python中bytes 类型,是指一堆字节的集合,十六进制表现形式,两个十六进制数构成一个 byte ,以 b 开头的字符串都是 bytes 类型。
计算机只能存储二进制,字符、图片、视频、音乐等想存到硬盘上,必须以正确的方式编码成二进制后再存,但是转成二进制后不是直接以 0101010 的形式表示的,而是用一种叫 bytes() 的类型来表示。
bytes是一个字节串,字节串bytes和字符串string的区别:
字符串以字符为单位进行操作,字节串以字节为单位进行操作;字节串和字符串除了操作的数据单元不同之外,它们支持的所有方法都基本相同。
如果采用合适的字符编码方式(字符集),字节串可以恢复成字符串;反之亦然,字符串也可以转换成字节串。
说白了,bytes 只是简单地记录内存中的原始数据,bytes 类型的数据非常适合在互联网上传输,可以用于网络通信编程;bytes 也可以用来存储图片、音频、视频等二进制格式的文件。
字符串转换成bytes的三种方式:
- 如果字符串的内容都是 ASCII 字符,那么直接在字符串前面添加
b前缀就可以转换成 bytes。 - bytes 是一个类,调用它的构造方法,也就是 bytes(),可以将字符串按照指定的字符集转换成 bytes;如果不指定字符集,那么默认采用 UTF-8。
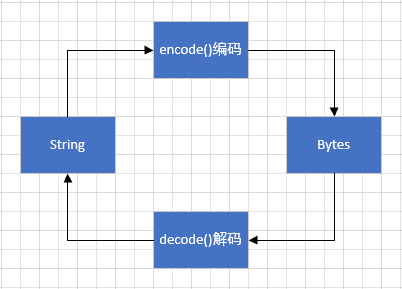
- 字符串本身有一个 encode() 方法,该方法专门用来将字符串按照指定的字符集转换成对应的字节串;如果不指定字符集,那么默认采用 UTF-8。
bytes转换成字符串类型:
调用bytes字节串的decode(编码方式),将字节串解码为对应编码的字符串。
编码&解码:
Example: b'xb9x01xef'.hex() -> 'b901ef'.
将10进制整数转换成16进制,以字符串形式表示,返回的字符串始终以前缀 0x 开头:
>>>hex(255)
'0xff'
将16进制转换为10进制:
>>>int('0x12',16)
18
>>>int('12',16)
18
参考:
http://c.biancheng.net/view/2175.html
https://www.cnblogs.com/lipandeng/p/11162039.html