爬取商品信息并写入数据库操作
本次爬取当当网图书程序设计类书籍,爬取信息包括书名、链接和评论,并写入mysql。
1、首先修改items.py

title存储书名、link存储商品链接、comment存储评论数
2、其次修改dd.py
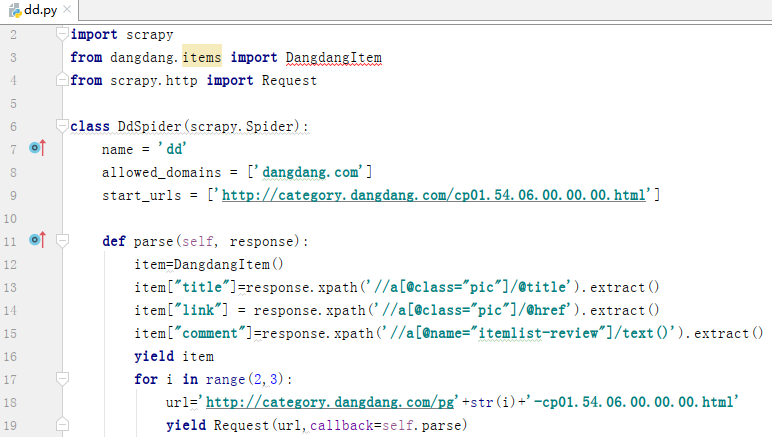
首先要用xpath提取商品的信息,其次还需要构造程序设计类书籍每一页的链接。通过分析网页的组成,构造下一页的网页来提取更多的商品信息,如上图循环url所示。

需要提取上图三个红框中的内容,就需要设置xpath提取式。第一个红框是书名,设置xpath为:‘//a[@class="pic"]/@title’,‘//a’表示在所有的a标签下,但是在a标签下有很多内容,提取到我们需要的内容就需要设置相应的表达式,此时发现当搜索‘class="pic"’这个条件时,可以检索出60个关键词,而刚好每一页都有60个商品,那么我们可以通过设置满足‘class="pic"’,来提取所有的书名。同理,可以得出商品链接和评论数的xpath。
3、设置pipelines.py

在mysql中新建了一个名叫dd的数据库,表名为goods,表中tile、link和comment都设置为char类型。通过import pymysql连接数据库,将爬取到的数据写入到数据库中。通过mysql的操作查看爬取到的内容: