tensorflow中的数据集类Dataset有一个shuffle方法,用来打乱数据集中数据顺序,训练时非常常用。其中shuffle方法有一个参数buffer_size,非常令人费解,文档的解释如下:
buffer_size: A tf.int64 scalar tf.Tensor, representing the number of elements from this dataset from which the new dataset will sample.
你看懂了吗?反正我反复看了这说明十几次,仍然不知所指。
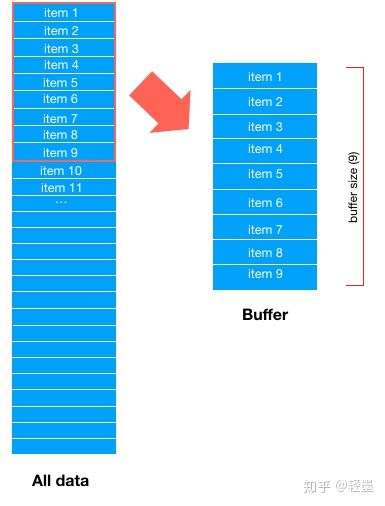
首先,Dataset会取所有数据的前buffer_size数据项,填充 buffer,如下图
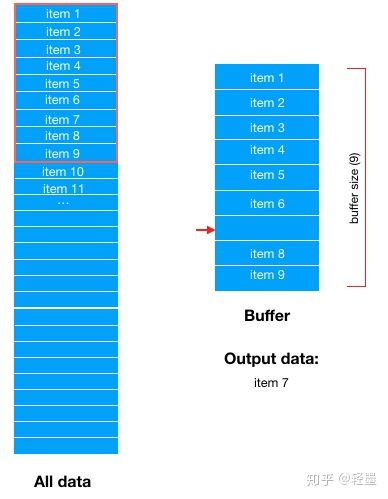
然后,从buffer中随机选择一条数据输出,比如这里随机选中了item 7,那么buffer中item 7对应的位置就空出来了
然后,从Dataset中顺序选择最新的一条数据填充到buffer中,这里是item 10
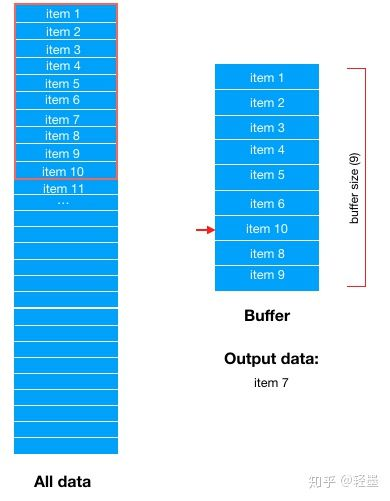
然后在从Buffer中随机选择下一条数据输出。
需要说明的是,这里的数据项item,并不只是单单一条真实数据,如果有batch size,则一条数据项item包含了batch size条真实数据。
shuffle是防止数据过拟合的重要手段,然而不当的buffer size,会导致shuffle无意义。
原文:https://zhuanlan.zhihu.com/p/42417456
也就是说,buffer_size的作用就是存放数据集中部分数据的缓冲区大小,每次取数据是从缓冲区中随机取出一个item,该item是一个batch,取出后再拿数据集中未在缓冲区出现过的数据(依次)去填充该缓冲区的空缺位置。
例子:
# 定义一个dataset类型的对象
dataset = tf.data.Dataset.from_tensor_slices(np.array([1, 2, 3, 4, 5, 6, 7]))
# 对数据打乱,设置缓冲区大小为4
dataset = dataset.shuffle(4)
for ele in dataset:
print(ele.numpy())
# 对数据进行重复,每一次都是乱序的,参数为重复的次数,如果不写默认无限次重复
dataset = dataset.repeat(count=3)
for ele in dataset:
print(ele.numpy())
# 取出batch_size大小的数据
dataset = dataset.batch(3)
for ele in dataset:
print(ele.numpy())
上边的代码解释:
定义一个dataset,然后定义缓冲区为4。由于repeat了3次,所以之后dataset中依次存放三个打乱的1234567,每个的乱序不同。设置了batch_size之后,dataset中的元素为每batch_size个数组成的数组,数组类型是numpy的ndarray,再从dataset中取数据就是每次取一个batch,按照缓冲区取数据的原理,则会依次取batch_size个数据。