使用python实现AI机器人聊天工具其实还是蛮简单的,大致原理如下:
1、使用python的SpeechRecognition模块进行语音录音,代码如下:
1 import speech_recognition as sr 2 # Use SpeechRecognition to record 使用语音识别包录制音频 3 def my_record(rate=16000): 4 r = sr.Recognizer() 5 with sr.Microphone(sample_rate=rate) as source: 6 print("请讲话(正在倾听中......):") 7 audio = r.listen(source) 8 print("回答思考中.....") 9 with open("temp.wav", "wb") as f: 10 f.write(audio.get_wav_data())
2、使用百度的AI开发平台进行语音识别,具体教程可百度,地址:https://console.bce.baidu.com/ai/_=1602817929103&fromai=1#/ai/speech/overview/index
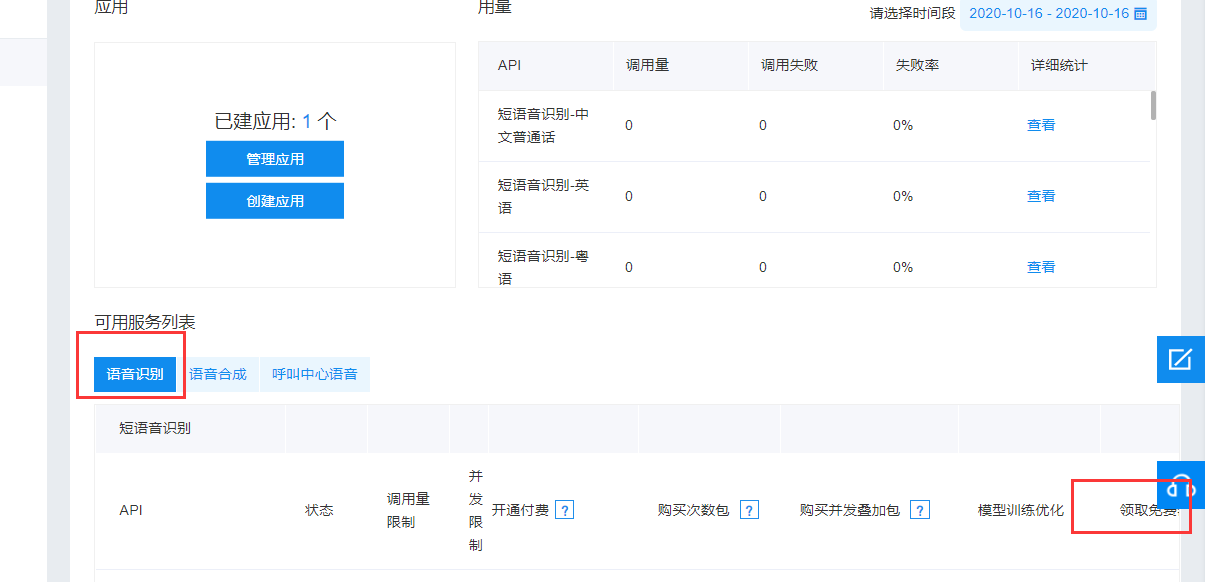
需要注册一个应用,千万要记住,一定要点击免费领取,不然调用的时候会报错。
python使用百度AI智能平台的代码如下(将之前录音好的文件传输给API平台,返回识别后的文本):
1 APP_ID = "22817840" #百度应用的APP_ID 2 API_KEY ="ndQCCddCNisGHe87G5agXsGm" #key 3 SECRET_KEY = "o0pLLR6DIPEnBXtOvpWXK3QxruFn1G3N" #secret_key 4 client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) 5 path = 'temp.wav' 6 # 将语音转文本STT 7 def listen(): 8 # 读取录音文件 9 with open(path, 'rb') as fp: 10 voices = fp.read() 11 try: 12 # 参数dev_pid:1536普通话(支持简单的英文识别)、1537普通话(纯中文识别)、1737英语、1637粤语、1837四川话、1936普通话远场 13 result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, }) 14 # print(result) 15 result_text = result["result"][0] 16 print("you said: " + result_text) 17 return result_text 18 except KeyError: 19 print("KeyError")
3、将文本内容发送给图灵机器人平台,进行对话,图灵机器人平台会返回对话的文本,如何使用图灵机器人,请百度,地址:http://www.tuling123.com/member/robot/2304329/center/frame.jhtml?page=1&child=0
对应的python代码如下:
1 # 图灵机器人的API_KEY、API_URL 2 turing_api_key = "your turing_api_key" 3 api_url = "http://openapi.tuling123.com/openapi/api/v2" # 图灵机器人api网址 4 headers = {'Content-Type': 'application/json;charset=UTF-8'} 5 6 7 # 图灵机器人回复 8 def Turing(text_words=""): 9 req = { 10 "reqType": 0, 11 "perception": { 12 "inputText": { 13 "text": text_words 14 }, 15 16 "selfInfo": { 17 "location": { 18 "city": "北京", 19 "province": "北京", 20 "street": "车公庄西大街" 21 } 22 } 23 }, 24 "userInfo": { 25 "apiKey": "c81a2d3f03c6400f968787653fa42f68", # 你的图灵机器人apiKey 26 "userId": "Nieson" # 用户唯一标识(随便填, 非密钥) 27 } 28 } 29 req["perception"]["inputText"]["text"] = text_words 30 response = requests.request("post", api_url, json=req, headers=headers) 31 response_dict = json.loads(response.text) 32 33 result = response_dict["results"][0]["values"]["text"] 34 35 return result
4、将图灵机器人返回的文本转行为语音然后通过python的playsound模块播放出来,python自带的pyttsx3模块可以轻松实现,但是效果不好,这里我使用的阿里智能平台,当然也可以用百度的,主要是阿里的语音种类多一点。具体的python的代码如下:
1 class AccessToken: 2 @staticmethod 3 def _encode_text(text): 4 encoded_text = parse.quote_plus(text) 5 return encoded_text.replace('+', '%20').replace('*', '%2A').replace('%7E', '~') 6 @staticmethod 7 def _encode_dict(dic): 8 keys = dic.keys() 9 dic_sorted = [(key, dic[key]) for key in sorted(keys)] 10 encoded_text = parse.urlencode(dic_sorted) 11 return encoded_text.replace('+', '%20').replace('*', '%2A').replace('%7E', '~') 12 @staticmethod 13 def create_token(access_key_id, access_key_secret): 14 parameters = {'AccessKeyId': access_key_id, 15 'Action': 'CreateToken', 16 'Format': 'JSON', 17 'RegionId': 'cn-shanghai', 18 'SignatureMethod': 'HMAC-SHA1', 19 'SignatureNonce': str(uuid.uuid1()), 20 'SignatureVersion': '1.0', 21 'Timestamp': time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime()), 22 'Version': '2019-02-28'} 23 # 构造规范化的请求字符串 24 query_string = AccessToken._encode_dict(parameters) 25 # print('规范化的请求字符串: %s' % query_string) 26 # 构造待签名字符串 27 string_to_sign = 'GET' + '&' + AccessToken._encode_text('/') + '&' + AccessToken._encode_text(query_string) 28 # print('待签名的字符串: %s' % string_to_sign) 29 # 计算签名 30 secreted_string = hmac.new(bytes(access_key_secret + '&', encoding='utf-8'), 31 bytes(string_to_sign, encoding='utf-8'), 32 hashlib.sha1).digest() 33 signature = base64.b64encode(secreted_string) 34 # print('签名: %s' % signature) 35 # 进行URL编码 36 signature = AccessToken._encode_text(signature) 37 # print('URL编码后的签名: %s' % signature) 38 # 调用服务 39 full_url = 'http://nls-meta.cn-shanghai.aliyuncs.com/?Signature=%s&%s' % (signature, query_string) 40 # print('url: %s' % full_url) 41 # 提交HTTP GET请求 42 response = requests.get(full_url) 43 if response.ok: 44 root_obj = response.json() 45 key = 'Token' 46 if key in root_obj: 47 token = root_obj[key]['Id'] 48 expire_time = root_obj[key]['ExpireTime'] 49 return token, expire_time 50 return None, None 51 52 def processPOSTRequest(appKey, token, text, audioSaveFile, format, sampleRate) : 53 host = 'nls-gateway.cn-shanghai.aliyuncs.com' 54 url = 'https://' + host + '/stream/v1/tts' 55 # 设置HTTPS Headers。 56 httpHeaders = { 57 'Content-Type': 'application/json' 58 } 59 # 设置HTTPS Body。 60 body = {'appkey': appKey, 'token': token, 'text': text, 'format': format, 'sample_rate': sampleRate} 61 body = json.dumps(body) 62 # print('The POST request body content: ' + body) 63 conn = http.client.HTTPSConnection(host) 64 conn.request(method='POST', url=url, body=body, headers=httpHeaders) 65 # 处理服务端返回的响应。 66 response = conn.getresponse() 67 68 69 contentType = response.getheader('Content-Type') 70 71 body = response.read() 72 if 'audio/mpeg' == contentType : 73 with open(audioSaveFile, mode='wb') as f: 74 f.write(body) 75 else : 76 print('The POST request failed: ' + str(body)) 77 conn.close() 78 79 def textConverToVidio(appKey,token,text,audioSaveFile): 80 # with open(file,"r",encoding="utf-8") as f: 81 # text = f.read() 82 textUrlencode = text 83 textUrlencode = urllib.parse.quote_plus(textUrlencode) 84 textUrlencode = textUrlencode.replace("+", "%20") 85 textUrlencode = textUrlencode.replace("*", "%2A") 86 textUrlencode = textUrlencode.replace("%7E", "~") 87 # print('text: ' + textUrlencode) 88 format = 'mp3' 89 sampleRate = 16000 90 processPOSTRequest(appKey, token, text, audioSaveFile, format, sampleRate)
