简介
tair 是淘宝自己开发的一个分布式 key/value 存储引擎. tair 分为持久化和非持久化两种使用方式. 非持久化的 tair 可以看成是一个分布式缓存. 持久化的 tair 将数据存放于磁盘中. 为了解决磁盘损坏导致数据丢失, tair 可以配置数据的备份数目, tair 自动将一份数据的不同备份放到不同的主机上, 当有主机发生异常, 无法正常提供服务的时候, 其于的备份会继续提供服务.
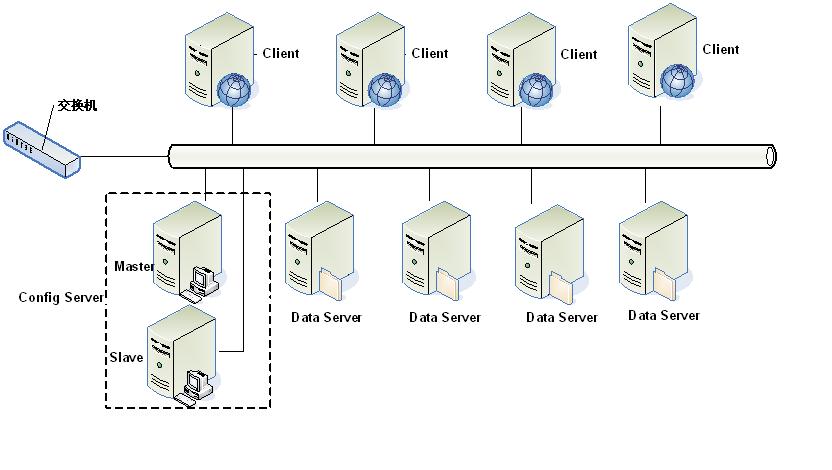
tair 的总体结构
tair 作为一个分布式系统, 是由一个中心控制节点和一系列的服务节点组成. 我们称中心控制节点为config server. 服务节点是data server. config server 负责管理所有的data server, 维护data server的状态信息. data server 对外提供各种数据服务, 并以心跳的形式将自身状况汇报给config server. config server是控制点, 而且是单点, 目前采用一主一备的形式来保证其可靠性. 所有的 data server 地位都是等价的.
tair 的负载均衡算法是什么
tair 的分布采用的是一致性哈希算法, 对于所有的key, 分到Q个桶中, 桶是负载均衡和数据迁移的基本单位. config server 根据一定的策略把每个桶指派到不同的data server上. 因为数据按照key做hash算法, 所以可以认为每个桶中的数据基本是平衡的. 保证了桶分布的均衡性, 就保证了数据分布的均衡性.
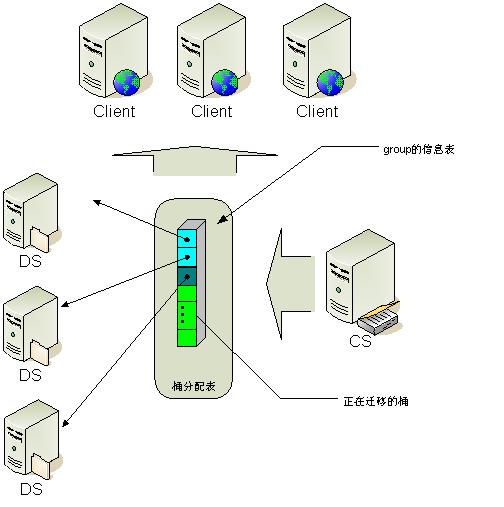
增加或者减少data server的时候会发生什么
当有某台data server故障不可用的时候, config server会发现这个情况, config server负责重新计算一张新的桶在data server上的分布表, 将原来由故障机器服务的桶的访问重新指派到其它的data server中. 这个时候, 可能会发生数据的迁移. 比如原来由data server A负责的桶, 在新表中需要由 B负责. 而B上并没有该桶的数据, 那么就将数据迁移到B上来. 同时config server会发现哪些桶的备份数目减少了, 然后根据负载情况在负载较低的data server上增加这些桶的备份. 当系统增加data server的时候, config server根据负载, 协调data server将他们控制的部分桶迁移到新的data server上. 迁移完成后调整路由. 当然, 系统中可能出现减少了某些data server 同时增加另外的一些data server. 处理原理同上. 每次路由的变更, config server都会将新的配置信息推给data server. 在客户端访问data server的时候, 会发送客户端缓存的路由表的版本号. 如果data server发现客户端的版本号过旧, 则会通知客户端去config server取一次新的路由表. 如果客户端访问某台data server 发生了不可达的情况(该 data server可能宕机了), 客户端会主动去config server取新的路由表.
发生迁移的时候data server如何对外提供服务
当迁移发生的时候, 我们举个例子, 假设data server A 要把 桶 3,4,5 迁移给data server B. 因为迁移完成前, 客户端的路由表没有变化, 客户端对 3, 4, 5 的访问请求都会路由到A. 现在假设 3还没迁移, 4 正在迁移中, 5已经迁移完成. 那么如果是对3的访问, 则没什么特别, 跟以前一样. 如果是对5的访问, 则A会把该请求转发给B,并且将B的返回结果返回给客户, 如果是对4的访问, 在A处理, 同时如果是对4的修改操作, 会记录修改log.当桶4迁移完成的时候, 还要把log发送到B, 在B上应用这些log. 最终A B上对于桶4来说, 数据完全一致才是真正的迁移完成. 当然, 如果是因为某data server宕机而引发的迁移, 客户端会收到一张中间临时状态的分配表. 这张表中, 把宕机的data server所负责的桶临时指派给有其备份data server来处理. 这个时候, 服务是可用的, 但是负载可能不均衡. 当迁移完成之后, 才能重新达到一个新的负载均衡的状态.
桶在data server上分布时候的策略
程序提供了两种生成分配表的策略, 一种叫做负载均衡优先, 一种叫做位置安全优先: 我们先看负载优先策略. 当采用负载优先策略的时候, config server会尽量的把桶均匀的分布到各个data server上. 所谓尽量是指在不违背下面的原则的条件下尽量负载均衡. 1 每个桶必须有COPY_COUNT份数据 2 一个桶的各份数据不能在同一台主机上; 位置安全优先原则是说, 在不违背上面两个原则的条件下, 还要满足位置安全条件, 然后再考虑负载均衡. 位置信息的获取是通过 _pos_mask(参见安装部署文档中关于配置项的解释) 计算得到. 一般我们通过控制 _pos_mask 来使得不同的机房具有不同的位置信息. 那么在位置安全优先的时候, 必须被满足的条件要增加一条, 一个桶的各份数据不能都位于相同的一个位置(不在同一个机房). 这里有一个问题, 假如只有两个机房, 机房1中有100台data server, 机房2中只有1台data server. 这个时候, 机房2中data server的压力必然会非常大. 于是这里产生了一个控制参数 _build_diff_ratio(参见安装部署文档). 当机房差异比率大于这个配置值时, config server也不再build新表. 机房差异比率是如何计出来的呢? 首先找到机器最多的机房, 不妨设使RA, data server数量是SA. 那么其余的data server的数量记做SB. 则机房差异比率=|SA – SB|/SA. 因为一般我们线上系统配置的COPY_COUNT是3. 在这个情况下, 不妨设只有两个机房RA和RB, 那么两个机房什么样的data server数量是均衡的范围呢? 当差异比率小于 0.5的时候是可以做到各台data server负载都完全均衡的.这里有一点要注意, 假设RA机房有机器6台,RB有机器3台. 那么差异比率 = 6 – 3 / 6 = 0.5. 这个时候如果进行扩容, 在机房A增加一台data server, 扩容后的差异比率 = 7 – 3 / 7 = 0.57. 也就是说, 只在机器数多的机房增加data server会扩大差异比率. 如果我们的_build_diff_ratio配置值是0.5. 那么进行这种扩容后, config server会拒绝再继续build新表.
tair 的一致性和可靠性问题
分布式系统中的可靠性和一致性是无法同时保证的, 因为我们必须允许网络错误的发生. tair 采用复制技术来提高可靠性, 并且为了提高效率做了一些优化, 事实上在没有错误发生的时候, tair 提供的是一种强一致性. 但是在有data server发生故障的时候, 客户有可能在一定时间窗口内读不到最新的数据. 甚至发生最新数据丢失的情况.
tair提供的客户端
tair 的server端是C++写的, 因为server和客户端之间使用socket通信, 理论上只要可以实现socket操作的语言都可以直接实现成tair客户端. 目前实际提供的客户端有java 和 C++. 客户端只需要知道config server的位置信息就可以享受tair集群提供的服务了.
--------------------------------------------------------------------------------------------
安装部署:
一 如何安装tair:
- 确保安装了automake autoconfig 和 libtool,使用automake --version查看,一般情况下已安装
- 获得底层库 tbsys 和 tbnet的源代码:(svn checkout http://code.taobao.org/svn/tb-common-utils/trunk/ tb-common-utils).
- 获得tair源代码:(svn checkout http://code.taobao.org/svn/tair/trunk/ tair).
- 安装boost-devel库,在用rpm管理软件包的os上可以使用rpm -q boost-devel查看是否已安装该库
- 编译安装tbsys和tbnet
- 编译安装tair
- tair 的底层依赖于tbsys库和tbnet库, 所以要先编译安装这两个库:
取得源代码后, 先指定环境变量 TBLIB_ROOT 为需要安装的目录. 这个环境变量在后续 tair 的编译安装中仍旧会被使用到. 比如要安装到当前用户的lib目录下, 则指定 export TBLIB_ROOT="/usr/local/tairlib"
进入common文件夹, 执行build.sh进行安装.
- 编译安装tair:
export TBLIB_ROOT="/usr/local/tairlib"
yum install svn automake zlib-deve libtool boost-devel -y
svn checkout http://code.taobao.org/svn/tb-common-utils/trunk/ tb-common-utils
svn checkout http://code.taobao.org/svn/tair/trunk/ tair
进入 tair 目录
运行 bootstrap.sh
运行 configure. 注意, 在运行configue的时候, 可以使用 --with-boost=xxxx 来指定boost的目录. 使用--with-release=yes 来编译release版本.
运行 make 进行编译
运行 make install 进行安装
完成成功后在家目录产生目录tair_bin
二 如何配置tair:
tair的运行, 至少需要一个 config server 和一个 data server. 推荐使用两个 config server 多个data server的方式. 两个config server有主备之分.
源代码目录中 share 目录下有三个配置文件的样例, 下面会逐个解说.
configserver.conf 和 group.conf 这两个配置文件是config server所需要的. 先看这两个配置文件的配置
首先创建配置文件:
#cd /root/tair_bin/etc/
#cp configserver.conf.default configserver.conf ; cp group.conf.default group.conf
- 配置文件 configserver.conf
[public]
config_server=x.x.x.x:5198 (master)
config_server=x.x.x.x:5198 ( slave )
[configserver]
port=5198
log_file=logs/config.log
pid_file=logs/config.pid
log_level=warn
group_file=etc/group.conf
data_dir=data/data
dev_name=eth0 (注意修改)
public 下面配置的是两台config server的 ip 和端口. 其中排在前面的是主config server. 这一段信息会出现在每一个配置文件中. 请保持这一段信息的严格一致.
configserver下面的内容是本config server的具体配置:
port 端口号, 注意 config server会使用该端口做为服务端口, 而使用该端口+1 做为心跳端口,即5199
log_file 日志文件
pid_file pid文件, 文件中保存当前进程中的pid
log_level 日志级别
group_file 本config server所管理的 group 的配置文件
data_dir 本config server自身数据的存放目录
dev_name 所使用的网络设备名
注意: 例子中, 所有的路径都配置的是相对路径. 这样实际上限制了程序启动时候的工作目录. 这里当然可以使用绝对路径.
注意: 程序本身可以把多个config server 或 data server跑在一台主机上, 只要配置不同的端口号就可以. 但是在配置文件的时候, 他们的数据目录必须分开, 程序不会对自己的数据目录加锁, 所以如果跑在同一主机上的服务, 数据目录配置相同, 程序自己不会发现, 却会发生很多莫名其妙的错误. 多个服务跑在同一台主机上, 一般只是在做功能测试的时候使用.
- 配置文件 group.conf
#group name
[group_1]
# data move is 1 means when some data serve down, the migrating will be start.
# default value is 0
_data_move=1
#_min_data_server_count: when data servers left in a group less than this value, config server will stop serve for this group
#default value is copy count.
_min_data_server_count=4
_copy_count=3
_bucket_number=1023
_plugIns_list=libStaticPlugIn.so
_build_strategy=1 #1 normal 2 rack
_build_diff_ratio=0.6 #how much difference is allowd between different rack
# diff_ratio = |data_sever_count_in_rack1 - data_server_count_in_rack2| / max (data_sever_count_in_rack1, data_server_count_in_rack2)
# diff_ration must less than _build_diff_ratio
_pos_mask=65535 # 65535 is 0xffff this will be used to gernerate rack info. 64 bit serverId & _pos_mask is the rack info,
_server_list=x.x.x.x:5191
_server_list=x.x.x.x:5191
_server_list=x.x.x.x:5191
_server_list=x.x.x.x:5191
#quota info
_areaCapacity_list=1,1124000;
_areaCapacity_list=2,1124000;
每个group配置文件可以配置多个group, 这样一组config server就可以同时服务于多个 group 了. 不同的 group 用group name区分
_data_move 当这个配置为1的时候, 如果发生了某个data server宕机, 则系统会尽可能的通过冗余的备份对数据进行迁移. 注意, 如果 copy_count 为大于1的值, 则这个配置无效, 系统总是会发生迁移的. 只有copy_count为1的时候, 该配置才有作用.
_min_data_server_count 这个是系统中需要存在的最少data server的个数. 当系统中可正常工作的data server的个数小于这个值的时候, 整个系统会停止服务, 等待人工介入
_copy_count 这个表示一条数据在系统中实际存储的份数. 如果tair被用作缓存, 这里一般配置1. 如果被用来做存储, 一般配置为3。 当系统中可工作的data server的数量少于这个值的时候, 系统也会停止工作. 比如 _copy_count 为3, 而系统中只有 2 台data server. 这个时候因为要求一条数据的各个备份必须写到不同的data server上, 所以系统无法完成写入操作, 系统也会停止工作的.
_bucket_number 这个是hash桶的个数, 一般要 >> data server的数量(10倍以上). 数据的分布, 负载均衡, 数据的迁移都是以桶为单位的.
_plugIns_list 需要加载的插件的动态库名
_accept_strategy 默认为0,ds重新连接上cs的时候,需要手动touch group.conf。如果设置成1,则当有ds重新连接会cs的时候,不需要手动touch group.conf。 cs会自动接入该ds。
_build_strategy 在分配各个桶到不同的data server上去的时候所采用的策略. 目前提供两种策略. 配置为1 则是负载均衡优先, 分配的时候尽量让各个 data server 的负载均衡. 配置为 2 的时候, 是位置安全优先, 会尽量将一份数据的不同备份分配到不同机架的机器上. 配置为3的时候,如果服务器分布在多个机器上,那么会优先使用位置安全优先,即策略2. 如果服务器只在一个机架上,那么退化成策略1,只按负载分布。
_build_diff_ratio 这个值只有当 _build_strategy 为2的时候才有意义. 实际上是用来表示不同的机架上机器差异大小的. 当位置安全优先的时候, 如果某个机架上的机器不断的停止服务, 必然会导致负载的极度不平衡. 当两个机架上机器数量差异达到一定程度的时候, 系统也不再继续工作, 等待人工介入.
_pos_mask 机架信息掩码. 程序使用这个值和由ip以及端口生成的64为的id做与操作, 得到的值就认为是位置信息. 比如 当此值是65535的时候 是十六进制 0xffff. 因为ip地址的64位存储的时候采用的是网络字节序, 最前32位是端口号, 后32位是网络字节序的ip地址. 所以0xffff 这个配置, 将认为10.1.1.1 和 10.2.1.1 是不同的机架.
_areaCapacity_list 这是每一个area的配额信息. 这里的单位是 byte. 需要注意的是, 该信息是某个 area 能够使用的所有空间的大小. 举个具体例子:当copy_count为3 共有5个data server的时候, 每个data server上, 该area实际能使用的空间是这个值/(3 * 5). 因为fdb使用mdb作为内部的缓存, 这个值的大小也决定了缓存的效率.
- data server的配置文件
[public]
config_server=172.23.16.225:5198
config_server=172.23.16.226:5198
[tairserver]
storage_engine=mdb
mdb_type=mdb_shm
mdb_shm_path=/mdb_shm_path01
#tairserver listen port
port=5191
heartbeat_port=6191
process_thread_num=16
slab_mem_size=22528
log_file=logs/server.log
pid_file=logs/server.pid
log_level=warn
dev_name=bond0 (注意修改)
ulog_dir=fdb/ulog
ulog_file_number=3
ulog_file_size=64
check_expired_hour_range=2-4
check_slab_hour_range=5-7
[fdb]
# in
# MB
index_mmap_size=30
cache_size=2048
bucket_size=10223
free_block_pool_size=8
data_dir=fdb/data
fdb_name=tair_fdb
下面解释一下data server的配置文件:
public 部分不再解说
storage_engine 这个可以配置成 fdb 或者 mdb. 分别表示是使用内存存储数据(mdb)还是使用磁盘(fdb).
mdb_type 这个是兼容以前版本用的, 现在都配成mdb_shm就可以了
mdb_shm_path 这个是用作映射共享内存的文件.
port data server的工作端口
heartbeat_port data server的心跳端口
process_thread_num 工作线程数. 实际上启动的线程会比这个数值多, 因为有一些后台线程. 真正处理请求的线程数量是这里配置的.
slab_mem_size 所占用的内存数量. 这个值以M为单位, 如果是mdb, 则是mdb能存放的数据量, 如果是fdb, 此值无意义
ulog_dir 发生迁移的时候, 日志文件的文件目录
ulog_file_number 用来循环使用的log文件数目
ulog_file_size 每个日志文件的大小, 单位是M
check_expired_hour_range 清理超时数据的时间段. 在这个时间段内, 会运行一个后台进程来清理mdb中的超时数据. 一般配置在系统较空闲的时候
check_slab_hour_range 对slap做平衡的时间段. 一般配置在系统较空闲的时候
index_mmap_size fdb中索引文件映射到内存的大小, 单位是M
cache_size fdb中用作缓存的共享内存大小, 单位是M
bucket_size fdb在存储数据的时候, 也是一个hash算法, 这儿就是hash桶的数目
free_block_pool_size 这个用来存放fdb中的空闲位置, 便于重用空间
data_dir fdb的数据文件目录
fdb_name fdb数据文件名
三 运行前的准备:
因为系统使用共享内存作为数据存储的空间(mdb)或者缓存空间(fdb), 所以需要先更改配置, 使得程序能够使用足够的共享内存. scripts 目录下有一个脚本 set_shm.sh 是用来做这些修改的, 这个脚本需要root权限来运行.
四 如何启动集群:
在完成安装配置之后, 可以启动集群了. 启动的时候需要先启动data server 然后启动cofnig server. 如果是为已有的集群添加dataserver则可以先启动dataserver进程然后再修改gruop.conf,如果你先修改group.conf再启动进程,那么需要执行touch group.conf;在scripts目录下有一个脚本 tair.sh 可以用来帮助启动 tair.sh start_ds 用来启动data server. tair.sh start_cs 用来启动config server. 这个脚本比较简单, 它要求配置文件放在固定位置, 采用固定名称. 使用者可以通过执行安装目录下的bin下的 tair_server (data server) 和 tair_cfg_svr(config server) 来启动集群.
1、 /root/tair_bin/tair.sh start_ds
2、 /root/tair_bin/tair.sh start_cs
3、测试是否启动成功
/root/tair_bin/sbin/tairclient -c 172.16.65.31:5198 -g group_1
TAIR> put k1 v1
put: success
TAIR> put k2 v2
put: success
TAIR> get k2
KEY: k2, LEN: 2
作用:移除指定的(key,data)
说明:输出如下帮助信息
SYNOPSIS : remove key [area]
key: 指定想要移除的key。
area: 指定某个命名空间,默认值为0
TAIR>remove keyname 0
