| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 尝试用软件工程的思想编写一个小型应用软件 |
| 学号 | 031802129 |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 360 | 440 |
| Design Spec | 生成设计文档 | 30 | 25 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 80 | 90 |
| Coding | 具体编码 | 200 | 420 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 60 | 40 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 975 | 1355 |
解题思路
前期准备
刚拿到的题目的时候愣了一下,因为以前从来没有做过类似大数据处理的相关练习,所以没有什么思路,想了想打算使用 Python 来进行编写。所以打算先做规划,列出需要学习的各个项目,并画出了思维导图如下

然后便开始了现学现卖的过程————先用了一个晚上的时间仔细的把网上的 Python 菜鸟教程看了一遍,接下来断断续续的看了 json 的菜鸟教程,然后又抽出了一部分时间去 CSDN 找了一个小白 git 教程,跟着他一步一步将本地仓库与我的远程仓库进行了链接,算是完成了前期的准备工作了。
解题规划
接下来我开始阅读助教提供的实例代码,由于是速成的 Python ,所以阅读起来仍然有点困难,经常上网去搜索某一行代码然后一行行打注释,问同学,大概对示例代码的结构有了大致的了解,本题可以用一下几个步骤来解决。

接着我又看了一下题目,发现数据最高能达到10g,然后经过舍友提醒发现 git action 能分配8g内存以及双核处理器,所以如果将 10g 的数据全部导入内存可能会导致爆内存,所以感觉应该加上数据清洗的步骤,筛选出部分再进行下一步处理。

设计过程
阅读实例代码
首先我又仔细研究了一下助教的代码,决定以此为基础进行相应的修改以及优化。
主要功能
我将我认为实例代码的主要功能如下
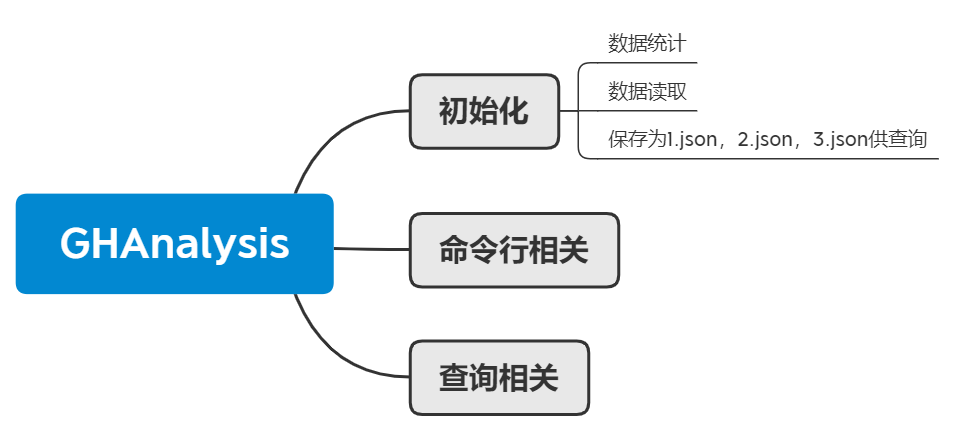
我认为可以在数据的读取以及查询相关的组件进行优化与改进。
优化
我认为可以在以下几点进行优化
- 利用多进程进行数据清洗
- 利用字典树组织数据进行查询
- 利用 SQLite 库组织数据用于查询
- 使用 Python 的 pandas 库组织数据进行查询
所以得到了以下的大致的解题过程

有了大致框架,接下来就是码码码了
代码说明
多进程读取
for root, dic, files in os.walk(dict_address): #os.walk用来遍历一个目录内各个子目录和子文件
pool = multiprocessing.Pool(processes=8) #开辟进程池
for f in files: #遍历整个文件夹的文件
#self.write1(f,dict_address)
pool.apply_async(self.write1,args=(f,dict_address)) #多进程调用查找函数
pool.close()
pool.join()
for root, dic, files in os.walk(dict_address):
for f in files: # 找格式文件
if f[-5:] == '.json':
x = open('json_save\' + f,
'r', encoding='utf-8').read()
x= json.loads(x)
self.count(x)
localtime = time.asctime( time.localtime(time.time()) )
print(localtime)
with open('1.json', 'w', encoding='utf-8') as f: #打开,并写入
json.dump(self.__4Events4PerP,f)
with open('2.json', 'w', encoding='utf-8') as f: #打开,并写入
json.dump(self.__4Events4PerR,f)
with open('3.json', 'w', encoding='utf-8') as f: #打开,并别入
json.dump(self.__4Events4PerPPerR,f)
以下为 write1 函数以及与其配套的 save 函数
write1函数:
def write1(self,f,dict_address): #用来多进程读入
#print("writing....")
