duang~好久没有更新博客啦,原因很简单,实习啦~好吧,我过来这边上班表示觉得自己简直弱爆了。第一周,配置环境;第二周,将数据可视化,包括学习了excel2013的一些高大上的技能,例如数据透视表和mappower绘制3d地图,当然本来打算是在tkinter里面运用matplotlib制作一个交互式的图表界面,然而,画出来的图简直不是excel2013能比的,由于对界面和matplotlib研究的也不是很深,短时间是没法研究出来,上周真是多灾多难;现在,第三周,开始接触hadoop,虽说大多数现在的hadoop上运行的程序都是java,但是经过一周的java初入门,我还是果断的选择在hadoop上面跑python,是的,python是一个深坑,请大家随我入坑,跟着教程一起学习如何用python写hadoop的mapreduce吧!
关于hadoop,建议大家在自己的linux上面跟着网上的教程搭建一次单节点和多节点的hadoop平台,我这里演示的是直接登录服务器,所以环境神马的都是现成的。关于mapreduce,我是新手,只能从“分而治之”的角度来考虑,首先“map”也就是”分”——数据分割,然后“reduce”对"map"处理后的结果进一步的运算,这里给出的例子是一般的hadoop入门程序“WordCount”,就是首先写一个map程序用来将输入的字符串分割成单个的单词,然后reduce这些单个的单词,相同的单词就对其进行计数,不同的单词分别输出,结果输出每一个单词出现的频数。这就是我们的简单程序的思想,让我们玩玩~
注意:关于数据的输入输出是通过sys.stdin(系统标准输入)和sys.stdout(系统标准输出)来控制数据的读入与输出。所有的脚本执行之前都需要修改权限,否则没有执行权限,例如下面的脚本创建之前使用“chmod +x mapper.py”
1.mapper.py
1 #!/usr/bin/env python 2 import sys 3 4 for line in sys.stdin: # 遍历读入数据的每一行 5 6 line = line.strip() # 将行尾行首的空格去除 7 words = line.split() #按空格将句子分割成单个单词 8 for word in words: 9 print '%s %s' %(word, 1)
2.reducer.py
1 #!/usr/bin/env python 2 3 from operator import itemgetter 4 import sys 5 6 current_word = None # 为当前单词 7 current_count = 0 # 当前单词频数 8 word = None 9 10 for line in sys.stdin: 11 words = line.strip() # 去除字符串首尾的空白字符 12 word, count = words.split(' ') # 按照制表符分隔单词和数量 13 14 try: 15 count = int(count) # 将字符串类型的‘1’转换为整型1 16 except ValueError: 17 continue 18 19 if current_word == word: # 如果当前的单词等于读入的单词 20 current_count += count # 单词频数加1 21 else: 22 if current_word: # 如果当前的单词不为空则打印其单词和频数 23 print '%s %s' %(current_word, current_count) 24 current_count = count # 否则将读入的单词赋值给当前单词,且更新频数 25 current_word = word 26 27 if current_word == word: 28 print '%s %s' %(current_word, current_count)
在shell中运行以下脚本,查看输出结果:
1 echo "foo foo quux labs foo bar zoo zoo hying" | /home/wuying/mapper.py | sort -k 1,1 | /home/wuying/reducer.py 2 3 # echo是将后面“foo ****”字符串输出,并利用管道符“|”将输出数据作为mapper.py这个脚本的输入数据,并将mapper.py的数据输入到reducer.py中,其中参数sort -k 1,1是将reducer的输出内容按照第一列的第一个字母的ASCII码值进行升序排序
其实,我觉得后面这个reducer.py处理单词频数有点麻烦,将单词存储在字典里面,单词作为‘key’,每一个单词出现的频数作为'value',进而进行频数统计感觉会更加高效一点。因此,改进脚本如下:
mapper_1.py
但是,貌似写着写着用了两个循环,反而效率低了。关键是不太明白这里的current_word和current_count的作用,如果从字面上老看是当前存在的单词,那么怎么和遍历读取的word和count相区别?
下面看一些脚本的输出结果:
我们可以看到,上面同样的输入数据,同样的shell换了不同的reducer,结果后者并没有对数据进行排序,实在是费解~
让Python代码在hadoop上跑起来!
一、准备输入数据
接下来,先下载三本书:
1 $ mkdir -p tmp/gutenberg 2 $ cd tmp/gutenberg 3 $ wget http://www.gutenberg.org/ebooks/20417.txt.utf-8 4 $ wget http://www.gutenberg.org/files/5000/5000-8.txt 5 $ wget http://www.gutenberg.org/ebooks/4300.txt.utf-8
然后把这三本书上传到hdfs文件系统上:
1 $ hdfs dfs -mkdir /user/${whoami}/input # 在hdfs上的该用户目录下创建一个输入文件的文件夹 2 $ hdfs dfs -put /home/wuying/tmp/gutenberg/*.txt /user/${whoami}/input # 上传文档到hdfs上的输入文件夹中
寻找你的streaming的jar文件存放地址,注意2.6的版本放到share目录下了,可以进入hadoop安装目录寻找该文件:
$ cd $HADOOP_HOME $ find ./ -name "*streaming*"
然后就会找到我们的share文件夹中的hadoop-straming*.jar文件:
寻找速度可能有点慢,因此你最好是根据自己的版本号到对应的目录下去寻找这个streaming文件,由于这个文件的路径比较长,因此我们可以将它写入到环境变量:
$ vi ~/.bashrc # 打开环境变量配置文件 # 在里面写入streaming路径 export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
由于通过streaming接口运行的脚本太长了,因此直接建立一个shell名称为run.sh来运行:
1 hadoop jar $STREAM 2 -files ./mapper.py,./reducer.py 3 -mapper ./mapper.py 4 -reducer ./reducer.py 5 -input /user/$(whoami)/input/*.txt 6 -output /user/$(whoami)/output
然后"source run.sh"来执行mapreduce。结果就响当当的出来啦。这里特别要提醒一下:
1、一定要把本地的输入文件转移到hdfs系统上面,否则无法识别你的input内容;
2、一定要有权限,一定要在你的hdfs系统下面建立你的个人文件夹否则就会被denied,是的,就是这两个错误搞得我在服务器上面痛不欲生,四处问人的感觉真心不如自己清醒对待来的好;
3、如果你是第一次在服务器上面玩hadoop,建议在这之前请在自己的虚拟机或者linux系统上面配置好伪分布式然后入门hadoop来的比较不那么头疼,之前我并不知道我在服务器上面运维没有给我运行的权限,后来在自己的虚拟机里面运行一下example实例以及wordcount才找到自己的错误。
好啦,然后不出意外,就会complete啦,你就可以通过如下方式查看计数结果:
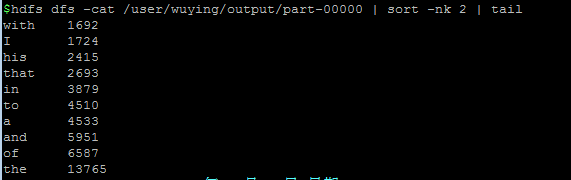
上面的字数计量大小可能你们跟我的不一样,那是因为我换了另外一个文档测试,所以不用着急哈。
再次,感谢以下文档的支持:
人生漫漫,且走且珍惜,加油,all is well, just do it!