spark未序列化问题虽然不难,但资料却不系统,现总结如下:
问题发生原因
当spark算子在使用外部变量时,就会发生序列化问题,如下图所示:

上述图中算子map会在各个节点运行,属于不同jvm间数据交换,需要对交换的内容进行序列化。这就是为什么需要序列化的原因。
方法
1) 序列化类,并使用broadcast广播
2) 在算子内调用变量
序列化类,使用broadcast广播变量,一个不错的方法,优势在于初始化类的时候只需要一次。其使用方法如下:
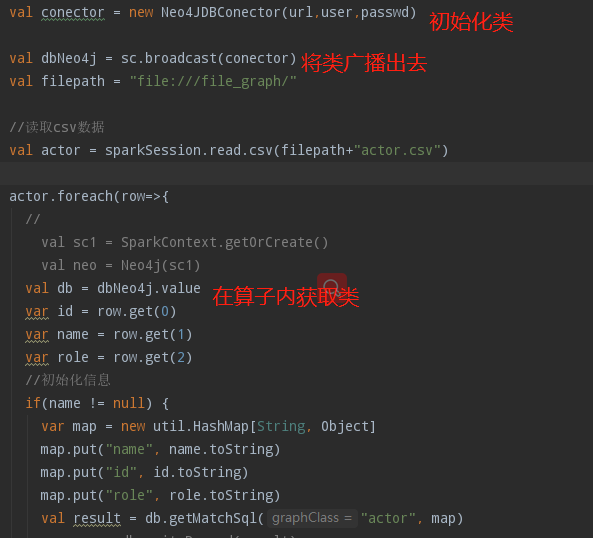
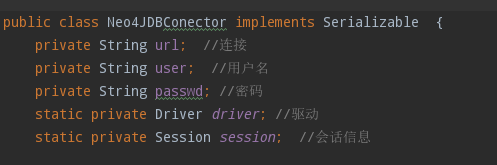
类需要实现接口,此类由java实现,如下:
方法二,是在内部实现类:
如果在算子内需要sparkconf等参数,可以通过 conf =SparkContext.getOrCreate()实现
其他可以在算子内初始化类,缺点是,每个map都需要初始化类。且不需要序列化额外操作。
实现如下:
