tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
一:神经网络知识点整理
1.1,多层:使用多层权重,例如多层全连接方式
以下定义了三个隐藏层的全连接方式的神经网络样例代码:
import tensorflow as tf l1 = tf.matmul(x, w1) l2 = tf.matmul(l1, w2) y = tf.matmul(l2,w3)
1.2,激活层:引入激活函数,让每一层去线性化
激活函数有多种,例如常用的 tf.nn.relu tf.nn.tanh tf.nn.sigoid tf.nn.elu,下面显示了几种常用的非线性激活函数的函数图像:
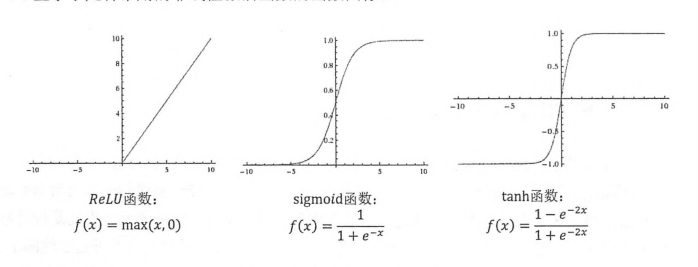
样例代码:
import tensorflow as tf a = tf.nn.relu(tf.matmul(x, w1) + biase1) y = tf.nn.relu(tf.matmul(a, w2) + biase2)
1.3,损失函数
经典损失函数,交叉熵(cross entropy)用于计算预测结果矩阵 Y 和实际结果矩阵 Y_ 之间的距离样例代码:
import tensorflow as tf cross_entropy = - tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
import tensorflow as tf v = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) tf.reduce_mean(tf.clip_by_value(v, 0.0, 10.0))
对于分类问题,通常把交叉熵与softmax回归一起使用
import tensorflow as tf cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)
对于回归问题,通常使用mse(均方误差函数)计算损失函数
import tensorflow as tf mse_loss = tf.reduce_mean(tf.square(y_ - y)) # 与以下函数计算结果完全一致 dataset_size = 1000 mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / dataset_size
自定义条件化的损失函数
import tensorflow as tf loss_less = 10 loss_more = 1 loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less)) train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
1.4,神经网络优化算法,训练优化器
一般优化器的目标是优化权重W和偏差biases,最小化损失函数的结果,以下优化器会不断优化W和 biases。
Adam优化算法是一个全局最优点的优化算法,引入了二次方梯度校正,相比于基础SGD算法,不容易陷入局部优点,而且速度更快。
本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。

import tensorflow as tf LEARNING_RATE = 0.001 mse_loss = tf.reduce_mean(tf.square(y_ - y)) train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(mse_loss)
1.5,优化学习率LEARNING_RATE
在训练神经网络时,需要设置学习率(learning rate)控制参数更新的速度,学习率决定了参数每次更新的幅度,学习率设置过大可能导致无法收敛,在极优值的两侧来回移动。学习率设置过小虽然能保证收敛性,但可能导致收敛过慢。
为了解决学习率的问题,Tensorflow 提供了一种更加灵活的学习率设置方法——指数衰减法。tf.train.exponential_decay 函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减少学习率,使得模型在训练后期更加稳定。exponential_decay 函数会指数级地减少学习率,它实现了一下代码的功能:
decayed_learning_rate = learning_rate * decay_rate ^(global_step / decay_steps)
其中 decayed_learning_rate 为每一轮优化时使用的学习率,learning_rate 为事先设定的初始学习率,decay_rate 为衰减系数,decay_steps 为衰减速度。tf.train.exponential_decay 函数可以通过设置参数 staircase 选择不同的衰减方式。
import tensorflow as tf
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
learning_rate=0.1,
global_step=global_step,
decay_steps=100,
decay_rate=0.96,
staircase=True,
name=None
)
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=global_step)
1.6,过拟合问题(正则化)
避免训练出来的模型过分复杂,即模型记住了所有数据(包括噪声引起的误差),因此需要引入正则化函数叠加的方式,避免模型出现过拟合
import tensorflow as tf v_lambda = 0.001 w = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1)) y = tf.matmul(x, w) mse_loss = tf.reduce_mean(tf.square(y_ - y) + tf.contrib.layers.l2_regularizer(v_lambda)(w))
1.7,滑动平均模型
用于控制模型的变化速度,可以控制权重W以及偏差 biases 例如 :avg_class.average(w) avg_avergae(biases)
import tensorflow as tf
v1 = tf.Variable(0, dtype=tf.float32)
step = tf.Variable(0, trainable=False)
ema = tf.train.ExponentialMovingAverage(decay=0.99, num_updates=step)
# 每一次操作的时候,列表变量[v1]都会被更新
maintain_averages_op = ema.apply([v1])
with tf.Session() as sess:
# 初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run([v1, ema.average(v1)]))
# 更新step和v1的取值
sess.run(tf.assign(step, 10000))
sess.run(tf.assign(v1, 10))
sess.run(maintain_averages_op)
print(sess.run([v1, ema.average(v1)]))
二,MNIST的无监督学习
下面将基于无监督学习的中的一个简单应用——自编码器(autoencoder),TensorFlow搭建一个自编码网络,并用它在MNIST数据集上训练。
其实已经学习过了 tensorflow学习笔记——自编码器及多层感知器
所以这里简单将代码走个流程。
2.1 自编码器网络
其实前面学习的训练MNIST数据的网络都是有监督学习,它的重要特征是数据是有标记的,无标记的数据应该用什么样的网络模型来学习呢?下面我们就来介绍一个网络模型——自编码网络。
自编码网络如下:
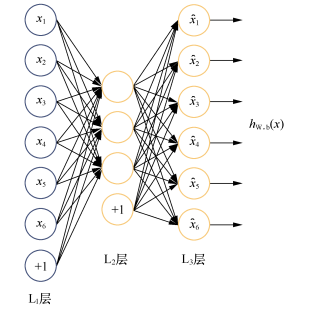
这里再啰嗦一遍,自编码网络的作用是将输入样本压缩到隐藏层,然后解压,在输出端重建样本。最终输出层神经元数量等于输入层神经元的数量。
这里主要有两个过程:压缩和解压。压缩依靠的时输入数据(图像,文字,声音)本身存在不同程度的冗余信息,自动编码网络通过学习去掉这些冗余信息,把有用的特征输入到隐藏层中。这个和主成分分析(PCA)有些类似,要找到可以代表源数据的主要成分。其实,如果激活函数不使用Sigmoid等非线性函数,而是由线性函数,就是PCA模型。可以想象,如果数据都是完全随机,相互独立,同分布的,自编码网络就很难学习到一个有效的压缩模型。
压缩过程一方面要限制隐藏神经元的数量,来学习一些有意义的特征,另一方面还希望神经元大部分时间是被抑制的,当神经元的输出接近1时,认为是被激活的,接近0时认为是被抑制的。希望部分神经元处于被抑制状态,这种规则称为稀疏性限制。
多个隐藏层的主要作用是,如果输入的数据是图像,第一层会学习如何识别边,第二层会学习如何去组合边,从而构成轮廓,角等,更高层会学习如何去组合更有意义的特征。例如,如果输入数据是人脸图像的话,更高层会学习如何识别和组合眼睛,鼻子,嘴等人脸器官。
2,TensorFlow的自编码网络实现
下面我们还以MNIST数据集为例,学习一下自编码器的运用。
1,加载数据,首先设置训练的超参数,包括学习率,训练的轮(epoch)数(全部数据训完一遍称为一轮),每轮训练的数据多少,每隔多少轮显示一次训练结果:
# _*_coding:utf-8_*_
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 设置训练超参数
learning_rate = 0.01 # 学习率
training_epochs = 20 # 训练的轮数
batch_size = 256 # 每次训练的数据多少
display_step = 1 # 每隔多少轮显示一次训练结果
# 下面参数表示从测试集中选择10张图片去验证自编码器的结果
examples_to_show = 10
# 定义输入数据,这里是无监督学习,所以只需要输入图片数据,不需要标记数据
X = tf.placeholder('float', [None, n_input])
# 下面初始化权重和定义网络结构,我们设计这个自动编码网络含有两个隐含层
# 第一个隐含层神经元为256个,第二个隐藏层神经元为128个
# 定义网络参数如下:
n_hidden_1 = 256 # 第一个隐藏层神经元个数,也是特征值个数
n_hidden_2 = 128 # 第二个隐藏层神经元个数,也是特征值个数
n_input = 784 # 输入数据的特征值个数,28*28=784
# 初始化每一层的权重和偏置,如下:
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases= {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# 定义自动编码模型的网络结构,包括压缩和解压两个过程
# 定义压缩函数
def encoder(x):
# encoder hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# decoder hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# 定义解压函数
def decoder(x):
# encoder hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# decoder hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
# 构建模型
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# 下面构建损失函数和优化器
# 这里损失函数采用“最小二乘法” 对原始数据集合输出的数据集进行平方差并取均值运算
# 优化器采用RMSPropOptimizer
y_pred = decoder_op # 得出预测值
y_true = X # 得出真实值,即输入值
# 定义损失函数和优化器
cost = tf.reduce_mean(tf.pow(y_true-y_pred, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
(2),训练数据及其评估模型
# 在一个会话中启动图,开始训练和评估
with tf.Session() as sess:
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
# 开始训练
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# run optimization op(backprop) and cost op(to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 每一轮,打印出一次损失值
if epoch % display_step == 0:
print("Epoch: ", "%04d" % (epoch + 1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# 对测试集应用训练好的自动编码网络
encode_decode = sess.run(y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# 比较测试集原始图片和自动编码网络的重建结果
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28))) # 测试集
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28))) # 重建结果
f.show()
plt.draw()
plt.waitforbuttonpress()
训练输出每一轮的损失值,结果如下:
Epoch: 0001 cost= 0.224611133 Epoch: 0002 cost= 0.185801953 Epoch: 0003 cost= 0.167944789 Epoch: 0004 cost= 0.155772462 Epoch: 0005 cost= 0.148120180 Epoch: 0006 cost= 0.141713008 Epoch: 0007 cost= 0.140479833 Epoch: 0008 cost= 0.138582915 Epoch: 0009 cost= 0.129859537 Epoch: 0010 cost= 0.127602220 Epoch: 0011 cost= 0.124348059 Epoch: 0012 cost= 0.120832287 Epoch: 0013 cost= 0.118068665 Epoch: 0014 cost= 0.119204752 Epoch: 0015 cost= 0.117326580 Epoch: 0016 cost= 0.116811723 Epoch: 0017 cost= 0.116068400 Epoch: 0018 cost= 0.110866800 Epoch: 0019 cost= 0.112090074 Epoch: 0020 cost= 0.111832522 Optimization Finished!
可以看出随着训练次数的增多,损失值趋于减少。
测试集的图片和经过自动编码器重建特征后的图片对比如下:上面一行是测试集的图片,下面一行对应的是经过自动编码器重建后的结果。

总的代码如下:
# _*_coding:utf-8_*_
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
# 设置训练超参数
learning_rate = 0.01 # 学习率
training_epochs = 20 # 训练的轮数
batch_size = 256 # 每次训练的数据多少
display_step = 1 # 每隔多少轮显示一次训练结果
# 下面参数表示从测试集中选择10张图片去验证自编码器的结果
examples_to_show = 10
# 下面初始化权重和定义网络结构,我们设计这个自动编码网络含有两个隐含层
# 第一个隐含层神经元为256个,第二个隐藏层神经元为128个
# 定义网络参数如下:
n_hidden_1 = 256 # 第一个隐藏层神经元个数,也是特征值个数
n_hidden_2 = 128 # 第二个隐藏层神经元个数,也是特征值个数
n_input = 784 # 输入数据的特征值个数,28*28=784
# 定义输入数据,这里是无监督学习,所以只需要输入图片数据,不需要标记数据
X = tf.placeholder('float', [None, n_input])
# 初始化每一层的权重和偏置,如下:
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# 定义自动编码模型的网络结构,包括压缩和解压两个过程
# 定义压缩函数
def encoder(x):
# encoder hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# decoder hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# 定义解压函数
def decoder(x):
# encoder hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# decoder hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
# 构建模型
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# 下面构建损失函数和优化器
# 这里损失函数采用“最小二乘法” 对原始数据集合输出的数据集进行平方差并取均值运算
# 优化器采用RMSPropOptimizer
y_pred = decoder_op # 得出预测值
y_true = X # 得出真实值,即输入值
# 定义损失函数和优化器
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
# 在一个会话中启动图,开始训练和评估
with tf.Session() as sess:
tf.global_variables_initializer().run()
total_batch = int(mnist.train.num_examples / batch_size)
# 开始训练
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# run optimization op(backprop) and cost op(to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 每一轮,打印出一次损失值
if epoch % display_step == 0:
print("Epoch: ", "%04d" % (epoch + 1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# 对测试集应用训练好的自动编码网络
encode_decode = sess.run(y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# 比较测试集原始图片和自动编码网络的重建结果
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28))) # 测试集
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28))) # 重建结果
f.show()
plt.draw()
plt.waitforbuttonpress()
三,将MNIST数据集转换为TFRecord文件
TFRecord 文件中的数据都是通过 tf.train.Example Protocol Buffer 的格式存储的。以下为 tf.train.Example 的数据结构:
message Example {
Features features = 1;
};
message Features{
map<string, Feature> feature = 1;
};
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 1;
Int64List int64_list = 3;
}
};
tf.train.Example 中包含了一个从属性名称到取值的字典。其中属性名称为一个字符串,属性的取值可以为字符串(BytesList),实数列表(FloatList)或者整数列表(Int64List)。
3.1,将MNIST数据集中的所有文件存储到一个TFRecord文件
# _*_coding:utf-8_*_
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import numpy as np
# 生成整数的属性
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 生成字符串型的属性
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def create_records():
'''
实现将 MNIST 数据集 转化为records
注意:读取的图像数据默认是uint8,然后转化为tf 的字符串型BytesList 保存,
:return:
'''
# 导入MNIST数据集
mnist = input_data.read_data_sets('data/', dtype=tf.uint8, one_hot=True)
images = mnist.train.images
labels = mnist.train.labels
# 训练图像的分辨率,作为example的属性
pixels = images.shape[1]
num_examples = mnist.train.num_examples
# 存储TFRecord文件的地址
filename = 'record/output_mnist.tfrecords'
# 创建一个writer来写TFRecord 文件
writer = tf.python_io.TFRecordWriter(filename)
# 将每张图片都转化为一个Example
for i in range(num_examples):
# 将图像转为字符串
image_raw = images[i].tostring()
# 将一个样例转化为Example Protocol Buffer 并将所有信息写入这个数据结构
example = tf.train.Example(features=tf.train.Features(
feature={
'pixels': _int64_feature(pixels),
'label': _int64_feature(np.argmax(labels[i])),
'image_raw': _bytes_feature(image_raw)
}
))
# 将Example写入TFRecord 文件
writer.write(example.SerializeToString())
print("data processing success")
writer.close()
if __name__ == '__main__':
dir_name = 'record'
if not os.path.exists(dir_name):
os.mkdir(dir_name)
create_records()
上面程式可以将MNIST数据集中所有的训练数据存储到一个TFRecord 文件中。当数据量较大时,也可以将数据写入多个 TFRecord 文件。TensorFlow对从文件列表中读取数据提供了很好的支持。
3.2,读取封装好的MNIST数据的TFRecord文件
#_*_coding:utf-8_*_
import tensorflow as tf
def read_tfrecord():
"""
读取tfrecord文件
:return:
"""
filename = 'record/output.tfrecords'
# 创建一个队列来维护输入文件列表
filename_queue = tf.train.string_input_producer([filename])
# 创建一个reader来读取TFRecord文件中Example
reader = tf.TFRecordReader()
# 从文件中读取一个Example
_, serialized_example = reader.read(filename_queue)
# 用FixedLenFeature 将读入的Example解析成 tensor
features = tf.parse_single_example(
serialized_example,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64)
}
)
# tf.decode_raw 将字符串解析成图像对应的像素数组
images = tf.decode_raw(features['image_raw'], tf.uint8)
labels = tf.cast(features['label'], tf.int32)
pixels = tf.cast(features['pixels'], tf.int32)
init_op = tf.global_variables_initializer()
with tf.Session() as sess :
sess.run(init_op)
# 启动多线程处理输入数据
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 每次运行读出一个Example,当所有样例读取完之后,在此样例中程序会重头读取
for i in range(10):
# 在会话中取出image 和 label
image, label = sess.run([images, labels])
print(label)
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
read_tfrecord()
四,TensorFlow训练神经网络
在神经网络的结构上,深度学习一方面需要使用激活函数实现神经网络模型的去线性化,另一方面需要一个或多个隐藏层使得神经网络的结构更深,以解决复杂问题,在训练神经网络时,我们学习了使用带指数衰减的学习率设置,使用正则化来避免过度拟合,以及使用滑动平均模型来使得最终模型更加健壮。以下代码给出了一个在MNIST数据集上实现这些功能的完整的TensorFlow程序。
#_*_coding:utf-8_*_
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# MNIST 数据集相关的常数
# 输入层的节点数,对于MNIST数据集,这个就等于图片的像素
INPUT_NODE = 784
# 输出层的节点数,这个等于类别的数目,因为在MNIST数据集中需要区分的
# 是0-9这个10个数字,所以这里输出层的节点数为10
OUTPUT_NODE = 10
# 配置神经网络的参数
# 隐藏层节点数,这里使用只有一个隐藏层的网络结构作为样例
# 这个隐藏层有500个节点
LAYER1_NODE = 500
# 一个训练batch中的训练数据个数,数字越小时,训练过程越接近随机梯度下降
# 数字越大时,训练越接近梯度下降
BATCH_SIZE = 100
# 基础的学习率
LEARNING_RATE_BASE = 0.8
# 学习率的衰减率
LEARNING_RATE_DECAT = 0.99
# 描述模型复杂度的正则化项在损失函数中的系数
REGULARIZATION_RATE = 0.0001
# 训练轮数
TRAINING_STEPS = 30000
# 滑动平均衰减率
MOVING_AVERAGE_DECAY = 0.99
# 一个辅助函数,给定神经网络的输入和所有参数,计算神经网络的前向传播结果
# 在这里定义了一个使用ReLU激活函数的三层全连接神经网络
# 通过加入隐藏层实现了多层网络结构,通过ReLU激活函数实现了去线性化
# 在这个函数中也支持传入用于计算参数平均值的类,这样方便在测试时使用滑动平均模型
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
# 当没有提供滑动平均类时,直接使用参数当前的取值
if avg_class == None:
# 计算隐藏层的前向传播结果,这里使用了ReLU激活函数
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 计算输出层的前向传播结果,因为在计算损失函数时会一并计算softmax函数
# 所以这里不需要加入激活函数,而且不加入softmax不会影响预测结果
# 因为预测时使用的是不同类型对应节点输出值的相对大小,
# 有没有softmax层对最后分类的结果没有影响
# 于是在计算整个神经网络的前向传播时可以不加入最后的softmax层
return tf.matmul(layer1, weights2) + biases2
else:
# 首先使用avg_class.average 函数来计算得出变量的滑动平均值
# 然后再计算相应的神经网络前向传播结果
layer1 = tf.nn.relu(
tf.matmul(input_tensor, avg_class.average(weights1)) +
avg_class.average(biases1)
)
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 训练模型的过程
def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
# 生成隐藏层的参数
weights1 = tf.Variable(
tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成输出层的参数
weights2 = tf.Variable(
tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 计算在当前参数下神经网络前向传播的结果。这里给出的用于计算滑动平均的类为None
# 所以函数不会使用参数的滑动平均值
y = inference(x, None, weights1, biases1, weights2, biases2)
# 定义存储训练轮数的变量,这个变量不需要计算滑动平均值
# 这里指定这个变量为不可训练的变量(trainable=False)
# 在使用TensorFlow训练神经网络时,一般会将代表训练轮数的变量指定为不可训练的参数
global_step = tf.Variable(0, trainable=False)
# 给定滑动平均衰减率和训练轮数的变量,初始化滑动平均类。
# 当给定训练轮数的变量可以加快训练早期变量的更新速度
varibale_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step
)
# 在所有代表神经网络参数的变量上使用滑动平均。
# 其他辅助变量(比如global_step)就不需要了
# tf.trainable_variables 返回的就是图上集合GraphKeys.TRAINABLE_VARIABLES中的元素
# 这个集合的元素就是所有没有指定trainable=False 的参数
varibale_averages_op = varibale_averages.apply(tf.trainable_variables())
# 计算使用了滑动平均之后的前向传播结果。因为滑动平均不会改变变量本身的额取值
# 而是会委会一个影子变量来记录其滑动平均值,所以当需要使用这个滑动平均值时,需要明确调用average函数
average_y = inference(x, varibale_averages, weights1, biases1, weights2, biases2)
# 计算交叉熵作为刻画预测值和真实值之间差距的损失函数,这里使用了TensorFlow中提供的
# sparse_softmax_cross_entropy_with_logits函数来计算交叉熵
# 当分类问题中只有一个正确答案时,可以使用这个函数来加速交叉熵的计算
# MNIST问题的图片中只包含了一个0-9中的一个数字,所以可以使用这个函数来计算交叉熵损失
# 这个函数的第一个参数是神经网络不包含softmax层的前向传播结果,第二个是训练数据的正确答案
#因为标准答案是一个长度为10的一位数组,而该函数需要提供了一个正确的答案数字
#所以需要使用 tf.argmax函数来得到正确答案对应的类别编号
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
# 计算在当前batch中所有样例的交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 计算L2正则化损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 计算模型的正则化损失,一般只计算神经网络边上权重的正则化损失,而不使用偏置项
regularization = regularizer(weights1) + regularizer(weights2)
# 总损失等于交叉熵损失和正则化损失的和
loss = cross_entropy_mean + regularization
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE, #基础的学习率,随着迭代的进行,更新变量时使用的
# 学习率在这个基础上递减
global_step, # 学习率在这个基础上递减
mnist.train.num_examples / BATCH_SIZE, # 过完所有的训练数据需要的迭代次数
LEARNING_RATE_DECAT, # 学习率衰减速度
staircase=True
)
# 使用tf.train.GradientDescentOptimizer优化算法来优化损失函数
# 注意这里损失函数包含了交叉熵损失和L2正则化损失
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 在训练神经网络模型时,没过一遍数据即需要通过反向传播来更新神经网络中的参数
# 又要更新每一个参数的滑动平均值,为了一次完成多个操作,西面两行程序和下面代码是等价的
# train_op = tf.group(train_step, varibale_averages_op)
with tf.control_dependencies([train_step, varibale_averages_op]):
train_op = tf.no_op(name='train')
# 检验使用了滑动平均模型的神经网络前向传播结果是否正确。tf.argmax(average_y, 1)
# 计算每一个样例的预测答案,其中average_y 是一个 batch_size*10的二维数组,
# 每一行表示一个样例的前向传播结果。tf.argmax的第二个参数“1”表示选取最大值的的操作
# 仅在第一个维度中进行,也即是说,只有每一行选取最大值对应的下标
# 于是得到的结果是一个长度为batch的一维数组,这个一维数组中的值就表示了
# 每一个样例对应的数字识别结果
# tf.rqual 判断两个张量的每一维是否相等,如果相等返回True,否则返回False。
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
# 这个运算首选将一个布尔型的数值转换为实数型,然后计算平均值,这个平均值
# 就是模型在这一组数据上的正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化会话并开始训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 准备验证数据,一般在神经网络的训练过程中会通过验证数据来判断
# 大致判断停止的条件和评判训练的效果
validate_feed = {x: mnist.validation.images,
y_: mnist.validation.labels}
#准备测试数据,在真实的应用中,这部分数据在训练时是不可见的
# 下面数据只是作为模型优劣的最后评价标准
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
# 迭代地训练神经网络
for i in range(TRAINING_STEPS):
# 每1000轮输出一次在验证数据集上的测试结果
if i % 1000 == 0:
# 计算滑动平均模型在验证数据上的结果,因为MNIST数据集比较小,
# 所以一次可以处理所有的验证数据
# 当神经网络模型比较复杂或者验证数据比较大,太大的batch会导致计算时间过长
# 甚至发生内存溢出的错误
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print('After %d training step(s), validation accuracy using average model is %g'%(i, validate_acc))
# 产生这一轮使用的一个batch的训练数据,并运行训练过程
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={x:xs, y_:ys})
# 在训练结束后,在测试数据集上检测神经网络模型的最终正确率
test_acc = sess.run(accuracy, feed_dict=test_feed)
print('After %d training step(s), test accuracy using average model is %g'%(TRAINING_STEPS, test_acc))
# 主程序入口
def main(argv=None):
# 声明处理MNIST数据集的类,这个类在初始化的时候会自动下载数据
mnist = input_data.read_data_sets('data', one_hot=True)
train(mnist)
# Tensorflow 提供的一个主程序入口,tf.app.run会调用上面定义的main函数
if __name__ == '__main__':
# tf.app.run(main=None)
main()
运行上面的程序,得到的结果如下:
Extracting data rain-images-idx3-ubyte.gz Extracting data rain-labels-idx1-ubyte.gz Extracting data 10k-images-idx3-ubyte.gz Extracting data 10k-labels-idx1-ubyte.gz After 0 training step(s), validation accuracy using average model is 0.143 After 1000 training step(s), validation accuracy using average model is 0.9776 After 2000 training step(s), validation accuracy using average model is 0.9816 After 3000 training step(s), validation accuracy using average model is 0.9832 After 4000 training step(s), validation accuracy using average model is 0.9838 After 5000 training step(s), validation accuracy using average model is 0.9836 ... ... After 27000 training step(s), validation accuracy using average model is 0.9846 After 28000 training step(s), validation accuracy using average model is 0.9844 After 29000 training step(s), validation accuracy using average model is 0.9844 After 30000 training step(s), test accuracy using average model is 0.9842
从上面的结果可以看出,在训练初期,随着训练的进行,模型在验证数据集上的表现越来越好。从第4000轮开始,模型在验证数据集上的表现就开始波动,这说明模型已经接近极小值了。所以迭代也就结束了。
代码中一些错误的改正
这些代码均来自与《TensorFlow实战:Google深度学习框架》这本书,原因是TensorFlow的版本相对书上的版本比较高,所以一些API接口都变了。所以有些函数在书中的程序是错误的,导致程序在运行的时候就会报错。
错误1如下:
ValueError: Only call `sparse_softmax_cross_entropy_with_logits` with named arguments (labels=..., logits=..., ...)
解决:这个原因是函数的API发生了变化,我们需要添加labels 和 logits。
修改代码如下:
原代码: # 计算交叉熵及其平均值 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(y,tf.argmax(y_, 1)) 修改后的代码: cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=tf.argmax(y_, 1)) ***********出现新的错误************* ValueError: Rank mismatch: Rank of labels (received 2) should equal rank of logits minus 1 (received 1). 我们将代码修改如下: labels=tf.argmax(y_, 1),logits=y
后面的原因是因为计算交叉熵的时候,比较的两个概率分布放反了。因为交叉熵是衡量一个概率分布区表达另外一个概率分布的难度,值越低越好,所以是用预测的结果来表达正确的标签。
当运行完例子,会报如下错误:
Traceback (most recent call last):
File "E:PyCharm 2019.1.3helperspydevpydevconsole.py", line 221, in do_exit
import java.lang.System
File "E:PyCharm 2019.1.3helperspydev\_pydev_bundlepydev_import_hook.py", line 21, in do_import
module = self._system_import(name, *args, **kwargs)
ModuleNotFoundError: No module named 'java'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "E:PyCharm 2019.1.3helperspydev\_pydev_bundlepydev_umd.py", line 197, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "E:PyCharm 2019.1.3helperspydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"
", file, 'exec'), glob, loc)
File "E:/backup/pycode.py", line 180, in <module>
tf.app.run(main=None)
File "E:Anaconda3envspython36libsite-packages ensorflowpythonplatformapp.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "E:PyCharm 2019.1.3helperspydevpydevconsole.py", line 226, in do_exit
os._exit(args[0])
TypeError: an integer is required (got type NoneType)
小小分析一波,我们发现已经执行完代码了。执行完后会报错误提示:
TypeError: an integer is required (got type NoneType)
经查看,是TensorFlow版本问题,在r0.11之前的版本里,tf.app.run的代码如下:
def run(main=None): f = flags.FLAGS flags_passthrough = f._parse_flags() main = main or sys.modules['__main__'].main sys.exit(main(sys.argv[:1] + flags_passthrough))
没有argv 参数,argv参数是在 r0.12后加入的。所以需要升级版本。其实不升级版本也可以,我们这样执行即可。
if __name__ == '__main__':
# 我们这里不使用TensorFlow提供的主程序入口 tf.app.run函数
# tf.app.run(main=None)
main()
五,使用验证数据集判断模型效果
在上面程序中我们使用了神经网络解决MNIST问题,在程序的开始设置了初始学习率,学习率衰减率,隐藏层节点数量,迭代轮数等七种不同的参数。那么如何设置这些参数的取值呢?在大部分情况下,配置神经网络的这些参数都是需要通过实验来调整的。虽然一个神经网络模型的效果最终是通过测试数据来判断的,但是我们不能直接通过模型在测试数据上的效果来选择参数,使用测试数据来选取参数可能会导致神经网络模型过度拟合测试数据,从而失去对未知数据的预判能力。因为一个神经网络模型的最终目标是对未知数据提供判断,所以为了评估模型在未知数据上的效果,需要保证测试数据在训练过程中是不可见的。只有这样才能保证通过测试数据评估出来的效果和真实应用场景下模型对未知数据预判的效果是接近的。于是,为了评测神经网络模型在不同参数取值下的效果,一般会从训练数据中抽取一部分作为验证数据。使用验证数据就可以评判不同参数取值下模型的表现。除了使用验证数据,还可以采用交叉验证(cross validation)的方式来验证模型效果。但因为神经网络训练时间本身就比较长,采用 cross validation 会花费大量的时间,所以在海量数据的情况下,一般会更多的采用验证数据集的形式来评测模型的效果。
为了说明验证数据在一定程度上可以作为模型效果的评判标准,我们将对比在不同迭代轮数的情况下,模型在验证数据和测试数据上的正确率。为了同时得到同一个模型在验证数据和测试数据上的正确率,可以在每1000轮的输出中加入在测试数据集上的正确率。当我们再上门代码中加入下面代码,就可以得到每1000轮迭代后,使用了滑动平均的模型在验证数据和测试数据上的正确率。
if i % 1000 == 0:
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
# 计算滑动平均模型在测试数据和验证数据上的正确率
test_acc = sess.run(accuracy, feed_dict=test_feed)
print('After %d training step(s), validation accuracy using average model is %g,'
'test accuracy using average model is %g'%(i, validate_acc, test_acc))
下图给出了上面代码得到的每1000轮滑动平均模型在不同数据集上的正确率曲线,其中灰色曲线表示随着迭代轮数的增加,模型在验证数据上的正确率,黑色曲线表示在测试数据上的正确率。从图中可以看出虽然两条曲线不会完全重合,但是这两条曲线的趋势基本一样,而且他们的相关关系(correlation coeddicient)大于0.9999。这意味着在MNIST问题上,完全可以通过模型在验证数据上的表现来判断一个模型的优劣。
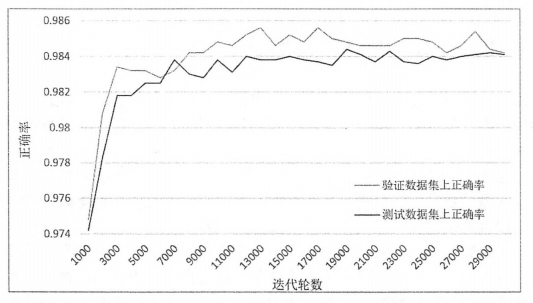
当然,以上结论是针对MNIST这个数据集的额,对其它问题,还需要具体问题具体分析。不同问题的数据分布式不一样的。如果验证数据分布不能很好地代表测试数据分布。那么模型在这两个数据集上的表现就有可能会不一样。所以,验证数据的选取方法是非常重要的,一般来说选取的验证数据分布越接近测试数据分布,模型在验证数据上的表现越可以体现模型在测试数据上的表现。通过上面的实验,至少可以说明通过神经网络在验证数据上的效果来选取模型的参数是一个可行的方案。
六,不同模型效果比较
下面通过MNIST数据集来比较值钱提到的不同优化方法对神经网络模型正确率的影响。下面将使用神经网络模型在MNIST测试数据集上的正确率作为评价不同优化方法的标准。并且一个模型在MNIST测试数据集上行的正确率简称为“正确率”。之前提到了设计神经网络时的五种优化方法。在神经网络结构的设计上,需要使用激活函数和多层隐藏层。在神经网络优化时,可以使用指数衰减的学习率,加入正则化的损失函数以及滑动平均模型,在下图中给出了在相同神经网络参数下,使用不同优化方法啊,经过3000轮训练迭代后,得到的最终模型的正确率。下图的结果包含了使用所有优化方法训练得到的模型和不用其中某一项优化方法训练得到的模型。通过这种方式,可以有效验证每一项优化方法的效果。
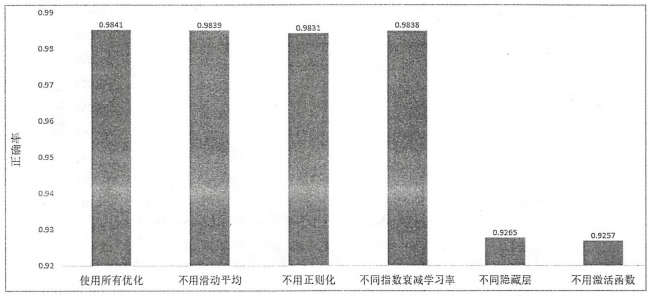
从图中可以很明显的看出,调整神经网络的结构对最终的正确率有非常大的影响。没有隐藏层或者激活函数时,模型的正确率只有大约92.6%,这个数字要远远小于使用了隐藏层和激活函数时可以达到的大约98.4%的正确率。这说明神经网络的结构对最终模型的效果有本质性的影响。
从上图的结果可以发现使用滑动平均模型,指数衰减的学习率和使用正则化带来的正确率的提升并不是特别明显。其中使用了所有优化算法的模型和不使用滑动平均的模型以及不适用指数衰减的学习率的模型都可以达到大约98.4%的正确率。这是因为滑动平均模型和指数衰减的学习率在一定程度上都是限制神经网络中参数更新的速度,然而在MNIST数据上,因为模型收敛的速度很快,所以这两种优化对最终模型的影响不大。从之前的结果可以看出,当模型迭代达到4000轮的时候正确率就已经接近最终的正确率了。而在迭代的早期,是否使用滑动平均模型或者指数衰减的学习率对训练的结果影响相对较小,下图显示了不同迭代轮数时,使用了所有优化方法的模型的正确率与平均绝对梯度的变化趋势。
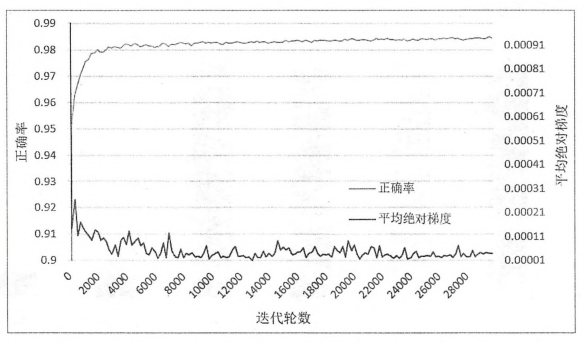
下图显示了不同迭代轮数时,正确率与衰减之后的学习率的变化趋势:
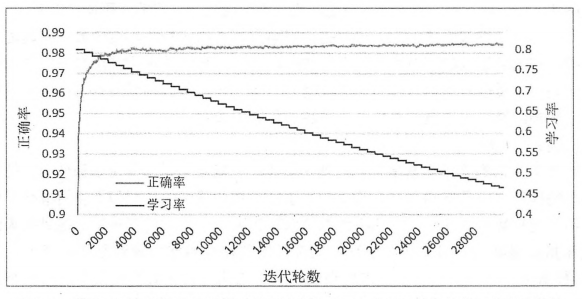
从图中可以看出前4000轮迭代对模型的改变是最大的。在4000轮之后,因为梯度本身比较小,所以参数的改变也就是比较缓慢了。于是滑动平均模型或者指数衰减的学习率的作用也就没有那么突出了。从上图可以看到,学习率曲线呈现出阶梯状衰减,在前4000轮时,衰减之后的学习率和最初的学习率差距并不大。那么,这是否能说明这些优化方法作用不大呢?答案是否定的,当问题更加复杂时,迭代不会这么快接近收敛,这时滑动平均模型和指数衰减的学习率可以发挥更大的作用。比如在Cifar-10 图像分类数据集上,使用滑动平均模型可以将错误率降低11%,而使用指数衰减的学习率可以将错误率降低7%。
相对滑动平均模型和直属衰减学习率,使用加入正则化的损失函数给模型效果带来的提升要相对显著。使用了正则化损失函数的神经网络模型可以降低大约6%的错误率(从1.69%降低到1.59%)。下图给出了正则化给模型优化过程带来的影响。并且下面两个图给出了不同损失函数的神经网络模型。一个模型只最小化交叉熵损失,另一个模型优化的是交叉熵和L2正则化的损失的和。下面先给出这个模型优化函数的声明语句:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,
labels=tf.argmax(y_, 1))
# 计算在当前batch中所有样例的交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
#*********************************************************
# 只最小化交叉熵损失
train_step = tf.train.GradientDescentOptimizer(learning_rate
).minimize(cross_entropy_mean,global_step=global_step)
#*********************************************************
# 优化交叉熵和L2正则化损失的和
loss = cross_entropy_mean + regluaraztion
train_step = tf.train.GradientDescentOptimizer(learning_rate
).minimize(loss, global_step=global_step)
下图灰色和黑色的实线给出了两个模型正确率的变化趋势,虚线给出了在当前训练batch上的交叉熵损失:
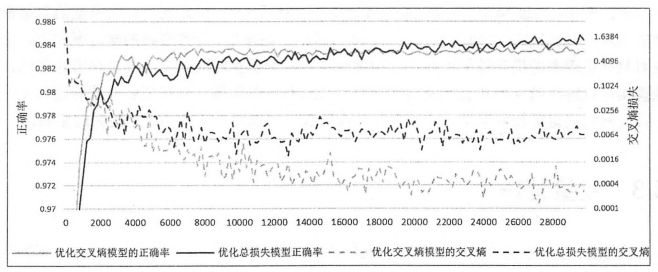
从图中可以看出,只优化交叉熵的模型在训练数据上的交叉熵损失(灰色虚线)要比优化总损失的模型更小(黑色虚线)。然而在测试数据上,优化总损失的模型(褐色实线)却要比只优化交叉熵的模型(灰色实线)。这其中缘故,就是过拟合问题,只优化交叉熵的模型可以更好地拟合训练数据(交叉熵损失更小),但是却不能很好的挖掘数据中潜在的规律来判断未知的测试数据,所以在测试数据上的正确率低。
下图显示了不同模型的损失函数的变化趋势,左侧显示了只优化交叉熵的模型损失函数的变化规律,可以看到随着迭代的进行,正则化损失是在不断加大的。因为MNIST问题相对比较简单,迭代后期的梯度很小,所以正则化损失的增长也不快。如果问题更加复杂,迭代后期的梯度更大,就会发现总损失(交叉熵损失加上正则化损失)会呈现出一个U字形,在图的右侧,显示了优化总损失的模型损失函数的变化规律,从图中可以看出,这个模型的正则化损失部分也可以随着迭代的进行越来越小,从而使得整体的损失呈现一个逐步递减的趋势。
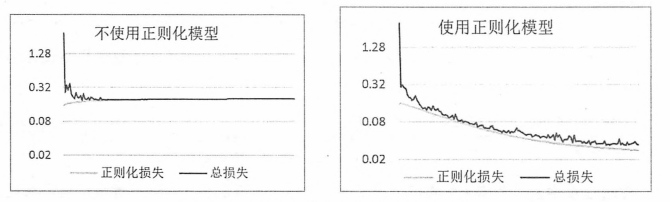
总的来说,通过MNIST数据集有效地验证了激活函数,隐藏层可以给模型的效果带来质的飞跃。由于MNIST问题本身相对简单,滑动平均模型,指数衰减的学习率和正则化损失对最终正确率的提升效果不明显。但是通过进一步分析实验的结果,可以得出这些优化方法确实可以解决神经网络优化过程中的问题。当需要解决的问题和使用到的神经网络模型更加复杂时,这些优化方法将更有可能对训练效果产生更大的影响。
七,变量管理
上面我们将计算神经网络前向传播结果的过程抽象成了一个函数。通过这种方式在训练和测试的过程中可以统一调用同一个函数来得模型的前向传播结果。
在上面代码中,这个函数定义如下:
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
在定义中可以看到,这个函数的参数中包含了神经网络中的所有参数。然而,当神经网络的结构更加复杂,参数更多时,就需要一个更好的方式来传递和管理神经网络中的参数了。TensorFlow提供了通过变量名称来创建或者获取一个变量的机制。通过这个机制,在不同的函数中可以直接通过变量的名字来使用变量,而不需要将变量通过 tf.get_variable 和 tf.get.variable_scope 函数实现的。下面将分别介绍如何使用这两个函数。
前面学习了通过tf.Variable 函数来创建一个变量。除了tf.Variable函数,TensorFlow还提供了tf.get_variable函数来创建或者获取变量。当 tf.get_variable用于创建变量时,它和tf.Variable的功能是基本等价的。以下代码给出了通过两个函数创建同一个变量的样例:
# 下面两个定义是等价的
v = tf.get_variable('v', shape=[1],
initializer=tf.constant_initializer(1.0))
v = tf.Variable(tf.constant(1.0, shape=[1]), name='v')
从上面的代码可以看出,通过tf.get_variable 和 tf.get.variable_scope 函数创建变量的过程基本是一致的。tf.get_variable 函数调用时提供的维度(shape)信息以及初始化方法(initializer)的参数和tf.Variable 函数调用时提供的初始化过程中的参数也类似。TensorFlow中提供的initializer 函数和之前提到的随机数以及常量生成函数大部分是一一对应的。比如,在上面的样例程序中使用到的常数初始化函数 tf.constant_initializer 和常数生成函数 tf.constant 功能上就是一直的。TensorFlow 提供了七种不同的初始化函数,下表总结了他们的功能和主要参数。
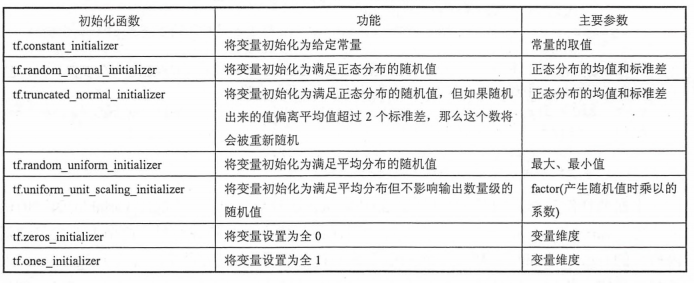
tf.get_varibale 函数与 tf.Variable 函数最大的区别在于指定变量名称的参数。对于 tf.Variable 函数,变量名称是一个可选的参数,通过 name='v' 的形式给出。但是对于 tf.get_variable 函数,变量名称是一个必填的参数。tf.get_variable会根据这个名字去创建或者获取变量。在上面的样例程序中,tf.get_variable首先会视图去创建一个名字为 v 的参数,如果创建失败(比如已经有同名的参数),那么这个程序就会报错。这是为了避免无意识的变量复用造成的错误。比如在定义神经网络参数时,第一层网络的权重已经叫 weights 了,那么在创建第二层神经网络时,如果参数名仍然叫 weights,就会触发变量重用的错误。否则两层神经网络共用一个权重会出现一些比较难以发现的错误。如果需要通过 tf.get_variable 获取一个已经创建的变量,需要通过 tf.variable_scope 函数来生成一个上下文管理器,并明确指定在这个上下文管理器中, tf.get_variable将直接获取已经生成的变量。下面给出一段代码来说明如何通过tf.variable_scope 函数来控制 tf.get_variable 函数获取已经创建过的变量。
# 在名字为foo的命名空间内创建名字为 v 的变量
with tf.variable_scope('foo'):
v = tf.get_variable(
'v', [1], initializer=tf.constant_initializer(1.0)
)
# 因为在命名空间foo中已经存在名字为 v 的变量,所以下面的代码将会报错
with tf.variable_scope('foo'):
v = tf.get_variable('v', [1])
'''
报错如下:
ValueError: Variable foo/v already exists, disallowed. Did you mean
to set reuse=True in VarScope?
'''
# 在生成上下文管理器时,将参数reuse设置为True,这样tf.get_variable函数将直接获取已经声明的函数
with tf.variable_scope('foo', reuse=True):
v1 = tf.get_variable('v', [1])
print(v == v1)
# 输出为True,代表v,v1代表的是相同的TensorFlow中变量
# 将参数reuse设置为True时,tf.variable_scope将只能获取已经创建过的变量
# 因为在命名空间bar中还没有创建变量 v 所以下面的代码将会报错
with tf.variable_scope('bar', reuse=True):
v = tf.get_variable('v', [1])
'''
报错如下:
ValueError: Variable bar/v does not exist, or was not created with tf.get_variable().
Did you mean to set reuse=None in VarScope?'''
上面的样例简单地说明了通过 tf.variable_scope函数可以控制 tf.get_variable函数的语义。当 tf.variable_scope函数使用参数 reuse=True生成上下文管理器时,这个上下文管理器内所有的tf.get_variable函数会直接获取已经创建的变量。如果变量不存在,则 tf.get_variable函数将会报错;相反,如果 tf.variable_scope函数使用参数 reuse=None或者 reuse=False创建上下文管理器,tf.get_variable操作将创建新的变量。如果同名的变量已经存在,则 tf.get_variable函数将报错,TensorFlow中 tf.variable_scope 函数是可以嵌套的,下面程序说明了当 tf.varibale_scope 函数嵌套时,reuse参数的取值是如何确定的:
with tf.variable_scope('root'):
# 可以通过td.get_varable_scope().reuse函数来获取当前上下文管理器中reuse参数的取值
print(tf.get_variable_scope().reuse)
# 输出为False 即最外层reuse是False
# 新建一个嵌套的上下文管理器,并制定reuse为True
with tf.variable_scope('foo', reuse=True):
print(tf.get_variable_scope().reuse)
# 输出为True,因为我们设置了其reuse为True
# 新建一个嵌套的上下文管理器但不指定reuse,这时候reuse的取值会和上一层层保持一致
with tf.variable_scope('bar'):
print(tf.get_variable_scope().reuse)
# 输出为True,没有设置的话,将和上一层保持一致
print(tf.get_variable_scope().reuse)
# 这里输出为False。退出reuse设置为True的上下文之后,reuse的值又回到了False
tf.variable_scope函数生成的上下文管理器也会创建一个TensorFlow中的命名空间,在命名空间内创建的变量名称都会带上这个命名空间名作为前缀。所以 tf.variable_scope函数除了可以控制tf.get_variable 执行的功能之外,这个函数也提供了一个管理变量命名空间的方式,以下代码显示了如何通过tf.variable_scope来管理变量的名称:
v1 = tf.get_variable('v', [1])
print(v1.name)
# 输出 v:0
# 其中 v 为变量的名称 0表示这个变量是生成变量这个运算的第一个结果
with tf.variable_scope('foo'):
v2 = tf.get_variable('v', [1])
print(v2.name)
# 输出 foo/v:0
# 在tf.variable_scope中创建的变量,名称前面会加入命名空间的名称
# 并通过/来分隔名称空间的名称和变量的名称
with tf.variable_scope('foo'):
with tf.variable_scope("bar"):
v3 = tf.get_variable('v', [1])
print(v3.name)
# 输出 foo/bar/v:0
# 命名空间可以嵌套,同时遍历的名称也会加入所有命名空间的名称作为前缀
v4 = tf.get_variable('v1', [1])
print(v4.name)
# 输出 foo/v1:0
# 当命名空间退出之后,变量名称也就不会再被加入其前缀了
# 创建一个名称为空的命名空间,并设置reuse=True
with tf.variable_scope("", reuse=True):
v5 = tf.get_variable('foo/bar/v', [1])
# 可以直接通过带命名空间名称的变量名来获取其他命名空间下的变量
# 比如这里指定名称 foo/bar/v 来获取在命名空间 foo/bar/中创建的变量
print(v5==v3)
# 输出结果为 : True
v6 = tf.get_variable('foo/v1', [1])
print(v6==v4)
# 输出结果为 : True
通过tf.variable_scope 和 tf.get_variable 函数,下面代码对计算前向传播结果的函数 做了一些改进:
def inference(input_tensor, reuse=False):
# 定义第一层神经网络的变量和前向传播过程
with tf.variable_scope('layer1', reuse=reuse):
# 根据传进来的reuse来判断是创建新变量还是使用已经创建好的
# 在第一次构造网络时需要创建新的变量,以后每次调用这个函数直接使用reuse=True
# 在之后,就不需要每次将变量传进来了。
weights = tf.get_variable('weights', [INPUT_NODE, LAYER1_NODE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable('biases', [OUTPUT_NODE],
initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
# 类似的定义第二层神经网络的变量和前向传播过程
with tf.variable_scope('layer2', reuse=reuse):
weights = tf.get_variable('weights', [LAYER1_NODE, OUTPUT_NODE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", [OUTPUT_NODE],
initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weights) + biases
# 返回最后的前向传播结果
return layer2
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y = inference(x)
# 在程序中需要使用训练好的神经网络进行推导时,可以直接调用 inference(new_x, True)
# 如果需要使用滑动平均模型可以参考之前的代码,把计算滑动平均的类传到inference函数中
# 获取或者创建变量的部分不需要改变
new_x = ...
new_y = inference(new_x, True)
使用上面的代码,就不需要再将所有的变量都作为参数传递到不同的函数中了。当神经网络结构更加复杂,参数更多时,使用这种变量管理的方式将大大提高程序的可读性。
八,TensorFlow最佳实践样例程序
在上面已经给出了一个完整的TensorFlow程序来解决MNIST问题,然而这个程序的可扩展性并不好,因为计算前向传播的函数需要将所有变量都传入,当神经网络结构变得更加复杂,参数更多时,程序可读性会变得非常差。而且这种方式会导致程序中有大量的冗余代码,降低编程的效率。并且上面程序并没有持久化训练好的模型。当程序退出时,训练好的模型也就无法被使用了,这导致得到的模型无法被重用。更严重的是,一般神经网络模型训练的时候都比较长,少则几个小时,多则几天甚至几周。如果在训练过程中程序死机了,那么没有保存训练的中间结果会浪费大量的时间和资源。所以,在训练的过程中需要每隔一段时间保存一次模型训练的中间结果。
结合变量管理机制和TensorFlow模型持久化机制,我们将学习一个TensorFlow训练设计网络的最佳实践。将训练和测试分成两个独立的程序,这可以使得每一个组件更加灵活。比如训练神经网络的程序可以持续输出训练好的模型,而测试程序可以每隔一段时间检测最新模型的正确率,如果模型效果更好,则将这个模型提供给产品使用。除了将不同功能模型分开,我们还将前向传播的过程抽象成一个单独的库函数,因为神经网络的前向传播过程在训练和测试的过程中都会用到,所以通过库函数的方式使用起来即可更加方便,又可以保证训练和测试过程中使用的前向传播方法一定是一致的。
下面将重构之前的程序来解决MNIST问题,重构之后的代码将会被拆成3个程序,第一个是 mnist_inference.py,它定义了前向传播的过程以及神经网络中的参数,第二个是 mnist_train.py 它定义了神经网络的训练过程,第三个是 mnist_eval.py ,它定义了测试过程。
下面给出 mnist_inference.py中的的内容:
#_*_coding:utf-8_*_
import tensorflow as tf
# 定义神经网络结构相关参数
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 通过get_variable函数来获取变量。在训练神经网络时会创建这些变量
# 在测试时会通过保存的模型加载这些变量的取值
# 因为可以在变量加载时将滑动平均变量重命名,所以可以通过同样的名字在训练时使用变量本身
# 而且在测试时使用变量的滑动平均值,在这个函数中也会将变量的正则化损失加入损失集合
def get_weight_variable(shape, regularizer):
weights = tf.get_variable(
'weights', shape,
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
# 当给出正则化生成函数时,将当前变量的正则化损失计入名字为losses的集合
#这里使用add_to_collection函数将一个张量加入一个集合,而这个集合的的名称为losses
# 这是自定义的集合,不再TensorFlow自主管理的集合列表中
if regularizer != None:
tf.add_to_collection('losses', regularizer(weights))
return weights
# 定义神经网络的前向传播过程
def inference(input_tensor, regularizer):
# 声明第一层神经网络的变量并完成前向传播过程
with tf.variable_scope('layer1'):
# 这里通过 tf.get_variable或tf.Variable没有本质区别
# 因为在训练或者是测试中没有在同一个程序中多次调用这个函数
# 如果在同一个程序中多次调用,在第一次调用之后就需要将reuse参数设置为True
weights = get_weight_variable(
[INPUT_NODE, LAYER1_NODE], regularizer
)
biases = tf.get_variable(
'biases', [LAYER1_NODE],
initializer=tf.constant_initializer(0.0)
)
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
# 类似的声明第二层神经网络的变量并完成前向传播过程
with tf.variable_scope('layer2'):
weights = get_weight_variable(
[LAYER1_NODE, OUTPUT_NODE], regularizer
)
biases = tf.get_variable(
'biases', [OUTPUT_NODE],
initializer=tf.constant_initializer(0.0)
)
layer2 = tf.matmul(layer1, weights) + biases
# 返回最后前向传播的结果
return layer2
在这段代码中定义了神经网络的前向传播算法,无论是训练时还是测试时,都可以直接调用 Inference 这个函数,而不用关心具体的神经网络结构,使用定义好的前向传播过程,下面代码给出了神经网络的训练程式 mnist_train.py的代码:
#_*_coding:utf-8_*_
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 加载 mnist_inference.py 中定义的常量和前向传播的函数
import mnist_inference
# 配置神经网络的参数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名
MODEL_SAVE_PATH = 'model1/'
MODEL_NAME = 'model.ckpt'
def train(mnist):
# 定义输入输出 placeholder
x = tf.placeholder(
tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input'
)
y_ = tf.placeholder(
tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input'
)
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
# 直接使用bookmnost_inference.py中定义的前向传播过程
y = bookmnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 定义损失函数,学习率,滑动平均操作以及训练过程
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step
)
variable_averages_op = variable_averages.apply(
tf.trainable_variables()
)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=y, labels=tf.argmax(y_, 1)
)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(
loss, global_step=global_step
)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 初始化TensorFlow持久化类
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现
# 验证和测试的过程都将会有一个独立的程序完成
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step],
feed_dict={x: xs, y_: ys})
# 每1000轮保存一次模型
if i % 1000 == 0:
# 输出当前的训练情况,这里只输出了模型在当前训练batch上的损失函数大小
# 通过损失函数的大小可以大概了解训练的情况,在验证集上正确率信息会有一个单独的程序来生成
print("Afer %d training step(s), loss on training batch is %g"%(step, loss_value))
# 保存当前模型,注意这里给出的global_step参数,这样可以让每个被保存模型的文件名末尾加上训练点额轮数
saver.save(
sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME),
global_step=global_step
)
def main(argv=None):
mnist = input_data.read_data_sets('data', one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
运行上面的程式,可以得到类似下面的代码:
Extracting data rain-images-idx3-ubyte.gz Extracting data rain-labels-idx1-ubyte.gz Extracting data 10k-images-idx3-ubyte.gz Extracting data 10k-labels-idx1-ubyte.gz Afer 1 training step(s), loss on training batch is 2.97567 Afer 1001 training step(s), loss on training batch is 0.228694 Afer 2001 training step(s), loss on training batch is 0.161067 Afer 3001 training step(s), loss on training batch is 0.148354 Afer 4001 training step(s), loss on training batch is 0.121623 Afer 5001 training step(s), loss on training batch is 0.106996 Afer 6001 training step(s), loss on training batch is 0.104219 Afer 7001 training step(s), loss on training batch is 0.112429 Afer 8001 training step(s), loss on training batch is 0.077253 ... ... Afer 29001 training step(s), loss on training batch is 0.03582
