本门课程的基础章节,详细介绍了如何使用tf.keras进行模型的搭建以及大量的深度学习的理论知识。理论知识包括分类问题、回归问题、损失函数、神经网络、激活函数、dropout、批归一化、深度神经网络、Wide&Deep模型、密集特征、稀疏特征、超参数搜索等及其在图像分类、房价预测上的实现。
课程代码的tensorflow版本:
大部分代码是tensorflow2.0的;
课程以tf.keras API为主,因为keras在1.3以后的版本就引入进来了,因而部分代码可以在tf1.3+运行;
另外有少量tensorflow1.*版本代码,这些版本的代码并不能在2.0上运行,因为很多API都已经过时了。
理论部分:
tensorflow-keras简介;
分类问题、回归问题、损失函数;
神经网络、激活函数、批归一化、Dropout;
wide&deep模型;
超参数搜索。
实战部分:
keras搭建分类模型;
keras回调函数;
keras搭建回归模型;
keras搭建深度神经网络;
keras实现wide&deep模型;
keras与scikit-learn实现超参数搜索。
tensorflow-keras简介
keras是什么:
基于python的高级神经网络API,它是一套API,而不是一个完整的库;
Francois Chollet(现在在Google,tf.keras由他来实现)于2014-2015年编写Keras;
keras只是神经网络的API,它不是一个完整的库,它如何去运行呢?他要设置后端,现在tensorflow支持三个后端,有了后端之后,keras才能去运行以Tensorflow、CNTK或者Theano为后端运行,keras必须有后端才可以运行,keras的后端是可以切换的,对于用户来说他只是使用了keras的API,他并不会用到后端里边的东西他不依赖于后端,对于用户来说切换后端对于他使用keras没有任何的影响,自从tensorflow支持了称为keras后端之后,现在大家一般使用以tensorflow为后端的keras;
由于keras它的抽象化做的比较好,所以极方便于快速实验,帮助用户以最少的时间验证自己的想法。
tensorflow-keras是什么:
是tensorflow内部对keras API规范的又给实现;
他和以tensorflow为后端的keras其实是两码事,因为这一套keras API规范的是直接是现在tensorflow上的,就是这套API和tensorflow结合更加的紧密;
实现在tf.keras空间下,所以说tensorflow keras和tf.keras是一个类似的概念。
tf-keras和keras联系:
基于同一套API,都是keras定义的那一套API,因为是同一套API,所以keras程序可以通过改导入方式轻松转为tf.keras程序,反之对于tf.keras的代码要想改成keras的代码可能不一定能够成立,因为tf.keras有一些其他的特性的东西,因为tf.keras种的keras和tensorflow结合的更加紧密,如果之前用过keras的话,可以很轻松的转到tensorflow-keras上来;
他们的规范是一样的,他们的模型导出的规范也是一样的,相同的JSON和HDF5模型序列化格式和语义。
tf-keras和keras区别:(就是tf-keras他和tensorflow的联系更加的紧密,具体紧密在以下方面)
tf-keras全面支持eager mode,只是用keras.Sequential和keras.Model时没影响,自定义Model内部运算逻辑的时候会有影响(Tf底层API可以使用keras的model.fit等抽象,更适用于研究人员尝试自己的想法);
Tf.keras支持基于tf.data做为数据的输入;
tf.keras支持TPU训练;
tf.keras支持tf.distribution中的分布式策略;
其他特性(tf.keras可以与tensorflow中的estimator预估器相集成,tf.keras可以保存为SavedModel,保存为tensorflow中的SavedModel之后呢就可以利用tensorflow的那种跨平台的优势可以把这个model部署到各种各样的平台上去,这是tf.keras的一些优势)。
是使用keras还是使用tf.keras,如何选择?
如果想用到tf.keras中的任何一个特性,那么选用tf.keras;
如果后端互换性很重要,那么选用keras;
如果都不重要,那随便。
分类与回归问题
本节课要解决的两个问题,分类问题与回归问题。
分类问题预测的是类别,模型输出是概率分布,三分类问题输出例子:[0.2, 0.7, 0.1]。
回归问题预测的是值,模型的输出是一个实数值。
为什么需要目标函数?
参数是逐步调整的;
目标可以帮助衡量模型的好坏。
分类问题的目标函数:
需要衡量目标类别与当前预测的差距(三分类问题输出例子[0.2, 0.7, 0.1],三分类真实类别2->one_hot->[0, 0, 1]);
one-hot编码,把正整数变为向量表达(生成一个长度小于正整数的向量,只有正整数的位置处为1,其余位置都为0);
平法差损失1/nΣ1/2(y-Model(x))2;
交叉熵损失1/nΣyln(Model(x))。
回归问题的目标函数(比分类问题简单,因为输出是一个值而非分布):
预测值与真实值的差距;
平方差损失;
绝对值损失。
有了目标函数之后,怎么求解模型?