最终就完成了一个简单的机器人对话,由于时间仓促,代码没有优化,全部代码如下:


import os import speech_recognition as sr from aip import AipSpeech import http.client import urllib.parse import json import base64 import hashlib import hmac import requests import time import uuid from urllib import parse from playsound import playsound # Use SpeechRecognition to record 使用语音识别包录制音频 def my_record(rate=16000): r = sr.Recognizer() with sr.Microphone(sample_rate=rate) as source: print("请讲话(正在倾听中......):") audio = r.listen(source) print("回答思考中.....") with open("temp.wav", "wb") as f: f.write(audio.get_wav_data()) APP_ID = "22817840" API_KEY ="ndQCCddCNisGHe87G5agXsGm" SECRET_KEY = "o0pLLR6DIPEnBXtOvpWXK3QxruFn1G3N" client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) path = 'temp.wav' # 将语音转文本STT def listen(): # 读取录音文件 with open(path, 'rb') as fp: voices = fp.read() try: # 参数dev_pid:1536普通话(支持简单的英文识别)、1537普通话(纯中文识别)、1737英语、1637粤语、1837四川话、1936普通话远场 result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, }) # print(result) result_text = result["result"][0] print("you said: " + result_text) return result_text except KeyError: print("KeyError") # 图灵机器人的API_KEY、API_URL turing_api_key = "your turing_api_key" api_url = "http://openapi.tuling123.com/openapi/api/v2" # 图灵机器人api网址 headers = {'Content-Type': 'application/json;charset=UTF-8'} # 图灵机器人回复 def Turing(text_words=""): req = { "reqType": 0, "perception": { "inputText": { "text": text_words }, "selfInfo": { "location": { "city": "北京", "province": "北京", "street": "车公庄西大街" } } }, "userInfo": { "apiKey": "c81a2d3f03c6400f968787653fa42f68", # 你的图灵机器人apiKey "userId": "Nieson" # 用户唯一标识(随便填, 非密钥) } } req["perception"]["inputText"]["text"] = text_words response = requests.request("post", api_url, json=req, headers=headers) response_dict = json.loads(response.text) result = response_dict["results"][0]["values"]["text"] return result class AccessToken: @staticmethod def _encode_text(text): encoded_text = parse.quote_plus(text) return encoded_text.replace('+', '%20').replace('*', '%2A').replace('%7E', '~') @staticmethod def _encode_dict(dic): keys = dic.keys() dic_sorted = [(key, dic[key]) for key in sorted(keys)] encoded_text = parse.urlencode(dic_sorted) return encoded_text.replace('+', '%20').replace('*', '%2A').replace('%7E', '~') @staticmethod def create_token(access_key_id, access_key_secret): parameters = {'AccessKeyId': access_key_id, 'Action': 'CreateToken', 'Format': 'JSON', 'RegionId': 'cn-shanghai', 'SignatureMethod': 'HMAC-SHA1', 'SignatureNonce': str(uuid.uuid1()), 'SignatureVersion': '1.0', 'Timestamp': time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime()), 'Version': '2019-02-28'} # 构造规范化的请求字符串 query_string = AccessToken._encode_dict(parameters) # print('规范化的请求字符串: %s' % query_string) # 构造待签名字符串 string_to_sign = 