sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive、hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入
从RDBMS中抽取出的数据可以被MapReduce程序使用,也可以被类似Hive的工具使用;得到分析结果后sqoop可以将结果导回数据库,供其他客户端使用
sqoop安装

解压然后配置环境变量即可
从oracle向HDFS导入数据
原理:
1)在导入之前,sqoop使用jdbc来检查将要导入的表,检索出表中所有的列及数据类型,然后将这些类型映射为java类型,在mapreduce中将使用对应的java类型保存字段的值。sqoop的代码生成器使用这些信息来 创建对应的类,用于保存从表中抽取的记录
2)不需要每次都导入整张表,可以在查询中加入where子句,来限定需要导入的记录
导入:
遍历oracle的表:
sqoop list-tables --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password=**
导入oracle中的表:
sqoop import --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password **--table ENTERPRISE -m 1 --target-dir /user/root --direct-split-size 67108864
其中split-size指定导入的HDFS路径与导入的文件大小限制
注意:1. 默认情况下会使用4个map任务,每个任务都会将其所导入的数据写到一个单独的文件中,4个文件位于同一目录,本例中 -m1表示只使用一个map任务
2. 文本文件不能保存为二进制字段,并且不能区分null值和字符串值"null"
3. 执行上面的命令后会生成一个ENTERPRISE.java文件,可以通过ls ENTERPRISE.java查看,代码生成是sqoop导入过程的必要部分,sqoop在将源数据库中的数据写到HDFS前,首先会用生成的代码将其进行反序列化
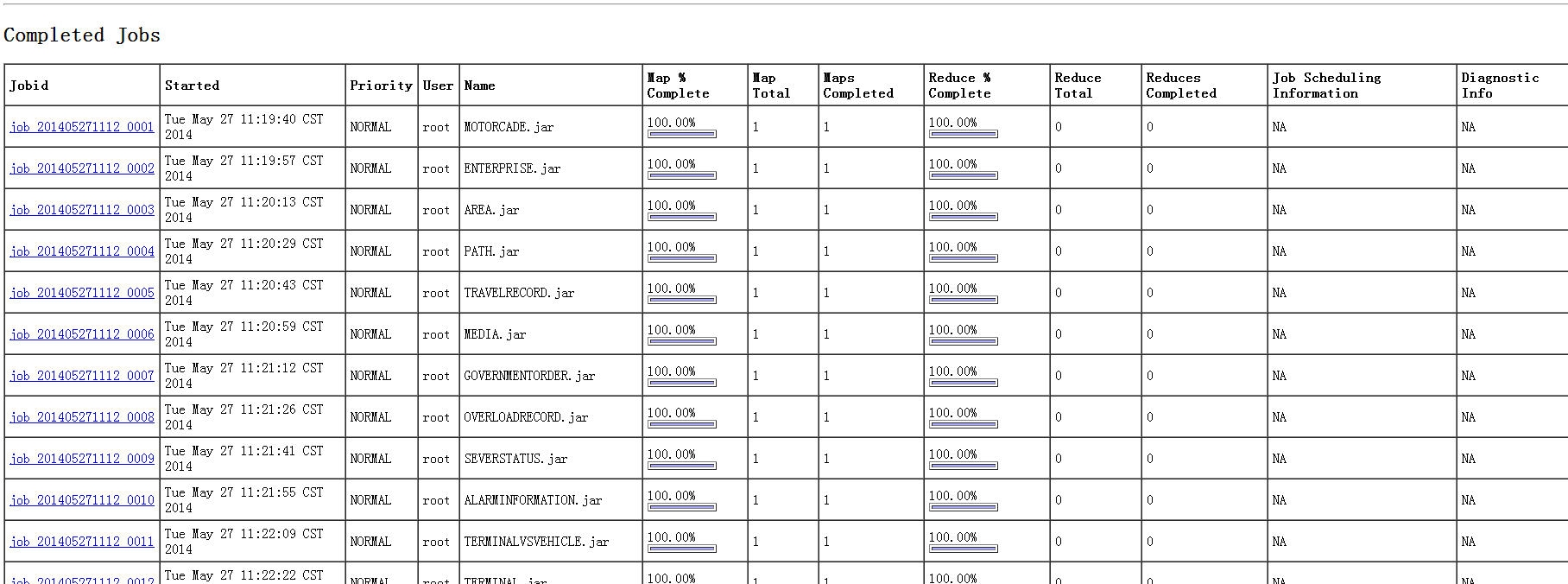
在MapReduce下查看:
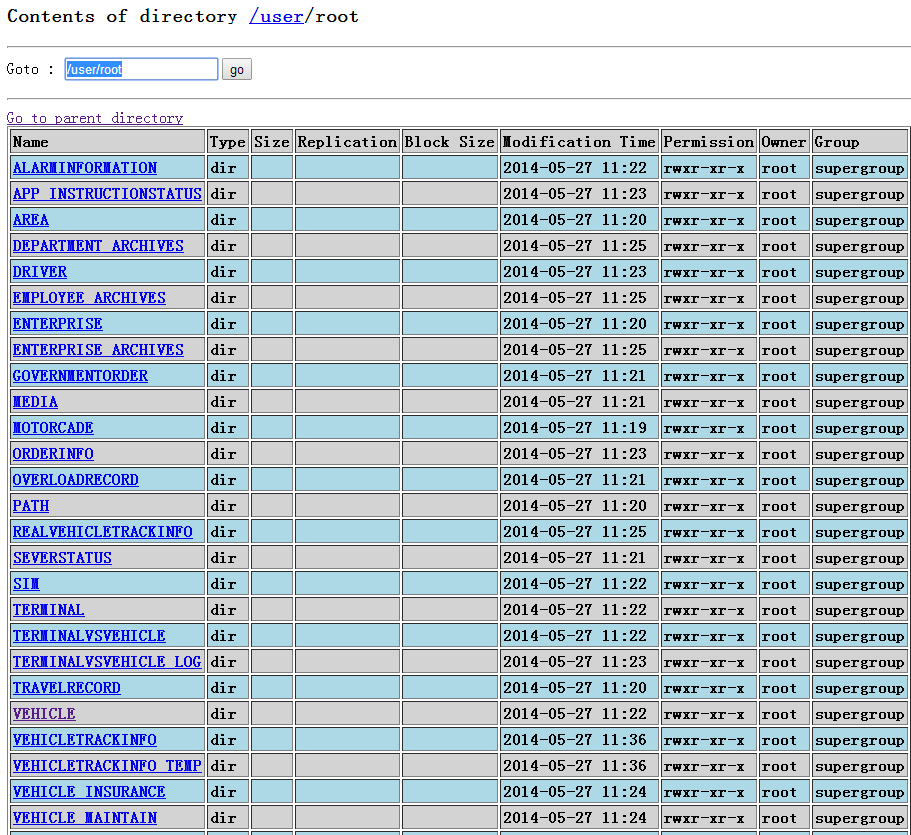
在namenode下查看:
查看VEHICLE表:
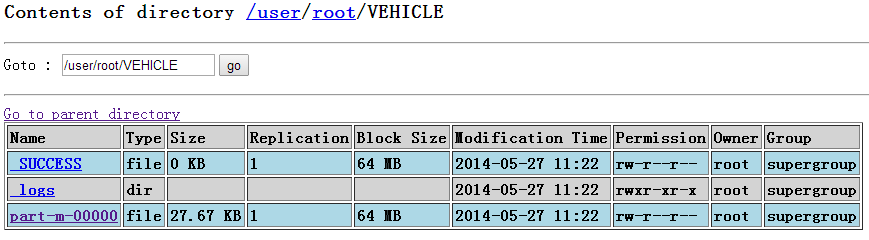
查看part-m-00000中数据

oralce中每条记录对应上面一行数据
数据导出
使用export可将hdfs中数据导入到远程数据库中
eg:
export --connect jdbc:oracle:thin:@192.168.**.**:**:**--username **--password=** -m1 table VEHICLE--export-dir /user/root/VEHICLE
向Hbase导入数据
eg:
sqoop import --connect jdbc:oracle:thin:
@192.168.**.**:**:**--username **--password=**--m 1 --table VEHICLE --hbase-create-table --hbase-table VEHICLE --hbase-row-key ID --column-family VEHICLEINFO --split-by ID