模型的训练就是调整参数,使得目标函数逐渐变小的过程,这就是目标函数的一个作用。
实战:
keras搭建分类模型、keras回调函数、keras搭建回归模型。
使用keras搭建分类模型
数据读取与展示:
模型构建:
模型数据归一化:
实战回调函数
当训练模型的时候,中间可能要做一些事情。
EearlyStopping是当你的模型训练,它的loss不再下降的时候,可以提前把它给停掉。

看它的参数,最主要的是前三个,monitor是我要关注的是哪一个指标,一般情况下我们关注的是验证集上的目标函数的值,min_delta是一个阈值,我这次训练和上次训练的目标函数值的差距是不是比这个阈值要低,如果比这个阈值高的话,就不用earlyStopping,如果比这个阈值低的话可能就要考虑把它提前停止掉,patience是前后两次目标函数值的差距比mind_delta小的时候,我连续多少次发生这样的情况,我就要把它先关闭掉。
ModelCheckpoint是所有参数的中间状态,可以在训练过程中每隔一段时间把point给保存下来。
TensorBoard是tensorflow中的一个非常重要的工具,一般是模型训练完之后,才把模型训练的指标随着训练迭代次数的推进而变化的一个趋势图才能打印出来,有了TensorBoard,我们在模型训练过程中我们就可以做这样的一个事情,而是它是一个非常自动化的一个工具,还非常的好用。
调模型花费的时间要比建模型的时间要多得多,这也就是TensorBoard出现的意义。
加上回调函数的训练函数,训练完模型之后,会发现指定的文件夹下生成输出模型文件、train和validation文件夹下是TensorBoard的文件:
然后命令行tensorboard --logdir="callbacks",其中callbacks是当前文件夹下回调函数TensorBoard的文件夹,然后会自动创建一个本地的tensorBoard服务器,端口号6006,在浏览器中打开即可。
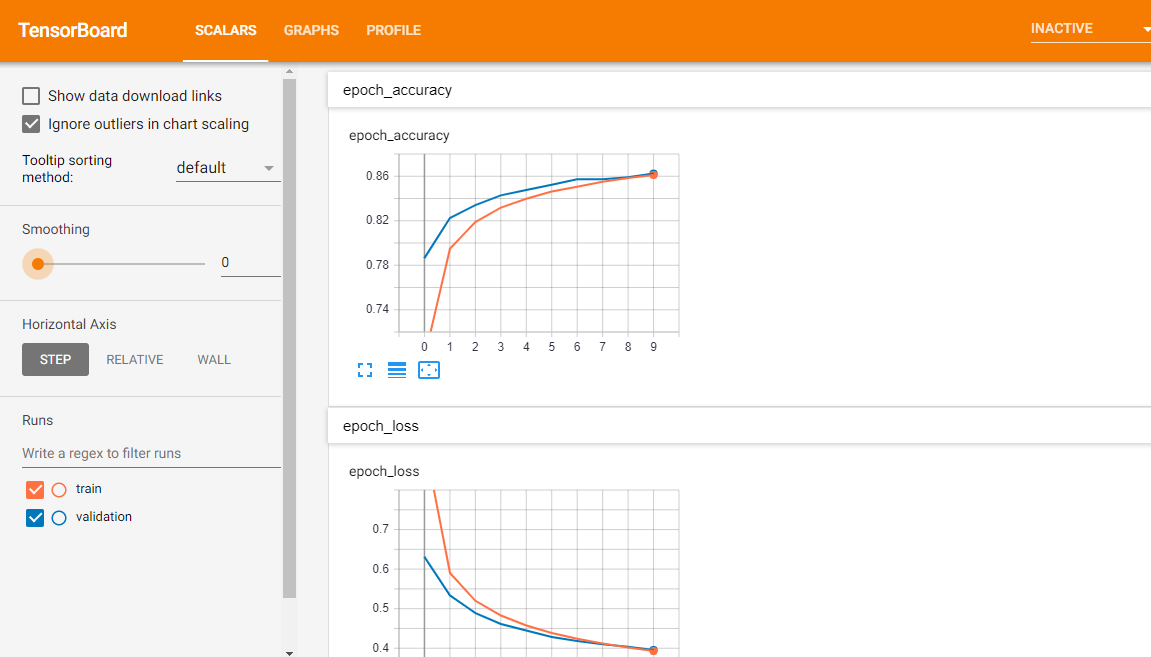
上边是精确度,下边是目标函数趋势图,红线是训练集的,蓝线是验证集的。
GRAPHS是定义的模型的结构。
PROFILE是记录内存和CPU的使用量的,没有记录就没有数据。
神经网络讲解
激活函数:
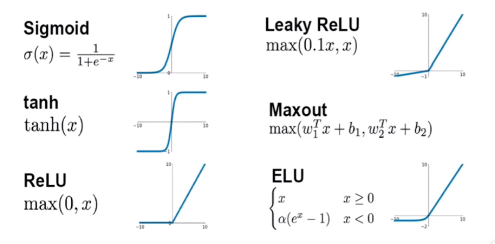
归一化:
Min-max归一化:x* = (x-min)/(max-min)
Z-score归一化:x* = (x-μ)/σ
批归一化:
把归一化从输入数据扩展到每层的激活值上,因为每一层的输出都是下一行的输入,所以把每层激活值都归一化。
为什么归一化有效?

