1.1 一维数组
一维数组的声明: int a[10]; 这里a就是一个数组. 数组a的类型就是一个指向整型的常量指针.
但是数组和指针是**不相同**的.
**数组具有特定数量的元素,而指针只是一个标量值.**
只有但数组名在表达式中使用时,编译器才会为它产生一个指针常量.(注意是指针常量,不是指针变量)
1.2 数组下标
如有 int b[10];
则 *(b + 3) 代表的就是b[3]
除了优先级之外,下标引用和间接访问完全相同
所以 array[subscript] 和 (array + (subscript) ) 完全相同.在使用下标引用的地方,你可以使用对等的指针表达式来代替.
** 下标可以是负数 **
如:
int array[10];
int ap = array + 2;
由于ap 指向array 的第三个元素, ap[-1] 指向 array的第二个元素.
下标越界是非法的
ap[9] 是非法的.
一个奇葩 2[array] **
它是合法的,把它转换成对等的间接访问表达式,为 (2 + (array) ) ,去掉内括号,交换 array 和 2 的位置, 得 (array+ 2). 也就是array[2]
1.3 指针与下标
假定可以互换使用指针和下标.下标绝对不会比指针更有效率,但指针有时会比下标更有效率.
比较编译器对指针和下标的处理过程.:
//下标循环
int array[10], a;
for(a = 0; a < 10; a +=1)
array[a] = 0;
为了对下标表达式求值,编译器在程序中插入指令,取得 a 的值,并把它与整型的长度(4)相乘.这个乘法需要话费一定的时间和空间.
//指针
int array[10], *ap;
for( ap = array; ap < array + 10; ap++)
*ap = 0;
尽管这里不存在下标计算,但是还是存在乘法运算.乘法运算出现在for语句的调整部分, ap++ 中这个值必须与整型的长度相乘.然后再与指针相加.
但这里在循环每次执行的时,执行乘法运算的都是两个相同的数(1和4, 步长和整型元素长度). 结果这个乘法只是在编译时执行一次,即程序中现在包含来一条指令,把4与指针相加,程序在运行时并不执行乘法运算.
1.4 数组与指针
指针和数组是不相等的.
例子:
int a[5];
int *b;
- 他们都具有指针指,他们都可以进行间接下标引用操作.
- 区别:1)声明一个数组,编译器将根据声明所指定的元素数量为数组保留内存空间,然后再创建数组名,它的值是一个常量,指向这段空间的起始位置.声明一个指针变量时,编译器只为指针本身保留内存空间,它并不为任何整型值分配内存空间.2)指针变量并未初始化为指向任何现有的内存空间,如果它是一个自动变量,它甚至根本不会被初始化.
所以 int *b;是非法的 *b 将访问内存中某个不确定的位置,或者导致程序终止. 但是b++ 可以编译通过,但是a++却不行.因为a 的值是一个常量.
1.5 作为函数参数的数组名
当一个数组名作为参数传递给一个函数时.
数组名的值就是一个指向数组第一个元素的指针.所以此时传递给函数的是一份该指针的拷贝.
函数如果执行来下标引用,实际上是对这个指针执行间接访问操作,并且通过这种间接访问,函数可以访问和修改调用程序的数组元素.
表面上看,C语言中函数的参数都是值传递,但是参数是指针的时候为什么有变成地址传递了?这是不是矛盾?
先说结论,实际上,C中所有的函数参数都是值传递.数组名也不例外.传递的参数是一份拷贝,(指向数组起始位置的指针拷贝),所以函数可以自由地操作它的指针型参,而不必担心会修改对应的作为实参的指针.
如果传递了一个指向某个变量的指针,而函数对该指针执行了间接访问操作,那么函数就可以修改那个变量.
例子:
//把第二个参数中的字符串复制到第一个参数指定的缓冲区
void strcpy(char *buffer, char const *string) {
//重复复制字符,知道遇见NULL字节
while( (*buffer++ = *string++) != '�')
;
}
1.6 声明数组参数
如果你想把一个数组名参数传递给函数,准确的函数形参应该是怎样的?它是因该声明为一个指针还是一个数组?