#print(os.getppid())
json_list=[]
if f[-5:] == '.json': #如果文件的后缀为.json
json_path = f #json_path记录下文件的地址
x = open(dict_address + '\' + json_path, 'r', encoding='utf-8')
with mmap.mmap(x.fileno(), 0, access=mmap.ACCESS_READ) as m:
m.seek(0, 0)
obj = m.read()
obj = str(obj, encoding="utf-8")
str_list = [_x for _x in obj.split('
') if len(_x) > 0]
for i, _str in enumerate(str_list):
try:
json_list.append(json.loads(_str))
except:
pass
self.save(json_list,f)
save函数:
def save(self,json_list,f1):
print("saving...")
print(os.getppid())
record = self.__listOfNestedDict2ListOfDict(json_list)
k=[]
for i in record:
k.append({'actor__login':i['actor__login'],'type':i['type'],'repo__name':i['repo__name']})
with open('json_save\'+f1, 'w', encoding='utf-8') as f: # 初始化
json.dump(k, f)
我的参考了我的大佬舍友的思路,我使用了一个总共为 15g 数据文件进行测试,使用multiprocessing开了8个进程,用来分别读取数据数据并进行清洗,只留下actor__login,type,repo__name这三个数据,然后保存到另外一个文件夹中,此时保存下来的数据是已经经过清洗后的数据了,数据大小已经大幅减少,接下来就只需要分别将他们组织到1.json,2.json,3.json三个文件中去即可
从清洗后的数据中读出所需数据并进行组织:
for root, dic, files in os.walk(dict_address):
for f in files: # 找格式文件
if f[-5:] == '.json':
x = open('json_save\' + f,
'r', encoding='utf-8').read()
x= json.loads(x)
self.count(x)
localtime = time.asctime( time.localtime(time.time()) )
print(localtime)
with open('1.json', 'w', encoding='utf-8') as f: #打开,并写入
json.dump(self.__4Events4PerP,f)
with open('2.json', 'w', encoding='utf-8') as f: #打开,并写入
json.dump(self.__4Events4PerR,f)
with open('3.json', 'w', encoding='utf-8') as f: #打开,并别入
json.dump(self.__4Events4PerPPerR,f)
以下为*** count 函数***,用来进行统计:
def count(self,records):
#print("counting...")
#print(os.getppid())
for i in records:
if not self.__4Events4PerP.get(i['actor__login'], 0): #每个人四个事件的数量
self.__4Events4PerP.update({i['actor__login']: {}})
self.__4Events4PerPPerR.update({i['actor__login']: {}})
self.__4Events4PerP[i['actor__login']][i['type']
] = self.__4Events4PerP[i['actor__login']].get(i['type'], 0)+1
if not self.__4Events4PerR.get(i['repo__name'], 0): #每个项目四个事件的数量
self.__4Events4PerR.update({i['repo__name']: {}})
self.__4Events4PerR[i['repo__name']][i['type']
] = self.__4Events4PerR[i['repo__name']].get(i['type'], 0)+1
if not self.__4Events4PerPPerR[i['actor__login']].get(i['repo__name'], 0): #每个人在每个项目
self.__4Events4PerPPerR[i['actor__login']].update({i['repo__name']: {}})
self.__4Events4PerPPerR[i['actor__login']][i['repo__name']][i['type']
] = self.__4Events4PerPPerR[i['actor__login']][i['repo__name']].get(i['type'], 0)+1
单元测试覆盖率
