一、VG数据集
机器学习领域的突破突然让计算机获得了以未曾有的高精度识别图像中物体的能力——几乎达到了让人惊恐的程度。现在的问题是机器是否还能更上层楼,学会理解这些图片中所发生的事件。
Visual Genome的新图像数据库有望推动计算机向这一目标挺进,并帮助衡量计算机在理解真实世界这一进程中的进步。教会计算机理解视觉场景是人工智能非常重要的基础。它不仅能产生更多有用的视觉算法,也能帮助训练计算机实现更高效的交流,因为语言与物质世界的表征具有非常密切的联系。
Visual Genome是由专业研究计算机视觉的教授兼斯坦福大学人工智能实验室主任李菲菲与几位同事合作开发的。“我们非常专注于一些计算机视觉领域里最困难的问题,这些问题能够真正构建起感知到认知的桥梁。”李教授说,“并不只是输入像素数据后理解其颜色、阴影这类东西,而还要将其转换成对3D和语义视觉世界更全面的理解。”
摘自于知乎: VG数据集....
.............................
Visual Genome中的图像比ImageNet中的图像拥有更多的标记,包括单张图像中出现的多种物体的名称和细节、这些物体之间的关系和正在发生的动作的信息。这些标记是通过李教授的斯坦福同事Michael Bernstein所开发的众包方式完成的。李教授团队的计划是在2017年使用该数据库推出一个类似于ImageNet的挑战赛。
使用Visual Genome中的案例训练的算法将不止能完成识别物体的任务,还应该拥有一定的分析更复杂视觉场景的能力。
Visual Genome is a dataset, a knowledge base, an ongoing effort to connect structured image concepts to language.
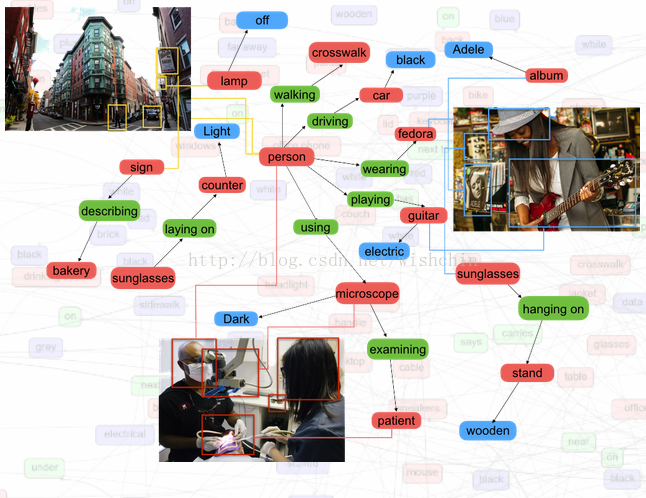
截至 2018年03月05日,VG数据集达到条目 10万张数据集
2.关于Place数据集
Place数据集是另外一个标记场景的数据集,但貌似现阶段只对整体场景进行标记,并没有到对象检测和分割的层面。
二、MaskXRCnn
图片分割掩模Mask标注远比实例Rect标注耗费更多的人力财力,因此使用有限的Mask标注和大量的Rect标注称为训练分割网络的一个预期,因此引入偏监督学习。
基于偏监督学习的实例分割任务如下:
(1)给定一组感兴趣的类别和一个有实例掩码注释的小的子集,而其他类别只有边界框注释;
(2)实例分割算法可以利用这个数据来拟合一个模型,该模型可以分割所感兴趣的集合中的所有对象类别的实例。由于训练数据是完整注释数据(带掩码的示例)和弱注释数据(仅带框的示例)的混合,因此我们将该任务称为偏监督任务。
.........................