实际上,调用函数时实际上传递的是一个指针,所以函数的形参实际上是一个指针.编译器实际上也接受数组形式的参数.
int strlen( char *string);
int strlen( char string);
在这里,strlen的两种传参方式是一样的.
两种声明都可以,但是哪个“更加准确呢”,答案是指针. 因为实参实际上是一个指针,而不是数组. 同样,表达式 sizeof sting的值是指向字符的指针长度,而不是数组的长度.
为什么函数原型中的一维数组形参无需写明它的元素数目,因为函数并不为数组分配内存空间.形参只是一个指针,它指向的是已经在其他地方分配好内存的空间,这个事实解释了为什么数组形参可以与任何长度的数组匹配-- 它实际传递的只是数组第一个元素的指针.另一方面,这种实现方案使函数无法知道数组的长度.如果函数需要知道数组的长度,它必须作为一个显式的参数传递给函数.
比如这样,
char *find_char(char *source, int length, char *given);
1.7 数组的初始化
int vector[5] = {10, 20 ,30, 40, 50};
静态和自动初始化
数组的初始化方式类似于标量变量的初始化方式--也就是取决于他们的存储类型.存储于静态内存的数组只初始化一次,也就是在程序开始执行之前.程序并不要执行指令把这些值放到何时的位置,他们一开始就在哪里了.这个魔术是由连接器完成的,它用包含可执行程序的文件中何时的值对数组元素进行初始化.如果数组未被初始化,数组元素的初始值将会自动设置为0. 当这个文件载入到内存中准备执行时,初始化后的数组值和程序指令一样也被载入到内存中.因此,当程序执行时,静态数组已经初始化完毕.
对于自动变量而言,初始化过程就没有那么浪漫了.因为自动变量位于运行时堆栈中,执行每次进入他们所在的代码块时,这类变量每次所处的内存位置可能并不相同.在程序开始前,编译器没有办法对这些位置进行初始化.所以自动变量在缺省情况下是未初始化的.如果自动变量的声明中给出了初始值,每次当执行流进入自动变量声明所在的作用域时,变量就被一条隐式的赋值语句初始化.这条隐式的复制语句和普通的赋值语句一样需要时间和空间来执行.数组的问题在于初始化列表中可能有很多值,这就可能产生许多条复制语句.对于那些非常盘大的数组,它的初始化时间可能非常可观.
如果数组初始化位于局部于一个函数时,你因该仔细考虑一下,在程序的执行流每次进入函数时,每次都对数组进行初始化是不是值得,如果不值得,就把数组声明为static.这样改变数组的存储区为静态区,只需在程序开始前执行一次.
1.8 自动计算数组长度
int vector[] = {1, 2, 3, 4, 5};
如果声明中并未给出数组的长度,编译器就把数组的长度设置为刚好能够容纳所有的初始值的长度. 如果初始值列表经常修改,这个技巧尤其有用.
1.9 字符数组的初始化
如果根据对整型数组的初始化,我们可以这样初始化字符数组
int a[] = {1, 2, 3, 4, 5};
char message[] = {'H', 'e', 'l', 'l', 'o', 0};
但这也太笨了.
C支持我们这样做:
char message[] = “Hello";
它看上去像是一个字符串常量,实际上并不是. 它只是前例的初始化列表的另一种写法.
如何区分字符串常量和这种初始化列表呢?
当用于初始化一个字符数组时它就是一个初始化列表,在其他任何地方,它都表示一个字符常量.
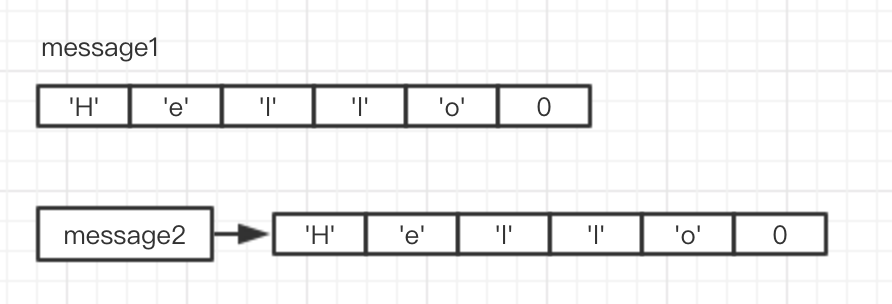
char message1[] = "Hello";//字符数组
char *message2 = "Hello";//字符常量
二者的内存分配区别图示
2、多维数组
数组的维数不只一个,就是多维数组.
int matrix[2][3];
2.1 存储顺序
int matrix[6][10];
int *mp;
mp = &matrix[3][8];
? matrix 是6行10列还是 10行6列?
