现在我们要检测《中国的蜜蜂养殖》这篇论文里面的关键词,假设数据库里面有250亿篇论文,
| ——————————每个关键词在本文(待检测样本)中出现比例
| (词频:某单词在某个样本中比例越高,越有区分度)
|
| | ———————每个关键词在词典(数据库)中出现比例
| | (反文档频率:某单词在总数据库中比例越低,越有区分度)
| |
| | |——表征:在样本《中国的蜜蜂养殖》中,最能代表它的词源是哪一个
| | |
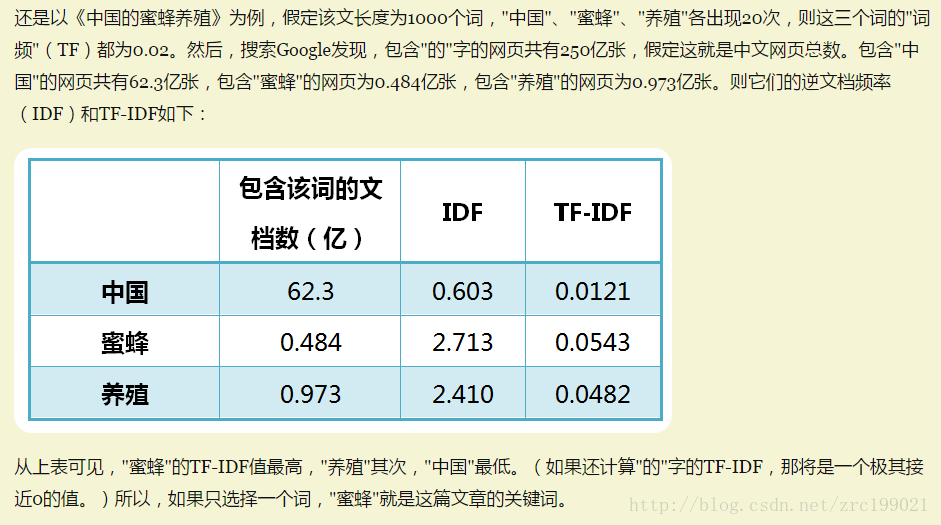
包含这个词 TF IDF TF-IDF
语的文档(亿)
的 250 0.02 -> 0 ->0
中国 62.3 0.02 0.603 0.0121
蜜蜂 0.484 0.02 2.713 0.0543
养殖 0.973 0.02 2.410 0.0482
再举个例子:
比如:以三个指标评价一个大学生:编程水平,动手能力,数学功底;
如果一个大学生叫:单生狗,编程水平一般,动手能力一般,数学功底牛逼;把他放到普通二本
大学里边,在人群中,他就是鹤立鸡群,你很容易区分他,很容易找到他。但是,如果把他放到
清华大学,在人群中,一眼望去,你很难找到他,因为,人群中数学功底牛逼的人太多了。