偏监督学习样例流程的主要好处是它允许我们通过利用两种类型的现有数据集来构建一个大规模的实例分割模型:那些在大量的类上使用边界框注释的数据集,比如Visual Genome, 以及那些在少数类别上使用实例掩码注释的,例如COCO数据集。正如我们接下来将要展示的那样,这使得我们能够将最先进的实例分割方法扩展到数千个类别,这对于在现实世界中部署实例分割是非常重要的。
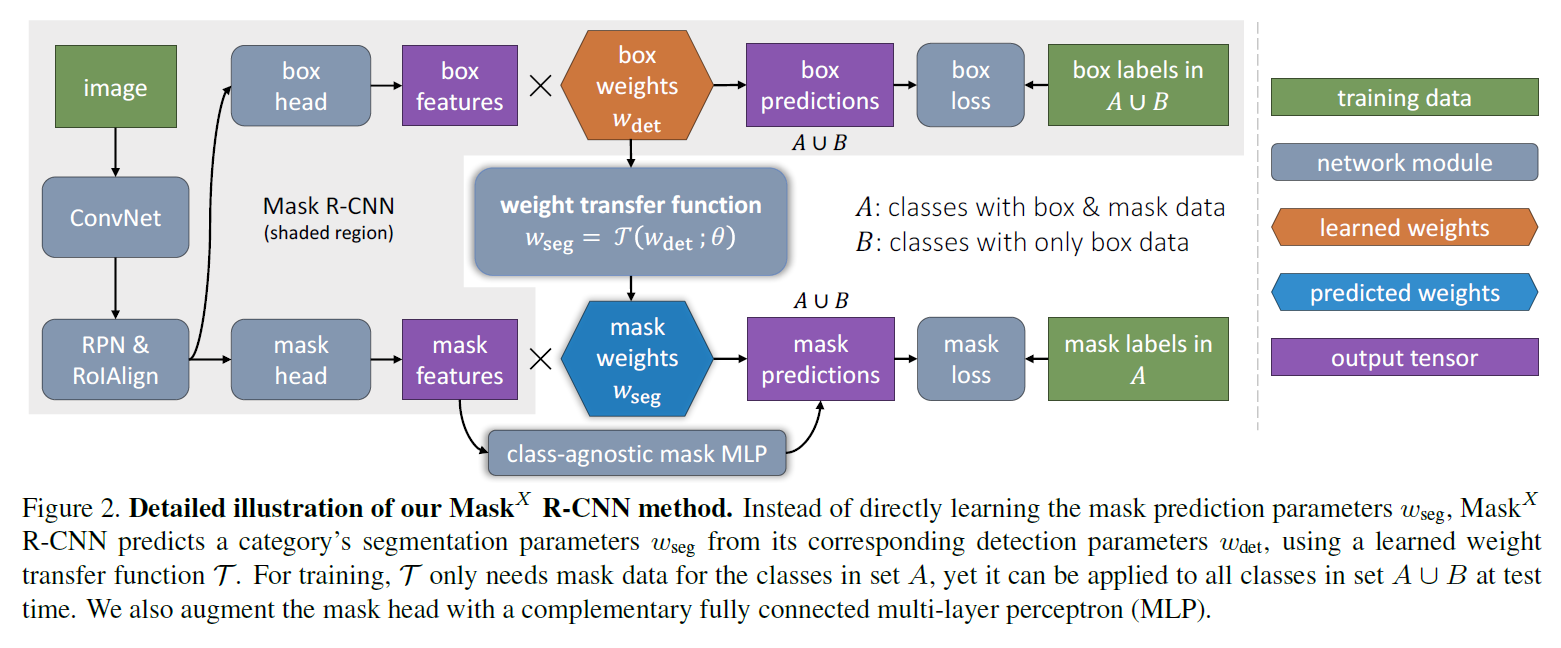
为了解决偏监督的实例分割问题,我们提出了一种基于Mask R-CNN的新型迁移学习的方法。 Mask R-CNN非常适合我们的任务,因为它将实例分割问题分解为了目标的边界框检测和掩码预测两个子任务。这些子任务是由专门的网络“头部(heads)”共同训练的。我们的方法背后的直觉是,一旦训练完成了,边界框头部(the bounding box head)参数编码嵌入到每个对象类别,使该类别的视觉信息转移到偏监督掩码头部(the partially supervised mask head)参数上。
...................................
下面的才是重点:
学习分割一切物体
假设集合C为一组对象类别(例如‘things’),我们要用这些类别来训练一个实例分割模型。大多数现有方法假设C中所有的训练实例都标有掩码注释。我们放宽了这个要求,只假设C=A∪B,也就是说:集合A中的类别实例都标有掩码注释,集合B中的类别实例只有边界框注释。由于集合B中的类别只带有关于目标任务(实例分割)的弱标签,我们将使用组合强标签(strong labels)和弱标签(weak labels)的类别来训练模型的问题称为偏监督学习问题。
注意:我们可以轻易地将实例的掩码注释转换为边界框注释,因此我们假设A中的类别也带有边界框注释。由于Mask RCNN这样的实例分割模型都带有一个边界框检测器和一个掩码预测器,我们提出的
利用权重传递函数预测掩码
................请看原始论文或者完整翻译....
流程图
参考:
Learning to Segment Every Thing