未归一化的theta1、theta2范围是不一样的,所以等高线(在该线上目标函数值相等)看起来是一个椭圆,在椭圆上计算梯度的时候,它指向的不一定是圆心,导致训练轨迹曲折走一些弯路才能到圆心点。
归一化的等高线是正圆,法线方向指向圆心,所以训练速度会更快。
什么是dropout?
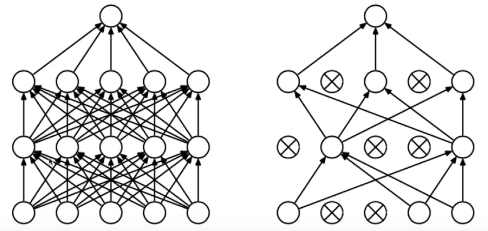
随机把一些神经单元给弃用掉,令一些参数为0,每次训练弃用的神经单元是不一样的。
dropout的作用:
防止过拟合,模型参数太多,记住样本,泛化性能差。任意的两个节点并不能再组合的去学习一些东西了,而是说每个节点独立的去学习数据中的规律,这样就防止记住样本的这种事情发生,防止过拟合。
然后开始新一轮的实战:
keras实现深度神经网络;keras更改激活函数;keras实现批归一化;keras实现dropout。
实战深度神经网络
导致图像前期不怎么变化的原因:
1.参数众多,初期训练不充分
2.梯度消失
梯度消失:
梯度下降就是给每个参数求解它的导数,然后让这个参数在它的导数方向上做一定量的更新,这是梯度下降的思想。梯度消失就是,对于一个多层次的神经网络来说,离目标函数比较远的底层神经网路,它的梯度比较微小的现象就叫做梯度消失。
梯度消失一般发生在深度神经网路里,它发生的原因主要是链式法则,梯度在一层层的传导的时候,由于它前边的系数太多,有可能会导致梯度消失的问题存在。所以会导致刚开始训练的时候图像变化会比较平缓。
实战批归一化、激活函数、dropout
批归一化缓解梯度消失:批归一化使每一层的值更加的规整,从而使得导向更加精准,可以在一定程度上缓解梯度消失。
dropout:
一般只给最后几层添加dropout,不给每一层都添加dropout,dropout是用来防止过拟合的。dropout实现方法在keras中和其他layer一样,也把dropout也实现为一个layer,在layer后添加dropout layer就相当于给前边一层做了dropout。
wide&deep模型
16年,用于分类和回归。应用到了Google play中的应用推荐。原始论文:https://arxiv.org/pdf/1606.07792v1.pdf。
他把信息用稀疏特征和密集特征来表示,然后基于这两种特征去构建模型
稀疏特征:
离散值特征(在众多值中只取其中一个);
one-hot表示;
如,计算机专业={1,0,0}(专业有计算机、人文、其他);
叉乘={(计算机,数据结构),...};
叉乘之后,稀疏特征做叉乘获取共现信息,实现记忆的效果。
稀疏特征的优缺点:
优点是广泛用于工业界,缺点是需要人工设计所有特征、可能过拟合、泛化能力差。
密集特征:
向量表达,如计算机=[0.3, 0.2, 0.6];
典型的应用word2vec,与训练好的将词语转化为向量的一个工具,可以把一个词转化为向量,通过向量之间的距离衡量词语之间的距离,如男-女 = 国王-王后。
密集特征的优缺点:
优点是带有语义信息,不同向量之间有相关性,兼容没有出现过的特征组合,更少人工参与,缺点是过度泛化,推荐不怎么相关的产品。
wide模型和wide&deep模型:
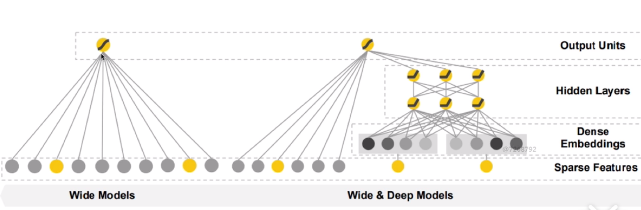
wide模型的输入是one-hot向量。wide&deep模型左边是wide模型,右边是deep模型,deep模型是把输入先转化为一个密集的向量表达,再经过一个多层的全连接神经网路,之后再连到输出上去,下边是稀疏特征、再上边是密集特征(稀疏特征的一个密集向量的表达)、再往上是隐含层、输出单元。相对于wide模型,wide&deep模型多了两个层次。
deep模型和wide&deep模型:

所以说,wide&deep模型是把wide和deep模型组合起来的一个模型。
Google play中的应用推荐模型:
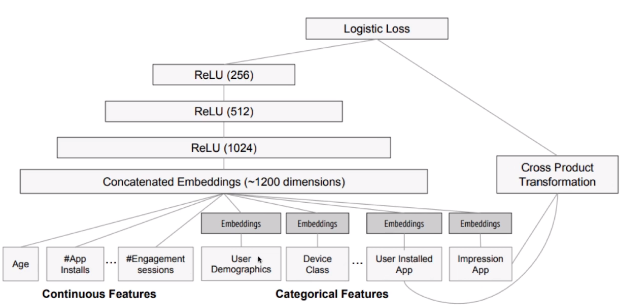
左边是deep模型,右边是wide模型。
实战:
tf.keras中的子类API实现wide&deep模型;功能API(函数式API);多输入与多输出。
函数API实现wide&deep模型
采用回归问题实现wide&deep模型,因为房价预测回归问题中有8个特征,可以很轻松的把这8个特征划分成给wide模型用的、给deep模型用的。而对于图像分类来说,这种划分没有什么意义,因为图像中的特征它们的价值都是一样的,而对于房价预测中的特征它们的价值是不一样的,所以房价预测问题更适合wide&deep模型的实现。
子类API实现wide&deep模型
wide&deep模型的多输入与多输出
真正的wide&deep模型中的,wide、deep模型的输入往往是不一样的。
多输出主要针对多任务问题,比如除了预测当前的房价,还要预测1年后的房价,那么这就有了两个预测任务,我们就需要给出两个结果。
超参数搜索
为什么要超参数搜索?
神经网路有很多训练过程中不变的参数(网络结构参数:几层,每层宽度,每层激活函数等;训练参数:batch_size,学习率,学习率衰减算法等),手工去试耗费人力,所以需要超参数搜索找到最合适的超参数。
搜索策略:
网格搜索;
随即搜索;
遗传算法搜索;
启发式搜索。
网格搜索:

定义n维方格,每个放个对应一组超参数,一组一组参数尝试。
如图,dropout设置四个值,learning rate设置四个值,相互组合形成16个值,然后把16个值放到不同的机器上并行执行,找到最好的组合方式,这就是网格搜索。
随即搜索:
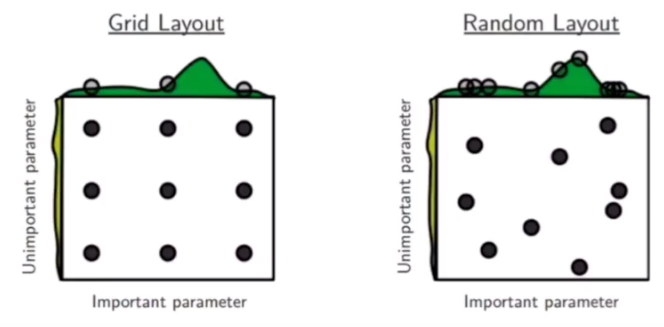
参数的生成方式为随机,可探索的空间更大。
对于网格搜索,只能取固定的一些值,最优解可能存在于中间某个值,可能用网格搜索永远都找不到最优值,所以随即搜索产生,即随机的参数值组合。
遗传算法:
对自然界的模拟,A、初始化候选参数集合->训练->得到模型指标作为生存概率,B、选择->交叉->变异->产生下一代集合,C、重新到A。
启发式搜索:
是研究热点-AutoML中的一部分,使用循环神经网路来生成参数,使用强化学习来进行反馈,使用模型来训练生成参数。
手动实现超参数搜索
还是选用房价预测的回归问题来进行超参数搜索实验,因为房价预测数据集比较小,对于超参数搜索这样耗时的任务更易于展示。
由于这种手动实现,如果超参数过多,则循环层数变多,而且每组参数顺序执行,没法并行,效率低,所以可以借助一些库来实现。
sklearn封装keras模型,实现超参数搜索
RandomizedSearchCV实现超参数搜索
1.tf的model转化为sklearn的model。
2.定义参数集合
3.RandomizedSearchCV搜索参数
先定义好一个tf.keras的model,然后调用一个函数去把tf.keras的model给封装成一个sklearn的model。这个封装函数在API中可以查到,在tf.keras下的wrapper下的scikit_learn下。
可以把tf.keras定义好的model转化为sklearn支持的一个model。
参数build_fn是搭建好的tf.keras的model。