Table of Contents
1 饮鸩止渴的存储过程
可能刚开始开发的时候,图一时的简单,为了在服务端少写那么多的C/C++代码,用SQL语句来实现一些逻辑,只需要几行sql语句的存储就解决了,服务端直接调用存储过程,比如说我们要做两张表的数据的关联。两张数据表的操作,如果用程序加载进入内存,然后在比对关联的字段,似乎步骤过多。当用sql语句,可以用select … where … 就能解决问题。起初一个区的玩家可能比较少,性能的问题不能凸显出来。当游戏开始冷却下来,玩家大量离开,为了维持一个区域上的玩家的活跃度,就会去合服。有时候甚至几个区的游戏合成到一个区,两张表的关联数据过多,存储过程执行速度过慢,会导致服务器死锁。到了后期,见到这个问题,要人员再去修改这个模块,可能有诸多抱怨,况且修改这个系统的人不是写这个模块的本人。最后运维将一些等级比较低的,好长时间没有玩的玩家的清理掉,来减少表间数据的关联。我觉得这样子损害了一部分玩家的利益的,可能他某天突然想起到这个游戏,发现自己的账号再也登不上了,虽然他不是付费的玩家。
还有一个问题,就是排行榜的问题,如果用sql语句也是很简单,直接select加上top函数并且排序就行了,多么简单。但是由于玩家的数据一直在变化,排行必须实时获取,用存储过程也是会耗费很多时间的,其在不停的对大量的数据进行重复排序的。这些问题,我们应该在服务端来解决,针对不同的问题,我们应该区分对待。
如果所排列的数据是有一个范围的,而且这个范围比较小,比如[0, 1000]。我们可以使用桶排序的, 数据结构是一个链表数组,数组有1000个桶。如图:

我们直接将对应的值插入到对应的桶的链表里面就OK,插入的速度是o(1),然后就可以直接按照从大到小的顺序抽出1000玩家就OK。
如果所排列的数据是有没有范围的。我们可以这样实现,用一个vector容器来装前一千个玩家,然后用一个hashmap来容纳其余的玩家,当有一个玩家的分值发生改的时候,如果能排上前1000, 就插入到vector里面,插入的时间复杂度为o(n);如果排不上1000, 就放到hashmap里面去,插入的时间复杂度为o(1),这样子反应速度还是能够忍受的。
注意:使用存储过程首先要估量存储过程是不是使用频率比较高; 其次其关联表的多少,而且要考虑当玩家数量激增到一定值时,其反应速度是否能够被接收。
2 一剑封喉的kill -9
当我们运行一个进程,不能关闭时,我们经常这样子:


1 ps -ef | grep "进程名" #查找到进程的id 2 3 kill -9 progress's id #终止进程
我发现有时候游戏需要正常停服,维护的时候,经常这样做; 虽然维护的时间是在夜深人静的时间段,对服务器造成不了什么影响。我实在担心服务器程序就这样突然闪停,会造成数据的紊乱。其实发现在linux下面经常能见到一些服务能够通过命令来停止、开启、重新启动。例如:
1 /etc/netservice stop 2 3 /etc/netservice start 4 5 /etc/netservice restart
为什么我们不能通过命令选项的方式来对服务进行安全的停止了,使其安全着陆了。要是系统数据发生问题,将很难找到问题出现的源头。下面是我用锁来解决问题的流程图:
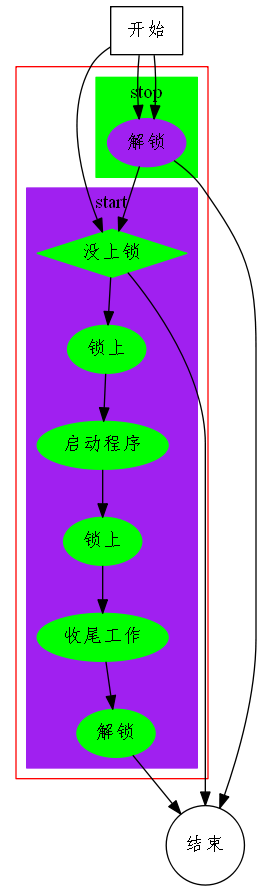
图片上有三条主线:
1.直接进入start块,来开启服务,如果已经上锁了,直接结束,提示已经运行了一个服务实例,保证永远只有一个服务实例运行; 否则就启动程序,因为已经获取了锁资源,再获取锁资源的时候会阻塞。
2.直接通过外部程序stop,来为已有的服务实例解锁,start模块获取第二次的锁资源会阻塞,这时候解锁之后,会获取第二次所资源,紧接着进行收尾工作,接着再进行解锁,最后结束程序。
3.是restart,先stop,停止已经有的实例,然后start来开启服务。这一个主线就是2和1的合集。 这样子比kill -9 安全多了,让程序正常着陆。
3 万里狂飙的缓存
当没有了缓存,经常要查询和更改玩家的数据,直接对数据库进行操作。当在一天中最活跃的时间段,往数据库中插入的数据太频繁,或者查询数据的太频繁,就会造成数据库的死锁,服务器会卡主,造成客户端反应过慢,有时候造成服务端线程卡主,直接导致玩家登陆不进来,这种体验对于玩家来说,糟糕透顶。
这时候缓存就很重要了。缓存一般就是共享内存数据结构,共享内存的好处就是能够是实现进程间通信,而且当一个服务进程崩掉的时候,它还是存在的; 也就是共享内存脱离于进程之外。这时候我们要设计缓存就是实现数据库与服务端数据之间的过渡,不要让查询、更改数据库太过频繁。缓存基本上能够杜绝数据库的查询,其次可以把数据库的更改收集起来,搜集的足够多了,在一定的时间点把数据同步到数据库,这样子效率就高多了。程序-缓存-数据库如图:

这似乎很好,不过忽略了一个问题,那就是持久化的问题。就是缓存还没来得及往数据库里面同步数据,突然间宕机了,这样子造成大量玩家的数据丢失,造成损失还是挺大的。 要是实现缓存+持久化,还是要费点脑子,我建议使用NOSQL数据库。redis和mongdb都可以,我比较倾向于redis。还有一种缓存就是memcache,但是不支持持久化的,我们可以通过memcache来存储游戏模板数据,因为模板数据是不用去更改的,只用作查询。这样子可以加快服务端的启动速度(启动时减少去加载模板表)。 使用redis和memcache,可以尽快的加快服务的启动,使数据更加安全了。
4 注意:
以上的三幅图片都是用graphviz制作的,graphviz属于语言作图工具,设计的流程图所想即所得。