'GET' + '&' + AccessToken._encode_text('/') + '&' + AccessToken._encode_text(query_string) # print('待签名的字符串: %s' % string_to_sign) # 计算签名 secreted_string = hmac.new(bytes(access_key_secret + '&', encoding='utf-8'), bytes(string_to_sign, encoding='utf-8'), hashlib.sha1).digest() signature = base64.b64encode(secreted_string) # print('签名: %s' % signature) # 进行URL编码 signature = AccessToken._encode_text(signature) # print('URL编码后的签名: %s' % signature) # 调用服务 full_url = 'http://nls-meta.cn-shanghai.aliyuncs.com/?Signature=%s&%s' % (signature, query_string) # print('url: %s' % full_url) # 提交HTTP GET请求 response = requests.get(full_url) if response.ok: root_obj = response.json() key = 'Token' if key in root_obj: token = root_obj[key]['Id'] expire_time = root_obj[key]['ExpireTime'] return token, expire_time return None, None def processPOSTRequest(appKey, token, text, audioSaveFile, format, sampleRate) : host = 'nls-gateway.cn-shanghai.aliyuncs.com' url = 'https://' + host + '/stream/v1/tts' # 设置HTTPS Headers。 httpHeaders = { 'Content-Type': 'application/json' } # 设置HTTPS Body。 body = {'appkey': appKey, 'token': token, 'text': text, 'format': format, 'sample_rate': sampleRate} body = json.dumps(body) # print('The POST request body content: ' + body) conn = http.client.HTTPSConnection(host) conn.request(method='POST', url=url, body=body, headers=httpHeaders) # 处理服务端返回的响应。 response = conn.getresponse() contentType = response.getheader('Content-Type') body = response.read() if 'audio/mpeg' == contentType : with open(audioSaveFile, mode='wb') as f: f.write(body) else : print('The POST request failed: ' + str(body)) conn.close() def textConverToVidio(appKey,token,text,audioSaveFile): # with open(file,"r",encoding="utf-8") as f: # text = f.read() textUrlencode = text textUrlencode = urllib.parse.quote_plus(textUrlencode) textUrlencode = textUrlencode.replace("+", "%20") textUrlencode = textUrlencode.replace("*", "%2A") textUrlencode = textUrlencode.replace("%7E", "~") # print('text: ' + textUrlencode) format = 'mp3' sampleRate = 16000 processPOSTRequest(appKey, token, text, audioSaveFile, format, sampleRate) def getToken(): access_key_id = 'LTAI4G1gXMUogGkDacvKmJYu' access_key_secret = 'lw7dNXyVY55hzvYJjolayE8PccsNEZ' token, expire_time = AccessToken.create_token(access_key_id, access_key_secret) print('token: %s, expire time(s): %s' % (token, expire_time)) if expire_time: print('token有效期的北京时间:%s' % (time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(expire_time)))) if __name__ == "__main__": print("开始聊天") while True: token = "13d737af7cd74961bfcacf97e79e821e" while True: my_record() you_say = listen() # you_say = input("you say:") robot_say = Turing(you_say) textConverToVidio("E6IPoVHkVnPT7OYH", token, robot_say, "robot.mp3") print("小玥: " + robot_say) playsound("robot.mp3") os.remove("robot.mp3")