在新的训练代码中,不再将训练和测试跑一起,训练过程中,每1000轮输出一次在当前训练batch上损失函数的大小来大致估计训练的效果。在上面的程式中,每1000轮保存一次训练好的模型,这样可以通过一个单独的测试程序,更加方便的在滑动平均模型上做测试,下面给出测试程序 mnist_eval.py
#_*_coding:utf-8_*_
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 加载 mnist_inference.py 和 mnist_train.py中定义的常量和函数
import mnist_inference
import mnist_train
# 每10秒加载一次最新的模型,并在测试数据上测试最新模型的正确率
EVAL_INTERVAL_SECS = 10
def evalute(mnist):
with tf.Graph().as_default() as g:
# 定义输入输出格式
x = tf.placeholder(
tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input'
)
y_ = tf.placeholder(
tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input'
)
validate_feed = {x: mnist.validation.images,
y_: mnist.validation.labels}
# 直接通过调用封装好的函数来计算前向传播的额结果
#因为测试时不关注正则化损失的值,所以这里用于计算正则化损失函数被设置为None
y = mnist_inference.inference(x, None)
# 使用前向传播的结果计算正确率,如果需要对未知的样本进行分类,
# 那么使用 tf.argmax(y, 1)就可以得到输入样例的预测类别了
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 通过变量重命名的方式来加载模型,这样在前向传播的过程中就不需要调用求滑动平均的函数获取平均值
# 这样就可以完全共享之前mnist_inference.py中定义的前向传播过程
variable_averages = tf.train.ExponentialMovingAverage(
mnist_train.MOVING_AVERAGE_DECAY
)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
# 每隔EVAL_INTERVAL_SECS 秒调用一次计算正确率的过程以检测训练过程中正确率的变化
while True:
with tf.Session() as sess:
# tf.train.get_checkpoint_state函数会通过checkpoint文件
# 自动找到目录中最新模型的文件名
ckpt = tf.train.get_checkpoint_state(
mnist_train.MODEL_SAVE_PATH
)
if ckpt and ckpt.model_checkpoint_path:
# 加载模型
saver.restore(sess, ckpt.model_checkpoint_path)
# 通过文件名得到模型保存时迭代的轮数
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print("After %s training step(s) , validation accuracy ='%g"%(global_step, accuracy_score))
else:
print("No checkpoint file found")
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
mnist = input_data.read_data_sets('data', one_hot=True)
evalute(mnist)
if __name__ == '__main__':
main()
上面的代码会每隔10秒运行一次,每次运行都是读取最新保存的模型,并在MNIST验证数据上计算模型的正确率。如果需要离线预测未知数据的类别(比如这个样例程序可以判断手写数字图片中所包含的数字),只需要将计算正确率的部分改为答案输出即可。运行上面代码可以得到类似下面的结果,注意因为这个程序每10秒会自动运行一次,而训练程序不一定每10秒输出一个新模型,所以下面的结果中会发现有些模型被测试了多次,一般在解决真实问题时,不会这么频繁的运行评测程序。
Extracting data rain-images-idx3-ubyte.gz Extracting data rain-labels-idx1-ubyte.gz Extracting data 10k-images-idx3-ubyte.gz Extracting data 10k-labels-idx1-ubyte.gz After 29001 training step(s) , validation accuracy ='0.9856 After 29001 training step(s) , validation accuracy ='0.9856 After 29001 training step(s) , validation accuracy ='0.9856 After 29001 training step(s) , validation accuracy ='0.9856 After 29001 training step(s) , validation accuracy ='0.9856 After 29001 training step(s) , validation accuracy ='0.9856 After 29001 training step(s) , validation accuracy ='0.9856 ... ...
知识储备:gfile文件操作详解
1,gfile模块是什么?
gfile模块定义在tensorflow/python/platform/gfile.py,但其源代码实现主要位于tensorflow/tensorflow/python/lib/io/file_io.py,那么gfile模块主要功能是什么呢?
google上的定义为:
翻译过来为:
没有线程锁的文件I / O操作包装器
tf.gfile模块的主要角色是:
- 1.提供一个接近Python文件对象的API
- 2.提供基于TensorFlow C ++ FileSystem API的实现。
C ++ FileSystem API支持多种文件系统实现,包括本地文件,谷歌云存储(以gs://开头)和HDFS(以hdfs:/开头)。 TensorFlow将它们导出为tf.gfile,以便我们可以使用这些实现来保存和加载检查点,编写TensorBoard log以及访问训练数据(以及其他用途)。但是,如果所有文件都是本地文件,则可以使用常规的Python文件API而不会造成任何问题。
以上为google对tf.gfile的说明。
2、gfile API介绍
下面将分别介绍每一个gfile API!
2-1)tf.gfile.Copy(oldpath, newpath, overwrite=False)
拷贝源文件并创建目标文件,无返回,其形参说明如下:
- oldpath:带路径名字的拷贝源文件;
- newpath:带路径名字的拷贝目标文件;
- overwrite:目标文件已经存在时是否要覆盖,默认为false,如果目标文件已经存在则会报错
2-2)tf.gfile.MkDir(dirname)
创建一个目录,dirname为目录名字,无返回。
2-3)tf.gfile.Remove(filename)
删除文件,filename即文件名,无返回。
2-4)tf.gfile.DeleteRecursively(dirname)
递归删除所有目录及其文件,dirname即目录名,无返回。
2-5)tf.gfile.Exists(filename)
判断目录或文件是否存在,filename可为目录路径或带文件名的路径,有该目录则返回True,否则False。
2-6)tf.gfile.Glob(filename)
查找匹配pattern的文件并以列表的形式返回,filename可以是一个具体的文件名,也可以是包含通配符的正则表达式。
2-7)tf.gfile.IsDirectory(dirname)
判断所给目录是否存在,如果存在则返回True,否则返回False,dirname是目录名。
2-8)tf.gfile.ListDirectory(dirname)
罗列dirname目录下的所有文件并以列表形式返回,dirname必须是目录名。
2-9)tf.gfile.MakeDirs(dirname)
以递归方式建立父目录及其子目录,如果目录已存在且是可覆盖则会创建成功,否则报错,无返回。
2-10)tf.gfile.Rename(oldname, newname, overwrite=False)
重命名或移动一个文件或目录,无返回,其形参说明如下:
- oldname:旧目录或旧文件;
- newname:新目录或新文件;
- overwrite:默认为false,如果新目录或新文件已经存在则会报错,否则重命名或移动成功。
2-11)tf.gfile.Stat(filename)
返回目录的统计数据,该函数会返回FileStatistics数据结构,以dir(tf.gfile.Stat(filename))获取返回数据的属性如下:
2-12)tf.gfile.Walk(top, in_order=True)
递归获取目录信息生成器,top是目录名,in_order默认为True指示顺序遍历目录,否则将无序遍历,每次生成返回如下格式信息(dirname, [subdirname, subdirname, ...], [filename, filename, ...])。
2-13)tf.gfile.GFile(filename, mode)
获取文本操作句柄,类似于python提供的文本操作open()函数,filename是要打开的文件名,mode是以何种方式去读写,将会返回一个文本操作句柄。
tf.gfile.Open()是该接口的同名,可任意使用其中一个!
2-14)tf.gfile.FastGFile(filename, mode)
该函数与tf.gfile.GFile的差别仅仅在于“无阻塞”,即该函数会无阻赛以较快的方式获取文本操作句柄