解决的问题
前人的做法:
Success of image translation methods mostly imposes the requirement of working on aligned or similar domains for texture or appearance transform.
The building blocks of these networks, such as convolution/deconvolution layers and activation functions, are spatially corresponding.
解决的问题:

大白话解释一段我的理解:
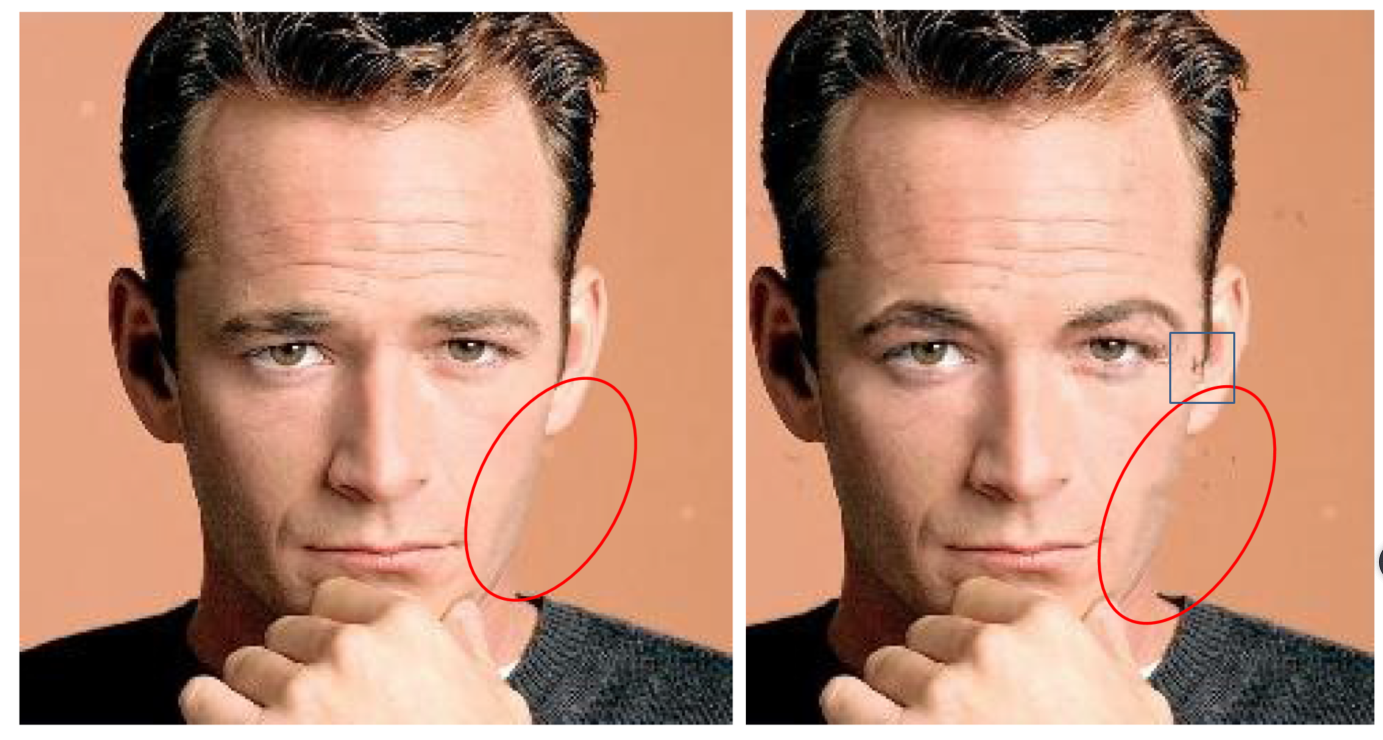
非成对图像翻译,比如非笑脸图(小明,男)要翻译成笑脸图(小明,男)。
输入网络的图,非笑脸图(小明,男)和笑脸图(大红唇的小红,女),经过一系列的convolution/deconvolution layers and activation functions,得到小明的五官信息和大红唇小红的笑信息(maybe 嘴角上扬图),重组以后得到,大红唇的笑脸小明。
结果图中的大红唇可以看作artifacts or ghosting。
期望的效果:

具体策略:
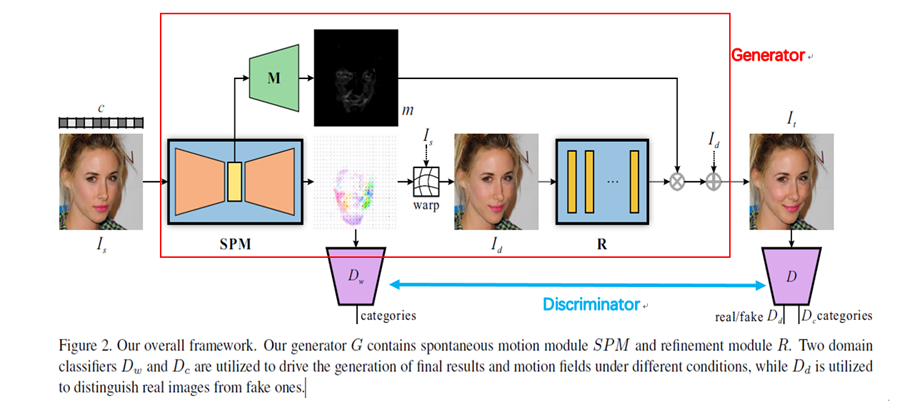
SPM

RM
12个平行采样的残差块,对生成结果进行精细化。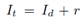
Mask
3 deconvolutional layers to up-sample f into a 1-channel mask m, the same size as the input.
Sigmoid layer is used as the final activation layer to range the output mask in [0; 1].
a regularization term Lm to enforce sparsity of masks in L1-norm:
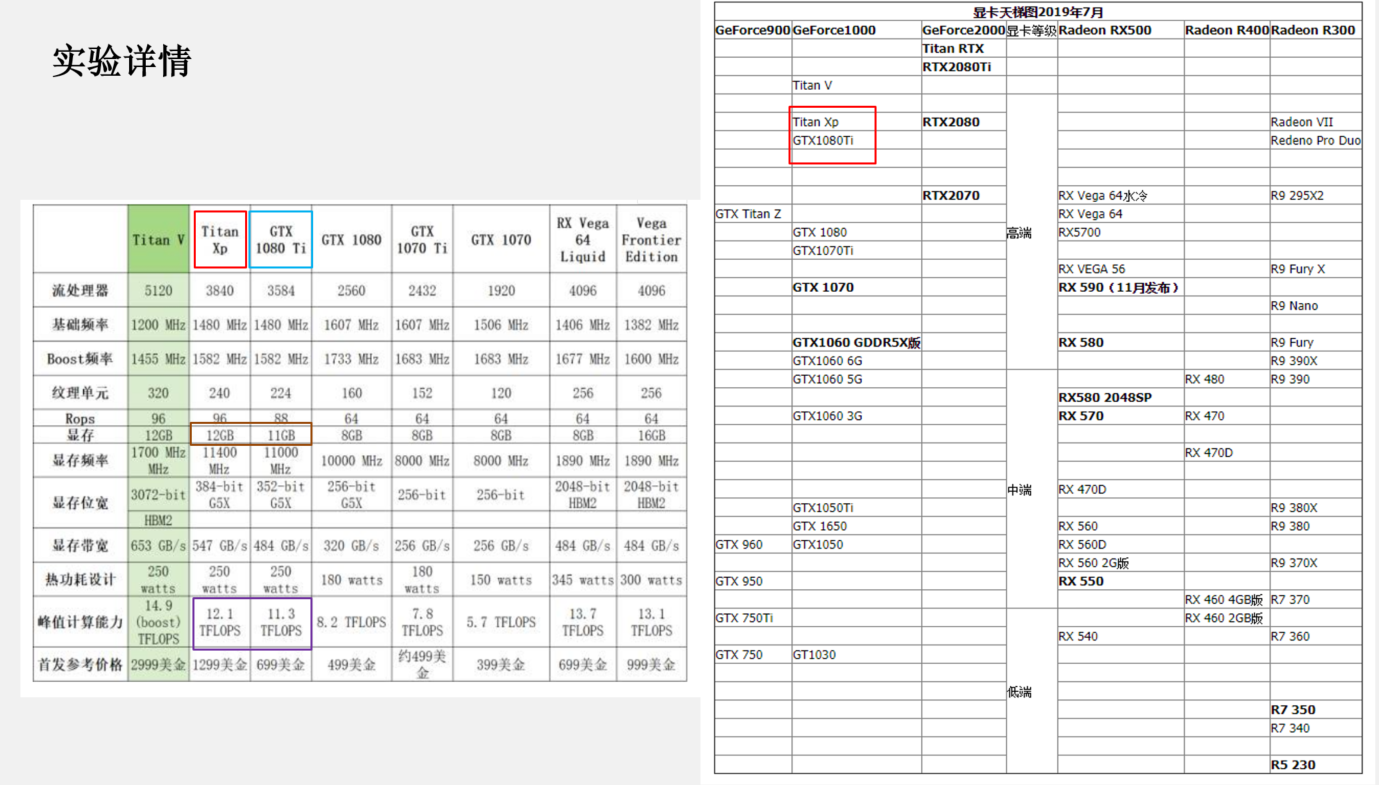
实验详情

实验效果: