logging由logger,handler,filter,formater四个部分组成,logger是提供我们记录日志的方法;handler是让我们选择日志的输出地方,如:控制台,文件,邮件发送等,一个logger添加多个handler;filter是给用户提供更加细粒度的控制日志的输出内容;formater用户格式化输出日志的信息。
Logging 模块有很多优势,比如:
1.多线程支持
2.通过不同级别的日志分类
3.灵活性和可配置性
4.将如何记录日志与记录什么内容分离
Logging 模块中包含什么
Logging 模块完美地将它的每个部分的职责分离(遵循 Apache Log4j API 的方法)。让我们看看一个日志线是如何通过这个模块的代码,并且研究下它的不同部分。
记录器(Logger)
记录器是开发者经常交互的对象。那些主要的 API 说明了我们想要记录的内容。
举个记录器的例子,我们可以分类请求发出一条信息,而不用担心它们是如何从哪里被发出的。
比如,当我们写下 logger.info(“Stock was sold at %s”, price) 我们在头脑中就有如下模块:
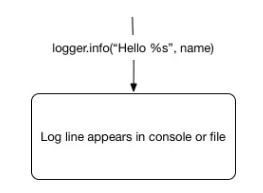
日志记录
日志记录是 logging 模块用来满足所有需求信息的包。它们包含了需要记录日志的地方、变化的字符串、参数、请求的信息队列等信息。
它们都是被记录的对象。每次我们调用记录器时,都会生成这些对象。但这些对象是如何序列化到流中的呢?通过处理器!
处理器
处理器将日志记录发送给其他输出终端,他们获取日志记录并用相关函数中处理它们。
比如,一个文件处理器将会获取一条日志记录,并且把它添加到文件中。
标准的 logging 模块已经具备了多种内置的处理器,例如:
多种文件处理器(TimeRotated, SizeRotated, Watched),可以写入文件中
1.StreamHandler 输出目标流比如 stdout 或 stderr
2.SMTPHandler 通过 email 发送日志记录
3.SocketHandler 将日志文件发送到流套接字
4.SyslogHandler、NTEventHandler、HTTPHandler及MemoryHandler等
目前我们有个类似于真实情况的模型:
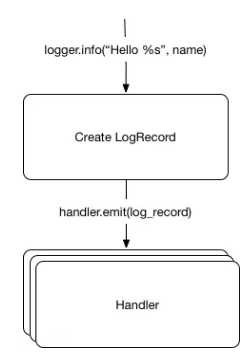
大部分的处理器都在处理字符串(SMTPHandler和FileHandler等)。
格式器
格式器负责将丰富的元数据日志记录转换为字符串,如果什么都没有提供,将会有个默认的格式器。
一般的格式器类由 logging 库提供,采用模板和风格作为输入。然后占位符可以在一个 LogRecord 对象中声明所有属性。
比如:'%(asctime)s %(levelname)s %(name)s: %(message)s' 将会生成日志类似于 2017-07-19 15:31:13,942 INFO parent.child: Hello EuroPython.
请注意:属性信息是通过提供的参数对日志的原始模板进行插值的结果。(比如,对于 logger.info(“Hello %s”, “Laszlo”) 这条信息将会是 “Hello Laszlo”)
所有默认的属性都可以在日志文档中找到。
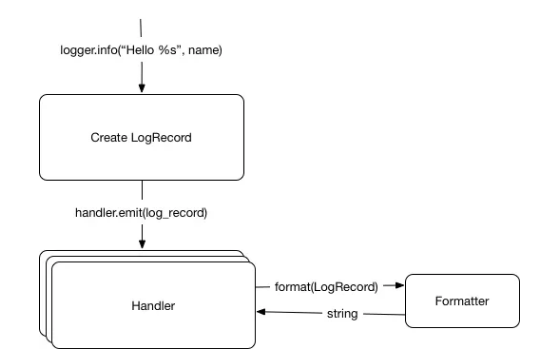
过滤器
我们日志工具的最后一个对象就是过滤器。
过滤器允许对应该发送的日志记录进行细粒度控制。多种过滤器能同时应用在记录器和处理器中。对于一条发送的日志来说,所有的过滤器都应该通过这条记录。
用户可以声明他们自己的过滤器作为对象,使用 filter 方法获取日志记录作为输入,反馈 True / False 作为输出。
出于这种考虑,以下是当前的日志工作流:
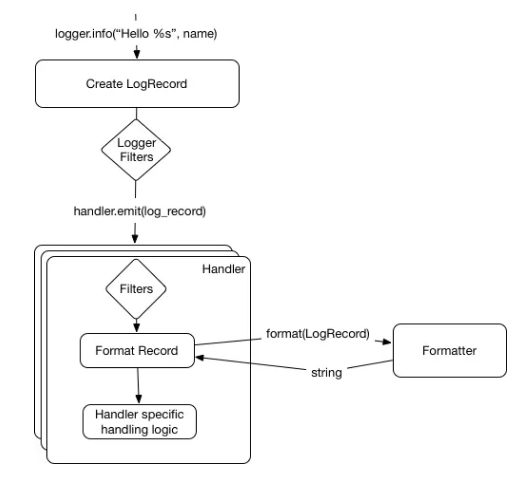
记录器层级
此时,你可能会对大量复杂的内容和巧妙隐藏的模块配置印象深刻,但是还有更需要考虑的:记录器分层。
我们可以通过 logging.getLogger() 创建一个记录器。这条字符向 getLogger 传递了一个参数,这个参数可以通过使用圆点分隔元素来定义一个层级。
举个例子,logging.getLogger(“parent.child”) 将会创建一个 “child” 的记录器,它的父级记录器叫做 “parent.” 记录器是被 logging 模块管理的全局对象,所以我们可以方便地在项目中的任何地方检索他们。
记录器的例子通常也被认为是渠道。层级允许开发者去定义渠道和他们的层级。
在日志记录被传递到所有记录器内的处理器时,父级处理器将会进行递归处理,直到我们到达顶级的记录器(被定义为一个空字符串),或者有一个记录器设置了 propagate = False。我们可通过更新的图中看出:
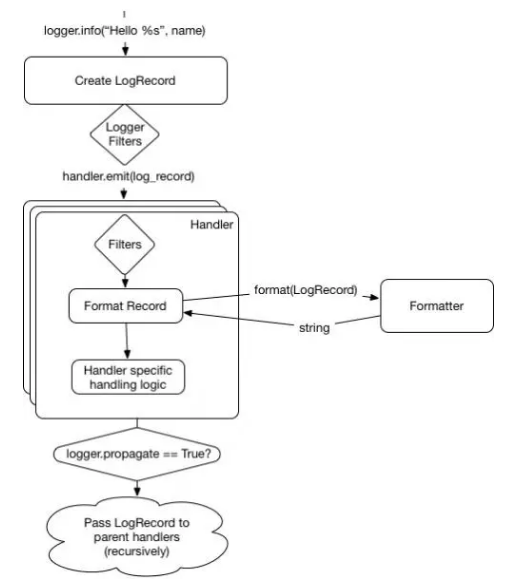
请注意父级记录器没有被调用,只有它的处理器被调用。这意味着过滤器和其他在记录器类中的代码不会在父级中被执行。当我们在记录器中增加过滤器时,这通常是个陷阱。
小结
我们已经阐明过职责的划分以及我们是如何微调日志过滤。然而还是有两个其他的属性我们没有提及:
1.记录器可以是残缺的,从而不允许任何记录从这被发出。
2.一个有效的层级可以同时在记录器和处理器中被设置。
举个例子,当一个记录器被设置为 INFO 的等级,只有 INFO 等级及以上的才会被传递,同样的规则适用于处理器。
基于以上所有的考虑,最后的日志记录的流程图看起来像这样:
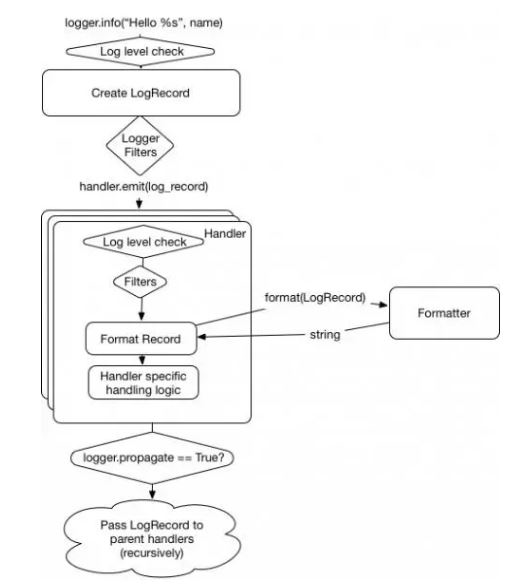
参考:https://www.jb51.net/article/135560.htm