记录数表”,包含 table_name、row_count 两个字段,每次插入或者删除子表数据成功后,都更新“记录数表”。优点:性能远大于count()x相加的方式,只需要进行简单的查询操作就可获取数据。缺点:复杂度增加不少,对子表的操作要同步操作“记录数表”,如果有一个业务逻辑遗漏了,数据就会不一致;且针对“记录数表”的操作和针对子表的操作无法放在同一事务中进行处理,异常的情况下会出现操作子表成功了而操作记录数表失败,同样会导致数据不一致。
- order by 操作
水平分表后,数据分散到多个子表中,排序操作无法在数据库中完成,只能由业务代码或者数据库中间件分别查询每个子表中的数据,然后汇总进行排序。
实现方法:
分库分表具体的实现方式也是“程序代码封装”和“中间件封装”,但实现会更复杂。读写分离实现时只要识别 SQL 操作是读操作还是写操作,通过简单的判断 SELECT、UPDATE、INSERT、DELETE 几个关键字就可以做到,而分库分表的实现除了要判断操作类型外,还要判断 SQL 中具体需要操作的表、操作函数(例如 count 函数)、order by、group by 操作等,然后再根据不同的操作进行不同的处理。例如 order by 操作,需要先从多个库查询到各个库的数据,然后再重新 order by 才能得到最终的结果。
PS:哪何时考虑进行分库分表呢?
1.做硬件优化,例如从机械硬盘改成使用固态硬盘,当然固态硬盘不适合服务器使用,只是举个例子
2.先做数据库服务器的调优操作,例如增加索引,oracle有很多的参数调整;
3.引入缓存技术,例如Redis,减少数据库压力
4.程序与数据库表优化,重构,例如根据业务逻辑对程序逻辑做优化,减少不必要的查询;
5.在这些操作都不能大幅度优化性能的情况下,不能满足将来的发展,再考虑分库分表,也要有预估性