没有看完呢,
我的结论(仅仅代表个人观点)
* 2020年2月的论文
* 官方论文没有公开代码(20200526)。没有代码,一些重要的结论无法测试和验证。
* 恢复结果结构信息以及图像清晰度得到保障。(第一次看到论文直接说了清晰度这个问题。值得注意)
* 分辨率,256*256
* 正脸和小角度侧脸都好用,大角度侧脸没有给出测试结果,没有代码无法测试。
* 对人脸和日常场景照修复效果都挺好的。
* 论文自己说它比以下论文效果好。
20. 《CE: Context encoders: Feature learning by inpainting》 (CVPP 2016)
28.《Shift-net: Image inpainting via deep feature rearrangement》(ECCV 2017)
26.《GMCNN:Image inpainting via generative mulit-column convolutional neural networks》(NeurIPS 2018)
33.《PICNet:Pluralistic image completion》(CVPR 2019)
1、题目
《Towards Ghost-free Shadow Removal via Dual Hierarchical Aggregation Network and Shadow Matting GAN》
作者:

论文地址:
https://arxiv.org/pdf/1911.08718.pdf
代码地址:
https://github.com/vinthony/ghost-free-shadow-removal
关键词:
dilated convolutions、
2、创新点
a、self-guided regression loss
We propose a novel self-guided regression loss to explicitly correct the low-level features, according to the normalized error map computed by the output and
ground-truth images. This function can significantly improve the semantic structure and fidelity of images
b、a geometrical alignment constraint
We present a geometrical alignment constraint to supplement the shortage of pixel-based VGG features matching loss.
c、a dense multi-scale fusion generator
We propose a dense multi-scale fusion generator, which has the merit of strong representation ability to extract useful features. Our generative image inpainting framework achieves compelling visual results (as illustrated in Figure 1) on challenging datasets, compared with previous state-of-the-art approaches
3、网络框架
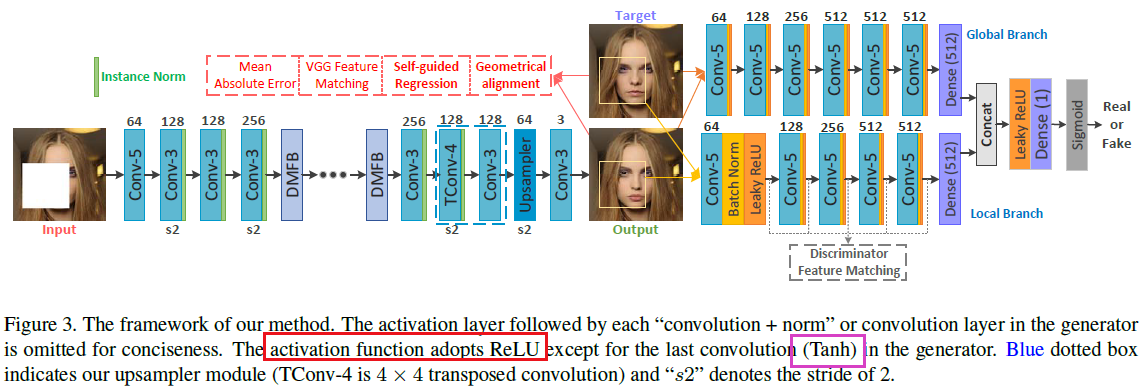
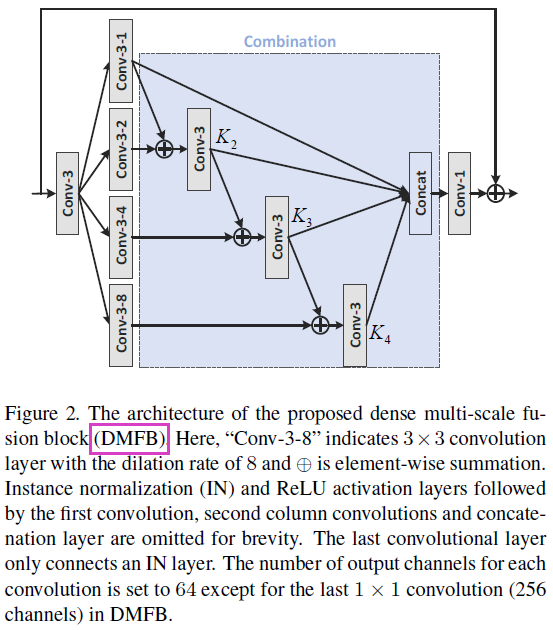
4、loss函数
a、 Self-guided regression loss
b、Geometrical alignment constraint
c、Adversarial loss
d、Overall Loss
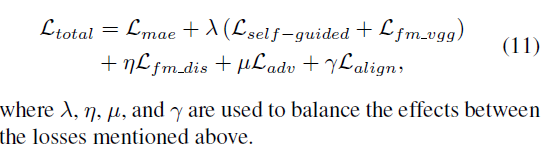
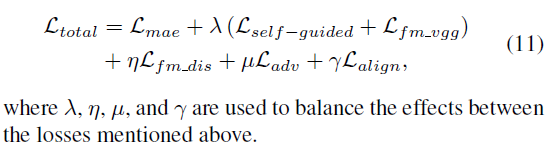
本王中,损失函数的权重依次是25,5,0.03,1
5、实验
AA、实验数据集
a、CelebA-HQ数据集(Progressive growing of gans for improved quality, stability,and variation. In ICLR, 2018. 6)
b、Paris Street View数据集(Context encoders: Feature learning by inpainting. In CVPP, pages 2536–2544, 2016. 1, 2, 6, 7)
c、Places2数据集(Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1452–1464. 6)
d、FFHQ数据集(A style-based generator architecture for generative adversarial networks. In CVPR, pages 4401–4410, 2019. 6)
BB、实验细节
* batch size=16,NVIDIA TITAN Xp GPU(12 GB memory)。
* Adam优化算法,学习率0.0002,beta1=0.5, beta2=0.9。
* 训练+验证:CelebA-HQ、Places2、FFHQ,测试:Paris Street View、CeleA
训练,输入图像大小256*256,hole大小128*128
a、CelebA-HQ数据集,直接resize脸图到256*256。
b、Paris Street View,原始936*537,随机裁剪成537*537,然后直接resize成256*256
c、Places2,原始512*?,随机裁剪成512*512,然后直接resize成256*256
d、FFHQ数据集,直接resize脸图到256*256。
* 端对端,无后处理和预处理。
Igt为原始图像,M为要给Igt增加的mask(对应遮挡区域为1,非遮挡区域为0),Iin=Igt点乘(1-M)(非遮挡区域像素值和Igt一样,遮挡区域像素值为0,表现为黑色)
训练网络输入的是Iin和M,网络预测的结果为Ipred,最后输出结果为Iout=Iin+Ipred点乘M。
All input and output are linearly scaled to [-1; 1].
6、实验结果
a、图像清晰度效果
双眼皮,睫毛等细节信息保留的超级好。


b、正脸or小角度脸的效果

c、非人脸图像的测试效果

