讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用
大纲:
支持向量机简介
线性分类器
分类间隔
线性可分问题
线性可分的对偶问题
线性不可分问题
线性不可分的对偶问题
核映射与核函数
支持向量机简介:
SVM是所有机器学习算法里边,对数学要求比较高的一种算法,主要难在拉格朗日对偶和KKT条件。
由Vapnik等人1995年提出,在出现后的20多年里它是最有影响力的机器学习算法之一,直到2012年它才被深度学习给打败,在1995-2012之间,它和人工神经网络较量中是一直处于上风的。
在深度学习技术出现之前,使用高斯核(RBF)的支持向量机在很多分类问题上一度取得了最好的结果,很多工程上的论文及应用都是用SVM做的。
SVM不仅可以用于分类问题(叫SVC),还可以用于回归问题(叫SVR)。
具有泛化性能好,就是从最大化间隔里边导出的一种算法,推广能力是非常好的,而且适合小样本(样本不需要很多就可以训练出一个很好的模型出来)和高维特征等优点(最后求解的时候,和训练样本数有关,和特征向量维数关系不是特别大)。
线性分类器:
SVM是从线性分类器之中衍生出来的,本质上是最大化间隔的线性分类器。
对于n维向量,x∈Rn,线性分类器是以下预测函数: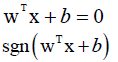 ,解决二分类问题样本标签值为+1或-1。
,解决二分类问题样本标签值为+1或-1。
它是n维空间的一个超平面,超平面的方程只是给出了分界面,哪边为正,哪边为负,是可以灵活控制的,样本带入函数如果大于零判定为+1否则判定为-1,等于零分为+1或-1都行。该超平面只是作为分界面,并没给出哪边大于零哪边小于零,因为超平面方程乘以-1可以随意改变正负分类。方程要写成标准形式kx-y+b=0,不要写成y=kx+b,为标准方程可以表示任意直线或平面,而y=kx+b不能表示与坐标轴垂直的直线。
分类间隔:
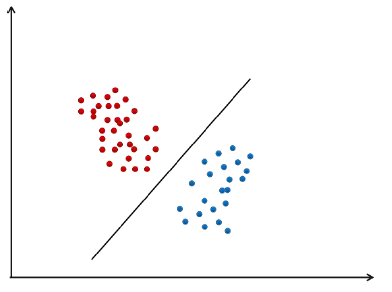
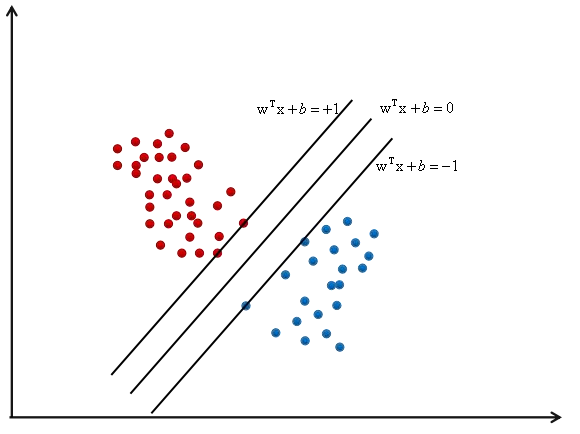
前面说的是二分类问题,对于多分类也是可以的。如果样本集是线性可分的(用线性分类器可以将其分类),一般都存在不止一个可行分类超平面(wT+b=0,w、b是不唯一的)。
对于一个问题,可行的分类器不止一个,哪一个是最好的?
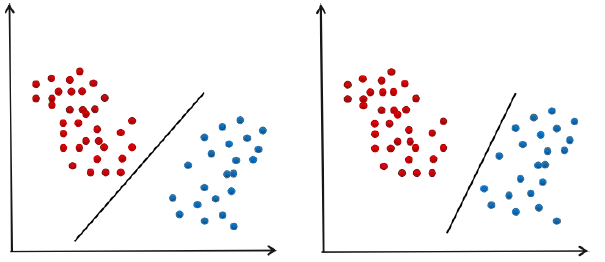
上图1的超平面推广和泛化性能很差, 推广和泛化性能用余量来表示,余量是分类超平面到两边的距离,样本都不止一个,要让距离分类超平面最近的样本距离超平面的距离最大化。
分类平面应该不偏向于任何一类,并且离两个类的样本都尽可能的远。
线性可分问题:
任给两点,为什么存在|wx+b|=1,而且w、b是否唯一?
首先要保证样本都被正确分类,最终得到的分割超平面为:wTx+b=0。对于正样本来说带入样本得wTx+b≥0,对于负样本来说wTx+b≤0,即yi(wTxi+b)≥0,这里设置限制条件对于距离超平面最近的正负样本的|wTx+b|=1,因为方程由冗余即w、b不唯一,限定条件使w、b唯一,那么得到yi(wTxi+b)≥1,因为距离超平面越远|wTxi+b|越大(由距离公式可知)。样本到超平面距离公式为d=|wTxi+b|/||w||,则正负样本到分离超平面的最小距离之和为:

于是就得到优化的目标:
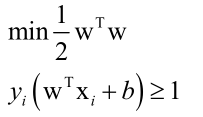
线性可分的对偶问题:
前面的最优化问题带有太多的不等式约束,不易求解。可行域都是线性不等式围成的区域,由于线性等式、线性不等式围成的区域都是一个凸集;对于目标函数,由于它的Hession矩阵是单位阵,所以是一个严格正定矩阵,所以目标函数是凸函数。因为可行域为凸集且目标函数是凸函数,所以这是一个凸优化问题,因此一定能够找到它的全局最优解。Slater条件保持强对偶成立的一个条件,如果用拉格朗日对偶把一个问题转化为对偶问题求解,他们两个要等价即满足强对偶条件,由于存在w、b可以使得所有不等式约束严格满足,所以可以转化为对偶问题求解。由于原问题中带有太多的不等式约束条件,找到一个初始可行解以及在迭代过程中每次用牛顿法或者是梯度下降法迭代的时候,求一个新的点,这个点是否满足这个不等式约束都很难保证,所以求解起来非常麻烦,因此把它转化成对偶问题来求解,又因为这个问题时凸优化问题并且Slater条件是成立的,所以说强对偶是成立的,强对偶成立即原问题和对偶问题等价,而原问题和原始问题本来就等价,所以强对偶成立以后,原始问题和对偶问题等价,即对对偶问题的求解来代替对原始问题的求解,就可以用拉格朗日对偶把它转化为对偶问题来求解。
即这个优化问题是凸优化,而且满足Slater条件,因此可以强对偶成立,可以用拉格朗日对偶转化成对偶问题。
拉格朗日对偶:首先构造拉格朗日乘子函数,里边对等式约束和不等式约束各构造了一组乘子(乘子都大于等于0);然后求L对原始要优化的变量的极小值,得到用乘子变量表示的原始要优化的变量;将求得的用乘子变量表示的原始要优化的变量带入到L,求L对乘子变量的极大值,得到乘子变量,从而得到原始要优化的变量。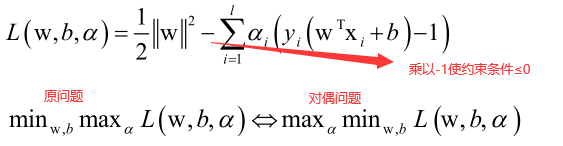
对w、b求极小值:
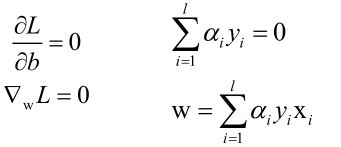
将求得的关于w、b的方程带入到L,把w、b消掉,求L对α的极小值:
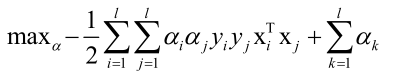
问题转化为:
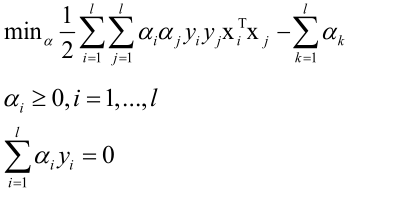
由于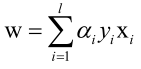 ,所以对某个样本求得的αi不等于0,则对w是起了贡献的,否则就不起贡献,如果αi不等于0,则αi对应的向量成为支持向量,这就是支持向量机这个名字的来历,即超平面的方程
,所以对某个样本求得的αi不等于0,则对w是起了贡献的,否则就不起贡献,如果αi不等于0,则αi对应的向量成为支持向量,这就是支持向量机这个名字的来历,即超平面的方程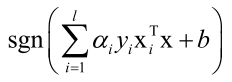 中的w是由不等于0的αi及其对应的xi、yi即支持向量贡献的。
中的w是由不等于0的αi及其对应的xi、yi即支持向量贡献的。
线性不可分问题:
线性可分过于理想化,实际中遇到的样本就根本不能保证它是线性可分的,所以说上面的推导只是个理想的模型,现实中没法真正去实用。下面就把它扩展,能处理线性不可分问题的SVM,它要求解的模型,怎么扩展呢?这里用了两个技巧,用了松弛变量(在最优化问题中经常用到的),第二个是用了惩罚因子。
对于有些样本可能不满足yi(wT+b)≥1的约束,那么就加一个大于等于0的松弛变量ξi,如果ξi等于0的话表示样本确实是遵守不等式约束的,如果ξi大于0的话,说明该样本违反了不等式约束,如果突破了不等式约束就要对它进行一个惩罚,目标是要使惩罚最小化,让所有样本都尽可能的正确分类,落在超平面那两个间隔线以外。则优化问题变为:
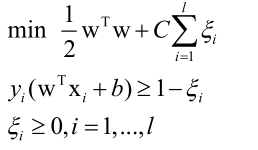
加了松弛变量和惩罚因子的问题仍然是凸优化问题,C是用户自己设定的(大于0的常数),因为对于线性不等式约束围成的集合同样是一个凸集,对于目标函数前面一部分是凸函数,后边一项也是凸函数,则加起来也是凸函数,所以是凸优化问题。并且也满足Slater条件,所以可以用拉格朗日对偶来进行转化。

得到优化问题:
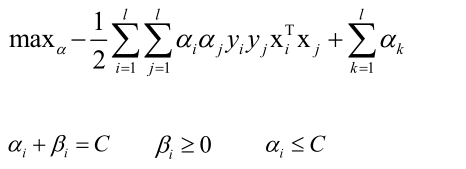
发现和线性可分的目标函数是一样的,只不过多了几组约束,然后再求解以下问题:
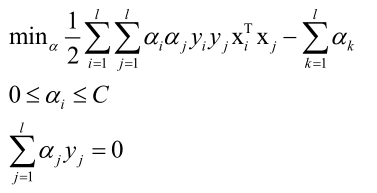
可见和线性可分相比,乘子变量多了一个上界C,其他都一样。
得到: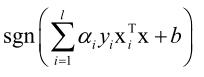 ,它仍然是一个线性模型。
,它仍然是一个线性模型。
简化形式:

这是一个凸优化问题:
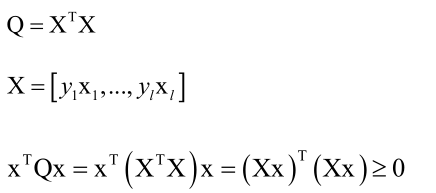
KKT条件(拉格朗日乘数法的推广,处理既带有等式约束又带有不等式约束的优化问题。首先构造一个拉格朗日乘子函数,它在最优点处除了要满足拉格朗日乘数法要满足的条件以外,还要额外的加一组约束,如果gi(x)≤0,则加上约束βigi(x)=0)对原问题最优解额外的约束:

对于α分三种情况讨论:

对于ai=0的样本他们是自由向量,不是支持向量,即yi(wTx+b)≥1。而0<ai<C的样本才是真正的支持向量,即yi(wTx+b)=1,就是分界线上面的那些样本。即:

上面的结论用来做SMO算法推导时候用的,选工作集选优化变量的时候用;也可以用来计算b,对于0<αi<C的情况,可以得到b=yi-wTxi,对于满足0<αi<C的所有样本求得的b求均值,就得到最终的b的值。
在尽可能少错分样本的情况下最大化间隔:
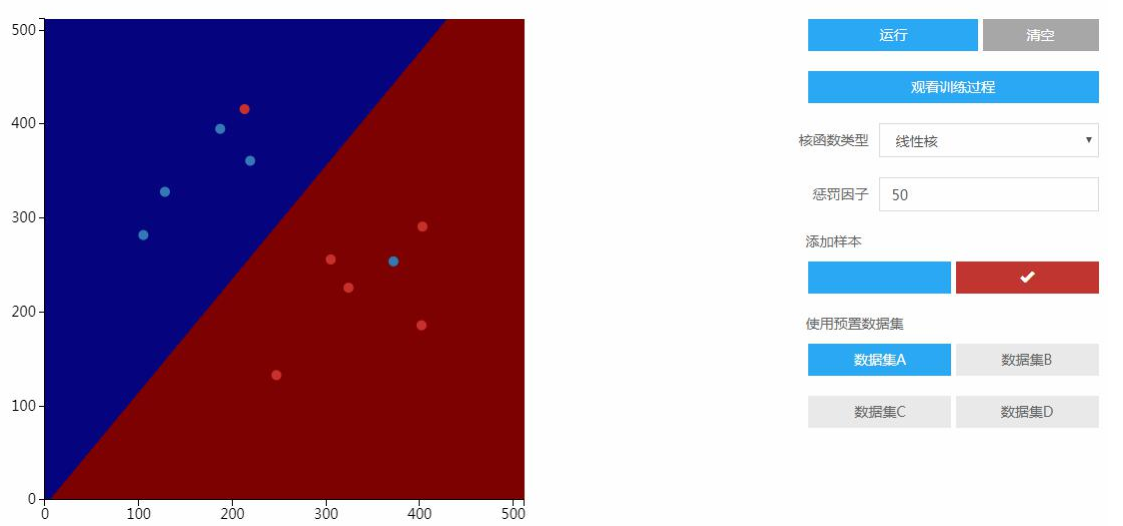
核映射与核函数:
前边通过引入松弛变量和惩罚因子把SVM从线性可分引入到线性不可分的情况,从他的预测函数来看它本质上还是一个线性的模型,只不过允许有错分类样本在,它究竟怎么解决那种线性不可分的问题也让它尽量把样本分正确呢?其中一个技巧就是核函数。
核映射:Φ(x),将x映射到高维空间中去,那样线性不可分的样本集就变成线性可分了。
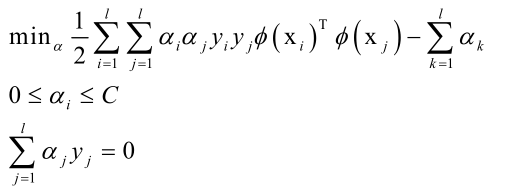
核函数: ,两个向量内积后加个核映射等于分别对向量做核映射再做内积。
,两个向量内积后加个核映射等于分别对向量做核映射再做内积。
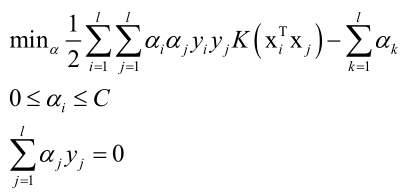
预测函数为:
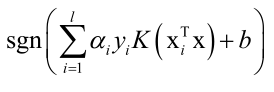
由此看以看出原问题转化成对偶问题求解,可以方便的引入核函数,而原问题就很难引入核函数。引入核函数的对偶问题仍是凸优化问题。因为K一般是一个非线性函数,因此这个时候SVM就是一个非线性的模型。
不是任何一个函数都是可以用来做核函数的,必须满足Mercer条件条件:对任意的有限个样本的样本集,核矩阵半正定。
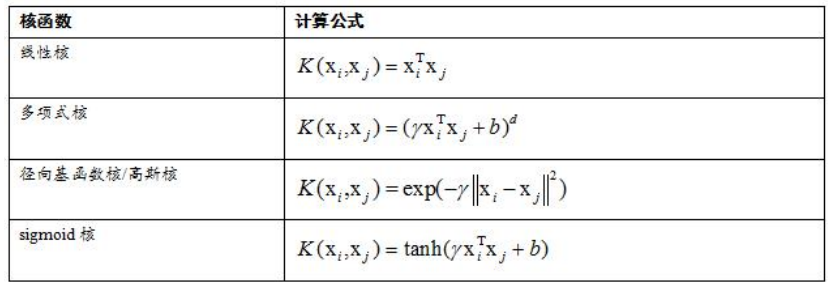
支持向量机之所以能成为一个非线性模型,它的功劳全部归功于核函数,核技巧不光在支持向量机里边是有用的,它在PCA、LDA等其他算法里面都是有用的,它是处理非线性问题的一种手段,它的通用思想是先把向量映射到一个高维空间里边去,然后把一个非线性问题在高维空间里面转化为一个线性的问题来求解。核函数看上去很美好,因为把向量转换到无穷维的空间里边去,所以它的精度还是比较高的,一般在无穷维的空间里边还是线性可分的,但是在实际应用的时候它会面临效率问题,虽然非线性核函数可以提高精度,但是面临计算量大的问题。
本集总结:
下节课推导SVM训练算法