scrapy是一个爬虫框架,而beautifulsoup、urllib、requests等是爬虫库,框架和库不同之处在于,库拿过来然后到你的工程里边直接写,框架他会自动的帮你做很多事,你到框架里边去填充你这些东西,那就够了。
首先创建scrapy工程,命令行输入命令,命名为stock_spider的一个工程:
scrapy startproject stock_spider
创建好之后,用pycharm的File->open打开该工程在一个pycharm中。
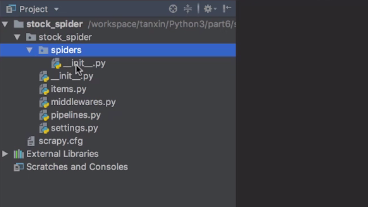
scrapy框架的基本目录:(建好scrapy项目之后,会自动生成一些文件。 )
spiders这个包下就是我们真正写爬虫的地方,items.py里边会定义一些变量,这些变量对应爬虫要爬取的数据,pipelines.py是处理我们数据的一个类,settings.py包含一些配置。
有了scrapy项目之后,首先要创建一个名字叫tonghuashun的爬虫,命令行:
scrapy genspider tonghuashun 具体爬虫的URL
这样就创建了一个爬虫,在spiders包下就自动生成了一个tonghuashun.py这样一个文件。
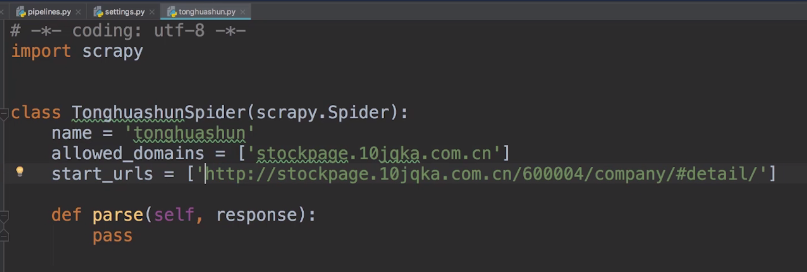
parse是解析start_urls中得到的数据,可以用xpath、css选择器等方式回去网页中的标签元素信息,如response.xpath(...)用标签的xpath方式筛选标签。
然后怎么运行程序呢?
在stock_spider下新建一个main.py文件,然后在其中写上程序所在的路径,然后执行程序。
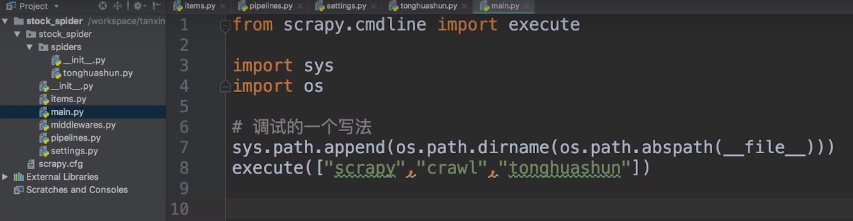
