讲授神经网络的理论解释、实现细节包括输入与输出值的设定、网络规模、激活函数、损失函数、初始化、正则化、学习率的设定、实际应用等
大纲:
实验环节:
理论层面的解释:两个方面,1.数学角度,映射函数h(x)理论分析;2.和动物神经网络的区别。
实现细节问题:输入输出值该怎么设置,神经网络该建多少层,每层多少个神经元,选择什么样的激活函数和损失函数。
面临的挑战与改进措施:梯度消失,局部最小值,鞍点等。
实际应用情况:
实验环节:(通过代码实现)
设置网络的层数和各层神经元数量。设置激活函数和参数。设置训练参数,包括最大迭代次数,迭代终止阈值,学习率,动量项系数等。生成训练样本(用MINST数据集,全连接FC神经网络训练,96%以上准确率),关键是设置样本标签值(多分类,One-hot编码)。调用训练函数。
定义网络结构,设置好网络参数,直接调用train函数(caffe,tensorflow,opencv,或pytorch)训练就可以了。
理论层面的解释:数学特征(映射函数h(x)具有哪些性质);与动物神经网络系统的关系
映射函数h(X)——>Y,为一个多层复合函数。
万能逼近定理:证明了至少有一个隐藏层的神经网络,映射函数的可以拟合函数的可能性,要有多接近真实函数就有多接近。

可以构造出上面这样的函数,逼近定义在单位立方体空间中的任何一个连续函数到任意指定的精度。
另一种说法:
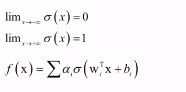
人工神经网络是对生物神经系统的模拟,但只是简单的模拟,在多个方面两者的机理是不同的。
人脑的单个神经元有很多复杂的结构,各个神经元在结构和功能上不是完全相同的,另外神经元之间的连接关系非常复杂。
在训练方式上,人脑的神经网络没有反向传播算法这种机制,在外界刺激下建立神经元之间连接通路的机制远比反向传播复杂。
前馈型人工神经网络本质上来说只是一个多层复合函数。
实现细节问题:对网络跑出来的精度影响非常大
输入与输出值的设定。网络的规模。激活函数的选择。损失函数的选择。权重的初始化。正则化。学习率的设定。动量项梯度下降法。
输入值与输出值设定:
类别型变量(如小学、初中、高中、本科...)、多分类问题(手写数字识别0,1,...)的类标签,都建议使用One-hot编码形式,而不要直接用整数标号。
输入值,输出值都建议做归一化,尤其是输入值一定要归一化,因为在激活函数计算值时,输入值太大或太小会造成浮点数上溢或下溢。
网络的规模:
神经元的层数,早期很小,现在很深。太深会梯度消失。样本太少网络不能太深,否则模型太复杂样本太少会出现过拟合问题,层数根据问题规模和训练样本的规模来定。
各层神经元数量。输入层与输出层是确定的(输入层神经元个数等于输入样本的维数,回归问题需要几个输出分量的向量就设置几个神经元,k分类输出层神经元为k个),隐含层根据经验而定,一般情况下,设置为2的n次方,以提高计算与存储效率。
层数、每一层的尺寸经过“试”验确定。
激活函数:
保证神经网络是一个非线性的映射(线性:n元一次函数),去掉激活函数,不管怎么复合都是线性映射。
激活函数应该是非线性、几乎处处可导、单调函数(一般是单调增),并且尽量避免饱和(f'(x)==0)。
常用的激活函数:sigmoid(sigmoid和逻辑斯蒂回归中的映射函数是一样的)、tanh(和sigmoid和相互推导)、ReLU、其他改进型。
饱和函数容易出现梯度消失问题。

损失函数:
回归问题用欧式距离(又叫均方误差)(||y*-y||22)损失函数,分类问题用交叉熵损失函数。
逻辑斯蒂回归和softmax回归用交叉熵损失函数,因为欧氏距离损失函数不能保证是凸函数,存在局部最小值点或鞍点,会收敛到不好的值,用交叉熵损失函数可以保证是凸函数,收敛到一个很好的值。
交叉熵损失 y是样本的标签向量真实值,ont-hot编码,只有一个为1其他都为0([0,1,0,0,0,...]T),是一个列向量,预测出来的向量值y*,神经网络最后一层一般是softmax(概率向量,每个分量0~1,和为1),因为yT中只有yi为1,所以L=-logyi*。当y和y*分布相同时,L达到最小值,即最好的情况。

证明: 当p(x)、q(x)两个分布相等的时候,交叉熵有极小值
拉格朗日法求解极值点,然后证明此极值点是极小值点。

证明交叉熵函数是凸函数就可以证明求得的极值点是极小值点了。
交叉熵函数的Hession矩阵(L对x向量的二次导数)为:

严格正定矩阵,对任意x,xTAx>0,因此L为严格的凸函数,因此该极值点为唯一的极小值点。
权重初始化:
逻辑斯蒂回归、softmax回归等不带等式或不等式约束的,一般把x初始化为全1或全0就可以了。而神经网络一般不这样做,会造成失效,一般是采用随机数进行初始化,编程中一般采用均匀分布和正态分布的随机数。
caffe中权重的初始化为

正则化:
为了抵抗过拟合问题,在目标函数,如损失函数中加一个正则化项。
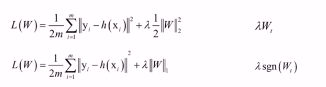
学习率:

为了使wk+1在wk的邻域内,设置学习率。
一般设置为接近于0的正数。可以采用更复杂的策略,训练过程中动态调整。
动量项梯度下降法:
为了加快算法的收敛速度减少震荡,引入了动量项,动量项累积了之前的权重更新值。

面临的挑战与改进措施:
梯度消失问题。退化问题。局部极小值问题。鞍点问题。
梯度消失问题:
如果激活函数导数的绝对值小于1,多次连乘之后,误差项接近于0,导致根据它计算的参数梯度值接近于0,参数无法有效更新。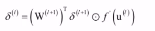
产生梯度消失的原因是激活函数的饱和性
所以网络层数深的时候,一般用ReLU激活函数或ReLU的变种,因为>0时导数为1,ReLU一定程度上可以缓解梯度消失问题。
与之相反的是梯度爆炸,即f'>>1,浮点数溢出,可以通过归一化解决。
退化问题:
神经网络的训练误差和测试误差会随着层数的增加而增大,所以不一定是层数越多越好。(不同于过拟合,过拟合是训练集上表现很好、测试集表现差,而退化是训练集、测试集表现都差。)
解决办法为残差网络、高速公路网络。
局部极小值问题:
神经网络的优化目标不是一个凸优化,有陷入局部极小值的风险。像SVM、逻辑斯蒂回归LR、softmax回归,他们的目标函数是凸函数,因此不会有局部极小值问题,他们优化问题是凸优化问题,而神经网络的优化问题不是凸优化问题。
鞍点问题(类似于局部极小化问题):
虽然极值为0,但不是局部极小值,Hession矩阵既不正定也不负定。
由于存在鞍点问题、局部极小值问题、梯度消失问题、退化问题等,自从1986年反向传播算法发明以后到2012年alexnet算法又流行起来,尤其1993年以后,这些年神经网络很不受待见,而是SVM、adboost反而占了上风。
神经网络损失函数的曲面:

实际应用:
人脸检测
人脸识别
光学字符识别
手写字符识别
自然语言处理

手写数字识别:
