我的结论(仅仅代表个人观点)
* 论文代码:https://github.com/swordcheng/FCSR-GAN
* 分辨率不高,16*16 or 32*32/--------------128*128
* 图6,图13,图4,图标有歧义。也许是我理解有问题。
* 恢复出来的图像,遮挡区域模糊,非遮挡区域也发生了改变
* 侧脸处理的还可以。
1、题目
《FCSR-GAN: Joint Face Completion and Super-resolution via Multi-task Learning》
作者:

2、创新点

* The effectiveness of existing face super-resolution approaches is not known when they are applied to low resolution face image with occlusions。
* It is not known whether the face completion approaches work for low-resolution face images or not.
** In this paper, we propose an end-to-end trainable framework based on a generative adversarial network (GAN) for joint face completion and super-resolution via a single model (namely FCSR-GAN).
** This work is an extension of our previous work of FG2019《Fcsr-gan: End-to-end learning for joint face completion and super-resolution》
3、网络框架
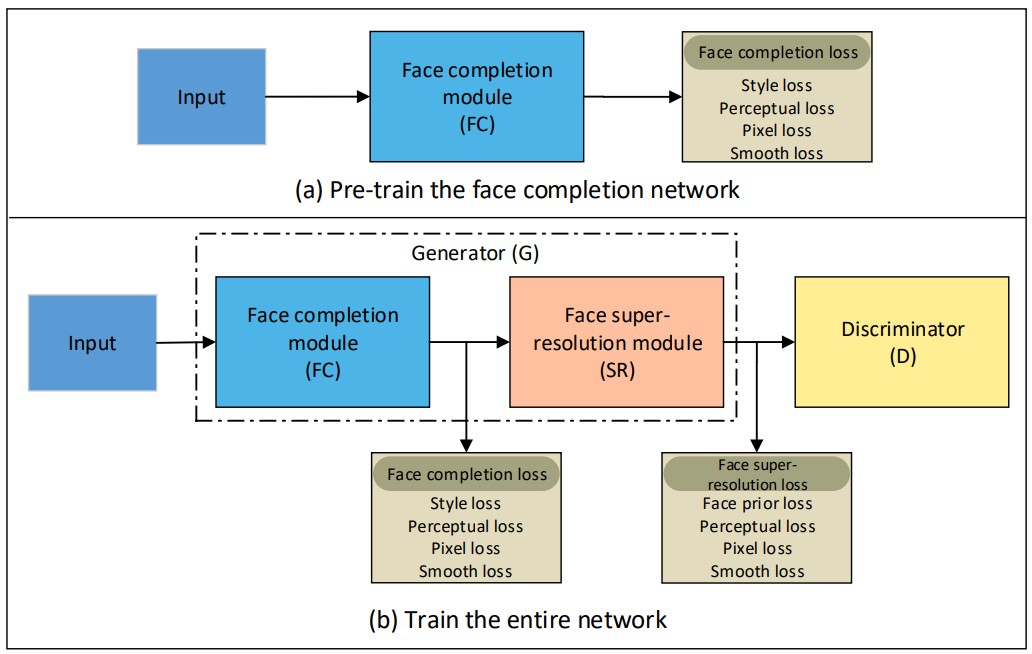
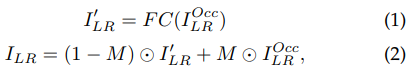
![]()
4、loss函数
* pixel loss

* Perceptual loss
防止pixel loss造成图像平滑,丢失语义信息

* Style loss
减少恢复区域与非遮挡区域边界上的伪影

* Smooth loss
减少补全边界的颜色失真问题

* Face prior loss
保证脸的结构合理


face parsing是自己训练的,landmark是采用的公开的。
* loss_D
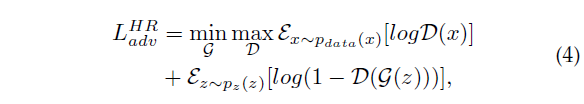
5、两步训练策略
* 训练Fig.2(a), the first-stage train
![]()
权重系数依次是10,0.1,0.1,1
* 训练Fig.2(b), the second-stage train
Fix the fc module, 在Fc module 后面添加了Fr module
![]()
权重系数依次是10.^(-3),1, 0.01,1,0.01
* 训练整个网络
![]()
6、实验
AA、实验数据集
a、CelebA数据集:
数据:10177图,202599个脸
划分:162770训练,19867验证,19962测试。
b、Helen数据集:
数据:2330个脸
划分:2000训练,300测试。
CelebA数据集,进行模型的训练、测试和验证。Helen数据集,训练face parsing module。
BB、训练 face parsing module
* Adam优化算法,学习率10.^(-4)
* Helen采用提供的人脸特征点,根据眼睛点做对齐到144*144大小,然后随机裁剪得到128*128图像
* 训练好的face parsing module去测试celeA中的脸,得到face parsing maps,作为计算Face prior loss的真实label。
* 采用open-source SeetaFace 去测试celeA中的脸,得到81 facial landmarks,作为计算Face prior loss的真实label。
CC、训练FCSR-GAN
* Adam优化算法,学习率10.^(-4)
* CeleA数据对齐到144*144大小,然后随机裁剪得到128*128图像。
* first-stage(Fc), 128*128下采样到32*32 以及 128*128下采样到16*16作为输入。遮挡大小以及范围如图4所示。网络输入、输出大小一致。
* second-stage(Fc+Sr),输入 和first-stage(Fc)输入一致,输出是128*128

DD、结果评价指标

用眼睛看,or用数据说话。
7、实验结果
a、遮挡位置不同的处理结果

(a)是低分辨率有遮挡的输入图像。
(b)如果看图像清晰度,会觉得分辨率提高了,属于高分辨率图像128*128,但是英文标志又是low-resolution w/o occlusion,(with low-resolution,without occlusion)
具体的只有作者知道了。
我支持high-resolution w/o occlusion.
b、不同分辨率的低分图像的处理效果

c、普遍性存在的问题
* 非遮挡区域有改变

* 侧脸处理的比较好


