讲授语音识别问题简介、GMM-HMM框架、RNN-CTC框架、深层网络等。
大纲
语音识别问题简介
语音识别问题的抽象
传统的语音识别算法
神经网络在语音识别中的早期应用
RNN+CTC方案
本集内容简介
接下来两节课,我们会介绍RNN它具体的应用,今天这节课介绍它在语音识别里边的应用,下节课介绍它在NLP里边的应用。
今天这节课会讲解下面这些内容,首先介绍语音识别它的一个简单的介绍,我们语音识别要解决一个什么样的问题,它面临什么样的困难,再接下来为语音识别这个问题建立一个抽象的数学模型,也就是把我们要求解的模型数学化、抽象化,再接下来我们会介绍传统的语音识别算法,主要是GMM+HMM,即高斯混合模型加上隐马尔科夫模型的这种算法,接下来重点介绍神经网络它在语音识别中的应用,分两个阶段,第一个是早期阶段的算法,第二个阶段是CTC这个方案出来以后,它实现了真正意义上的端对端的训练和预测。
语音识别问题
下面我们来看语音识别它到底要解决什么问题,即给定一段波形的信号,我们要把它转化成文字,即把说话的声音转化为文字序列,所以说它本质上是一个分类问题,即每段信号它是属于哪个文字的,是一个多分类问题。
和普通的模式识别,如前边讲的图像识别不一样,语音识别它是一个序列的分类问题即序列预测问题,因为这个信号是随着时间变化的,而之前说的图像分类或其他的样本分类或预测,它就是一个图像或向量X,我们预测一次就可以了,但是我们的声音它不一样,它是随着时间变化的一个数据,它是沿着时间轴走的一个数据,而且不同时间点之间的信号值之间是有关系的,因为这句话它要符合我们的语义规则和要表达的意思是相关的,而前边我们说的图像识别之类的识别,人工神经网络的时候,输入两张图像x1和x2分别进行预测,它们两个之间是没有任何关系的,和这个有本质的区别。
根据我们上节课讲的序列标注问题里的三种类型,我们的语音识别属于段分类问题,也就是说有一个很长的输入序列有一个短很多的输出序列,然后输入序列中的某一些序列值要把它映射为输出序列里边的一个值,也就是把一段输入信号映射成一个输出信号。
语音识别困难在,给的一段波形它是没有分割好的,就是说每一个字对应声音信号中的哪一段我们是不知道的,也就是说对齐关系是不知道的,因此这个问题是非常麻烦的,但是一旦这个关系知道以后,其实就是一个多分类问题,把一段声音信号映射为一个文字就可以了,这就是多分类,提取某一段声音信号映射为某个文字就可以了。
问题的抽象
下面看语音识别是怎么做的。
首先将声音信号分成时间长度很短的帧,比如20ms,因为我们并不知道信号中哪一段对应哪一个文字,因此要把信号分的足够细也可以,比如说很多帧都是一个字,这些帧之间有一部重叠,这样才能保证提出来的数据是连续的。
对每个帧计算出一个固定长度的特征向量,得到一个向量序列,这样就把声音信号抽象为了一个向量序列,选择什么样的特征呢?经典的MFCC特征,它是先对声音信号进行傅里叶变换FFT,根据这些变换系数来构造一些特征,最后就变成了对抽象后的向量序列预测问题了,即从向量序列到向量序列的映射问题,输入是帧的特征向量序列,输出是文字序列。
经过前边的抽象,我们的语音识别问题可以转化为数学中的极大值问题argmaxwp(w|x),给定输入序列x(x1,...,xT),然后预测出一个输出序列来w1,...,wT'即文字序列,具体就是找出条件概率最大的那个序列。
根据贝叶斯公式有

p(w|x)本身是一个后验概率,即根据声音推文字的概率,他们的因果关系是只有文字才能造出对应的声音来,但是分类的时候是已知声音反推出对应的文字,和前边讲的贝叶斯分类器是一样的。p(x|w)称为先验概率,就是我们人的经验是已知的,即要发出我这个声音的话它就必须是某个波形,这是已知的。p(w)中的w一般是指一句话,即一个词的序列。对于分类问题,p(x)和w无关,可以把它去掉,最后求解argmaxwp(w|x)这样一个极大值就OK了,p(x|w)称为声学模型,即已知文字序列产生这样一个声音序列x的概率,p(w)称为语言模型,即这句话出现的概率,比如天今气好这句话出现的概率几乎为0。p(x|w)是狭义的语音识别要完成的任务,研究每个字词它发出什么的声音来,p(w)是属于语言学的范畴,即这句话是否合法,它出现的概率有多大。
实际例子
前边说的抽象,举个实际例子。
假设要识别下面这句话:“我是中国人”,
首先对这句话的语音信号进行分帧,得到这些帧的特征向量序列,
接下来用声学模型将这个特征向量序列识别成声母和韵母组成的拼音序列:
wo shi zhong guo ren
接下来用语言模型将这个拼音序列转化成最终的文字系列:
我是中国人。
由于一个发音对应很多字,所以用语言模型解决把真正有意义的那个字词找出来。
声音模型把声音信号转化为音素,然后语言模型再把这些音素转换成文字。
GMM-HMM框架
在介绍了语音识别的一般的处理流程以后,我们接下来再介绍一下传统经典的语音识别算法,最典型的就是GMM+HMM框架。
首先对声音信号进行分帧,每帧包含一段很短时间的语音信号,这些帧之间会有时间上的重叠。
然后为这些帧做傅里叶变换,根据变换系数取计算这段信号的MFCC特征,得到每个帧为12维的特征向量。
一段语音信号被变换成多个12维的特征 ,其中N为帧数。这个特征向量序列可以看成是12行N列的矩阵,称为观测序列。
然后就是GMM+HMM要起作用了。
把这些帧识别成一些状态,得到一个状态序列,状态是对基本发音的切分,将若干个状态组合成一个音素,得到一个音素序列,把若干个音素组合成单词或者字,得到最终的识别结果。
音素是基本发音单位。对于英语,是39个音素构成的音素集;对于汉语,是声母和韵母。状态是音素的进一步切分,即一个音素由多个状态组成。 声学模型是对发声的建模,给出了语音属于某个声学符号的概率。
语言模型的作用是在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
从帧到音素的转换由高斯混合模型完成。通过它可以得到帧属于某一观测的概率。得到观测概率之后,接下来的工作由隐马尔可夫模型完成,即由观测序列得到状态序列。
得到12×N的观测序列是由GMM来完成的,由观测序列转成状态序列是由HMM来完成的,接下来再把这些状态合并掉,得到最终的发音单位即因素,这完成之后声学模型就完成了。接下来就根据这些发音单位找出概率最大的文字序列,这是由语言模型完成的任务。
神经网络早期在语音识别的应用
接下来介绍一下深度学习在语音识别中的应用,深度学习最早用于语音识别问题的时候,它是替代高斯混合模型和HMM中的高斯混合模型,负责声学模型的建立,这种结构称为DNN-HMM结构,如果感兴趣可看下边几篇论文:
Jaitly, Navdeep and Hinton, Geoffrey E. Learning a better representation of speech sound waves using restricted boltzmann machines. In ICASSP, pp.5884-5997, 2011.
Abdel-Hamid, Ossama, Mohamed, Abdel-rahman, Jang, Hui, and Penn, Gerald. Applying convolutional neural networks concepts to hybrid nn-hmm model for speech recognition. In ICASSP, 2012.
Sainath, Tara N., rahman Mohamed, Abdel, Kingsbury, Brian, and Ramabhadran, Bhuvana. Deep convolutional neural networks for LVCSR. In ICASSP, 2013.
A. Mohamed, G.E Dahl, and G. Hinton. Acoustic modeling using deep belief networks. Audio, Speech, and Language Processing, IEEE Transactions on, vol. 20, no.1, pp.14-22, jan. 2012.
G. Hinton, Li Deng, Dong Yu, G.E.Dahl, A.Mohamed, N.Jaitly, A.Senior, V.Vanhoucke, P.Nguyen, T.N.Sainath, and B.Kingsbury.
Deep Neural networks for acoustic modeling in speech recognition. Signal Processing Magazine, IEEE, vol.29, no.6, pp.82-97, nov.2012.
比如说RBM受限玻尔兹曼机、CNN、DeepCNN等等好多的神经网络都被用来做语音识别使用,但是这些改造都不彻底,他都只是替代了其中的一部分,并没有把HMM给干掉,更完整的一个做法就是把整个GMM+HMM干掉,实现一个端对端的序列,输入就是一段语音信号的特征向量x1,...,xT,输出是一些发音单位因素值,这样就完成了真正意义上的识别,最后就加一个语言模型就可以了,根据发音确定是哪一个文字就可以了,更彻底的是把语言模型也干掉,直接得到文字。
RNN-CTC框架
在上一节课里边我们介绍了连接主义时序分类CTC,它最经典成功的应用就是用来解决语音识别问题,该算法在2006年时就已经被提出来了,它主要是解决对齐问题,就是声音信号的波形哪一段波形对应的是哪一个文字我们是不知道的,这时就可以用CTC来解决,而且它解决的另一个问题就是这些静音状态可以直接拿来训练,不用把它裁剪出来,它怎么做的呢?也是先分帧,然后把得到的向量序列x1,...,xT依次送到RNN中预测一遍得到原始的输出值y1,...,yT,最后一层用的时softmax回归,可以认为是一个帧它属于每个发音的概率有多大,这里边除了声母韵母以外它加了一个空白blank类型,这样就把它转化为一个多分类问题了,即得到多个概率向量,T个时刻的概率向量都输出来了,每个分量即yti表示t时刻这个帧它属于第i个发音单位的概率值,即t时刻softmax回归的yt这个向量的第i个分量就表示它属于第i类的概率值。
Alex Graves, Santiago Fernandez, Faustino J Gomez, Jurgen Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks.international conference on machine learning. 2006
再接下来我们把这些空白符号给干掉,再把相邻的相同类别合并掉。
RNN-CTC框架的原理
前边讲CTC原理时说过,给定一个输入序列x,CTC中的RNN它最原始的输出就是路径Π,即多个softmax回归的结果y1,...,yT,yti表示t时刻属于第i个类的概率值,最终要识别出来的结果是l即发音单位序列,l是怎么得到的呢?根据RNN原始输出Π,做了去重、合并,合并是通过B函数将相邻相同的合并,然后再去空白符就得到了l。
但是能得到最终序列l对应的x有很多条,因此暴力来算p(l|x)还是挺复杂的,然后有一些高效的计算方法,若感兴趣可查相关论文与资料。
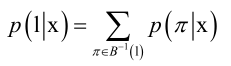
总之,语音识别时,CTC分类器最后的输出即概率值最大的标签序列和前边讲的seq2seq是一样的原理,这时候CTC网络只能对X->l进行打分,即已知x再给定一个l计算x得到l的概率,但是l取什么值时最大呢?这个运算成本是相当高的,因为它只提供了这样一个评分机制即已知x、l的情况下估计出一个概率值来,但是现在最优的l是未知的,怎么算最优的l呢?可以采用前缀搜索技术。
总结一下,将深度神经网络用于语音识别以后,它可以实现端到端的学习,也就是说,我们的训练样本,它就是一段语音信号提出来的FMCC序列即x1,...,xT,它的标签序列是这句话它代表了是哪些字母或词,把这些标注好了就可以直接拿去训练了,而不需要人工再去分割告诉你哪段声音是哪个字或词了,因此这是非常省人力的,而且这样做精度上也会提高,因为人工分割它会有误差而且有时分的不太准。
具体怎么实现的呢?它的RNN一般采用双向LSTM即BLSTM网络。
训练样本集的音频数据被切分成10毫秒的帧,其中相邻帧之间有5毫秒的重叠,使用MFCC特征作为循环神经网络的输入向量。
原始音频信号被转换成一个MFCC向量序列。特征向量为26维,包括了对数能量和一阶导数值。向量的每一个分量都进行了归一化。
RNN就根据这些值算出一个路径Π来,再根据前缀编码搜索技术把这个序列里边最有可能的那条路径即概率最大的那条路径找出来,这就是我们语音识别最后得到的结果l,这就是CTC用来做语音识别的原理。
深层网络
刚才介绍的是2006年的CTC的文章,其实是在深度学习火起来之前就已经有了CTC,但是那时候没有引起足够的重视,后来在2013年时还是同样的一批人又重新发了一篇文章重新对这个方法进行了改进,主要改进是用双向的深度双向RNN,以前的神经网络很浅,这时改成深度网络来做训练,输入的数据还是声学的数据x,输出值是因素序列y,它训练时是算L=-logp(z|x),即最后要的标签序列和输入序列的对数似然函数,计算p(z|x)只需把每个时刻的softmax回归值相乘,即可写成连乘p(yi|x),然后取log,变成-Σlog(p(yi|x)),每个时刻的损失函数还是一个交叉熵损失。
A. Graves, A.Mohamed, G. Hinton, Speech Recognition with Deep Recurrent Neural Networks, ICASSP 2013
虽然只是改成深度网络,但是精度的提升还是非常大的,从这篇文章以后,CTC+RNN的方案逐渐成为语音识别的主流方案了,后边的那些工作基本上都是在这个基础上做了一些改进,总体的框架还是这样一个框架,CTC这种技术很巧妙的解决了语音识别里边边界难以分割的问题,即每个字、词边界在什么地方和静音的空白符这两个问题同时解决掉了。
本集总结
首先介绍了语音识别的概念,它要解决什么问题,存在什么样的困难,主要是数据没有对齐。
接下来我们对这个问题进行了抽象,抽象为一个概率问题求一个概率的极值问题,然后通过贝叶斯公式可以转换过来,进一步把这个问题拆分成两个问题,即声学模型和语言模型。
再接下来介绍了语音识别它解决问题的一般的整体流程。
然后介绍了传统的方法GMM+HMM的框架。
再接下来介绍了CTC的框架,然后介绍了对CTC的改进,主要是把网络用深度的双向LSTM弄深了一些来解决语音识别问题,后边的算法就不细讲了,其实就是在这个基础之上做了一些改进,不会有一个特别大的区别。