上网查找了以下如何对 Python 程序进行单元测试覆盖率测试,发现了一个叫做 coverage 的第三方库,经过了大致的了解,发现好像不会很难,看了几篇文章感觉可以上手了。
编写测试文件
import GHAnalysis
import unittest
class manitest(unittest.TestCase):
def test_init(self):
x=cs.Data("test",1)
def test_find(self):
x=cs.Data("test",1)
x.getEventsUsers("whq","PushEvent")
x.getEventsRepos("jkl","PushEvent")
x.getEventsUsersAndRepos("jkl","fds","PushEvent")
if __name__ == '__main__':
unittest.main(verbosity=2)
定义了两个函数,第一个函数用来测试初始化,第二个函数用来测试里面的三个查找函数。
进行测试
第一次测试发现覆盖率很低,检查发现没有进入到多进程运行的函数中,接下来我将多进程的调用删去,覆盖率明显提高。
使用多进程
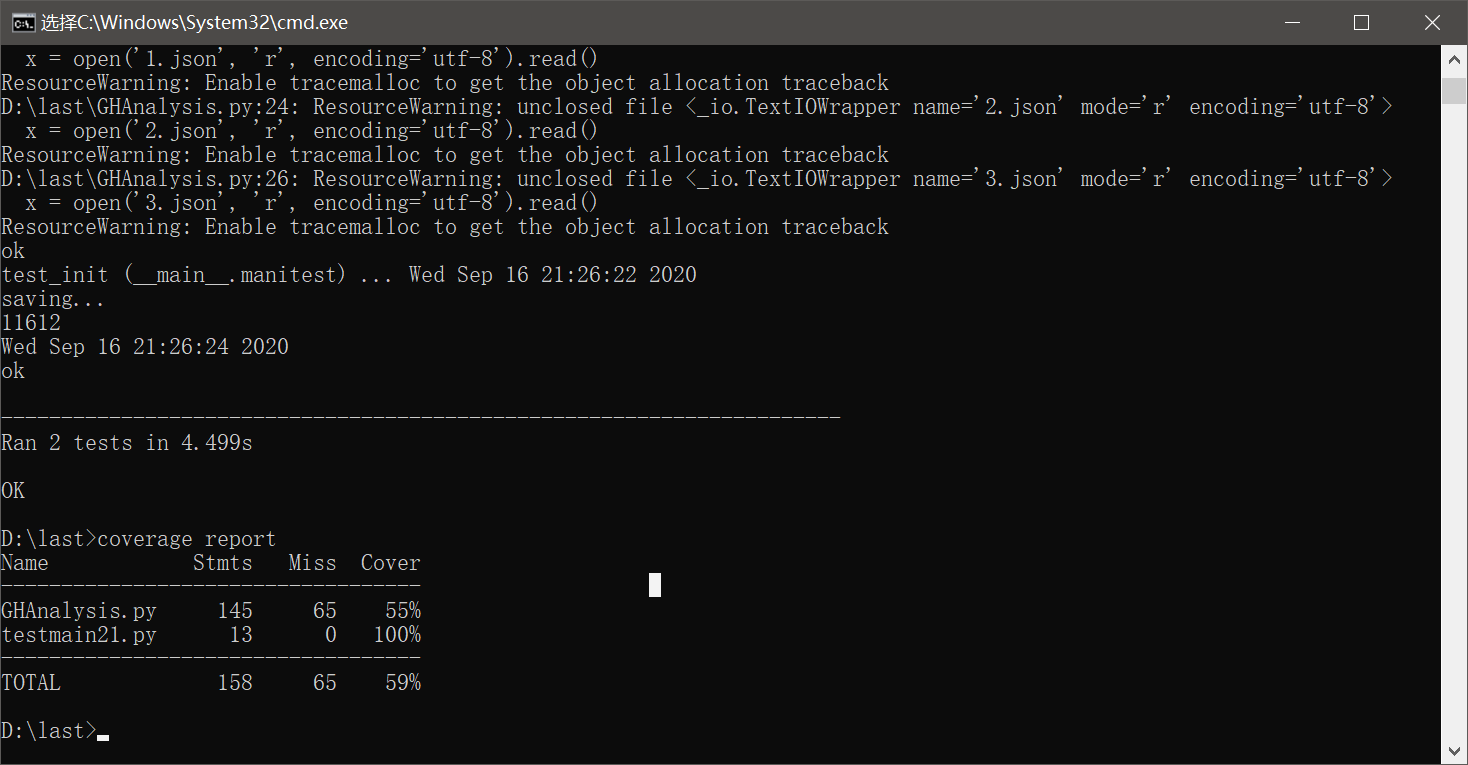
注释掉多进程
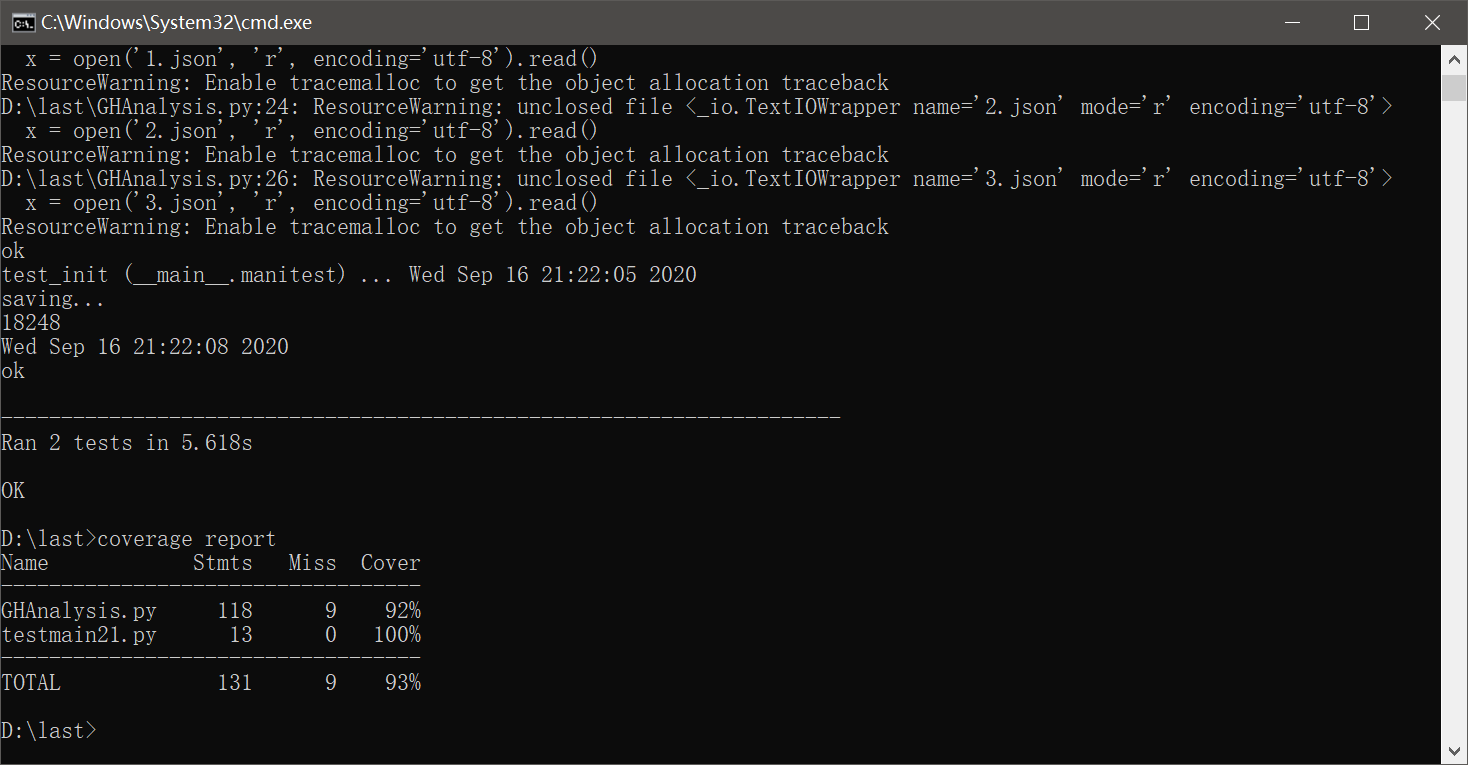
性能优化
优化初始化工作
原本使用单进程进行初始化操作,15g数据总共使用了23分钟才结束
使用多进程进行操作,15g数据总共用了5分钟左右
开始时间:
结束时间: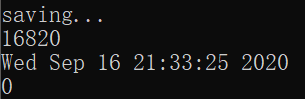
优化查询工作
啊,我看了半天的SQLite还是没整明白iai,然后由于时间原因 pandas 也没去看了,也想不明白怎么把他组织到字典树上去。。。
所以优化查询没有进行iai
代码规范
https://github.com/aoli-gei/2020-personal-python/blob/master/codestyle.md
总结
收获
- 初步学习了 git 指令,学会了软件的版本管理相关知识。
- 学习了如何读取 json 文件,并对其数据进行整理与保存
- 学习了 Python 的基础语法,以及编写 Python 程序的方法
- 大概了解了软件工程的过程,为后来的大作业做准备
困难
- 在使用 git 的时候,原本想上传一个大于100M的数据到 github 上,安装了 LFS 结果出了问题无法 push 上去,只好将 fork 下来的仓库删掉。
- 刚开始的时候,json 转换为字典不大会用,一直出错。
- 没有学习 Python 命令行的相关操作,直接使用了助教的实例代码中的组件。
- 不知道多进程不能同时修改一个变量,写了一半经过舍友提醒全部重来。
规划
- 仔细系统的学习 Python 语法。
- 学习 SQLite 的使用方法
- 多看相关开发文章,提升自己的开发思维