然后运行main.py文件,即可执行到tonghuashun.py中的parse函数代码。
每次调试xpath定位元素的时候都需要运行一次工程吗?如何快速调试?
命令行调试,scrapy shell是scrapy爬虫交互的工具,可以很直观的反馈元素是否定位到:
scrapy shell 网页URL
进入crapy shell,然后可以用response.xpath(...)选择元素并输出结果,验证是否正确选择了标签。
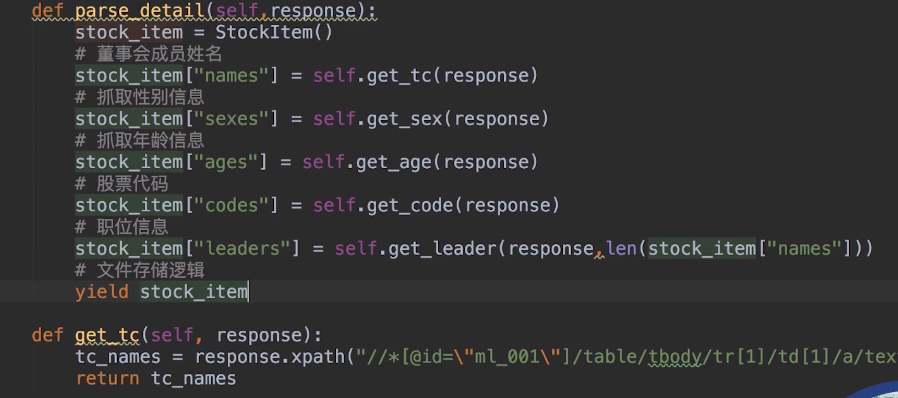
然后在parse函数中解析网页数据,然后在其中可以再设置回调函数爬取详情页的内容:
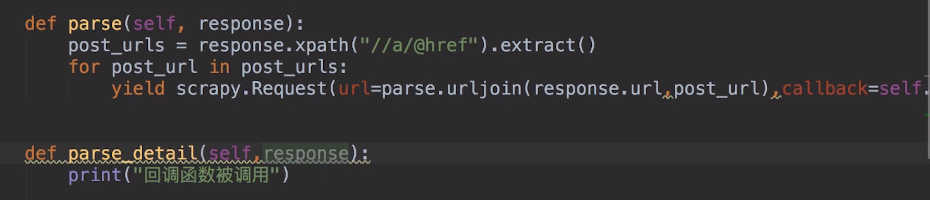
在信息抓取完之后,该处理信息了,pipelines.py就是处理数据、存储数据的。
怎么把pipelines.py的逻辑和爬虫tonghuashun.py的逻辑给关联上呢,就需要items.py,在items.py中写上爬虫tonghuashun.py中爬取的数据变量:
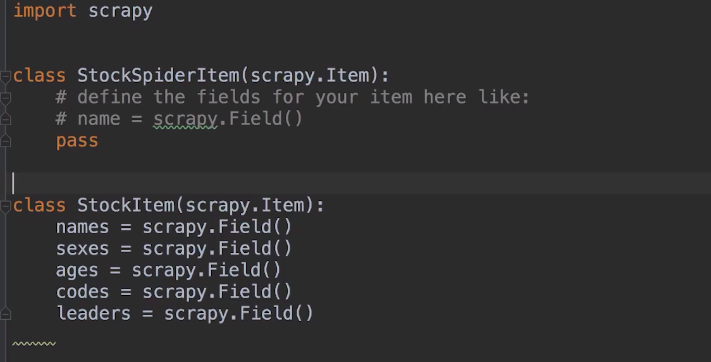
之后在爬虫tonghuashun.py的parse_detail函数中声明一个刚才那个items.py中的类,
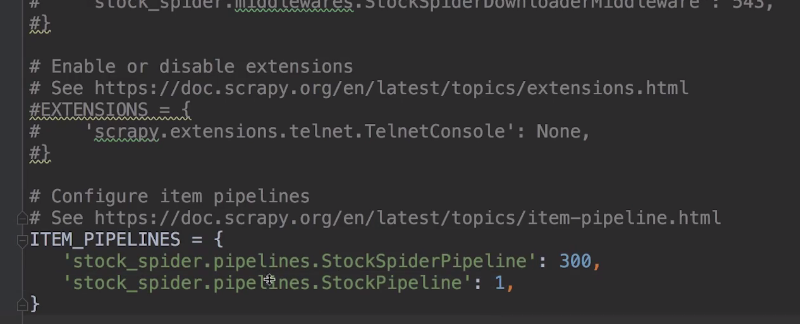
然后在setting.py中再设置一下,才能让tonghuashun.py中爬取的数据送到pipelines.py当中:
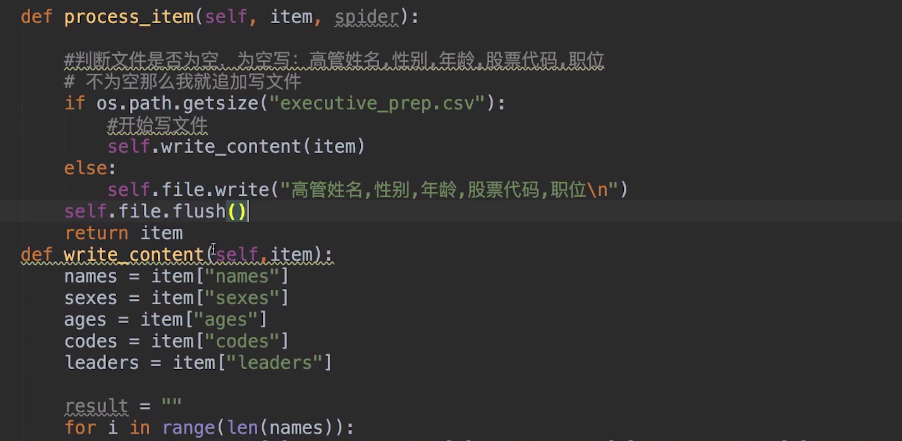
然后开始pipelines.py进行数据处理,讲数据从item中取出来一一处理,存储到文件当中将数据持久化:
笔记来源:https://www.bilibili.com/video/av36440906?p=67