答案是两种解释都可以.
因为在内存中,数组元素的实际存储方式是确定的.
2.2 数组名
一维数组名的值是一个指针常量,它的类型是“指向元素类型的指针”,它指向数组的第一个元素.
多维数组名也类似, 它指向第一维的元素实际上是另一个数组.
int matrix[3][10];
可以看作是一个一维数组,包含3个元素,只是每个元素恰好是包含10个整型元素的数组.
matrix 这个名字的值是一个指向它第一个元素的指针,matrix是一个指向一个包含10个整型元素的数组的指针.
2.3 下标
下标引用实际上只是间接表达式的一种伪装形式,在多维数组中也是如此.
matrix 指向第一个包含10个整型元素的数组.
matrix + 1 指向第二个包含10个整型元素的数组.

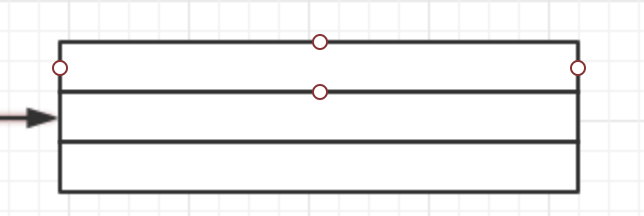
*(matrix + 1)
事实上标示了一个包含10个整型元素的子数组.数组名的值是一个常量指针.它指向数组的第一个元素,在这个表达式中也是如此.
它的类型是指向整型的指针.
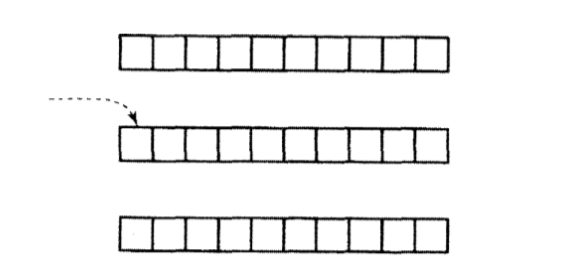
*(matrix + 1) + 5
由于 *(matrix + 1) 是个指向整型的指针,所以5个这个值根据整型的长度进行调整.整个表达式的结果是一个指针.它指向的位置比原先那个表达式所指向的位置向后移动了5个整型元素.

对这个指针所指向的值进行间接访问操作:
*( *(matrix + 1) + 5) 它所指向的正是图中箭头标示的元素. 如果它作为右值,就取得存储于那个位置的值;如果它作为左值使用,这个位置将存储一个新值.
这个表达式实际上就是下标
*( matrix + 1) 即 matrix[1]
( (matrix + 1) + 5) 即 *( matrix[1] + 5)
还可以再次用下标代替间接访问符
即 matrix[1][5]
**注意: 不能用都好分割来表示多维数组 例如 matrix[4, 3]; 它不是 4X3的矩阵,它只是一个含有3个元素的 一维数组,因为编译器会忽略逗号前的4;
2.4 指向数组的指针
下面的声明合法嘛?
int vector[10], vp = vector;
int matrix[3][10], mp = matrix;
结论:第一个合法,第二个非法.
第一个,它为一个整型数组分配内存,并把vp声明为一个指向整型的指针,并把它初始化为指向vector数组的第一个元素.vector和vp具有相同的类型:指向整型的指针.
第二个,它正确的创建来matrix二维数组,并把mp声明为一个指向整型数组的指针.我们因该这样声明一个指向整型数组的指针,
int (p)[10];
这个声明看起来有点复杂,但是它事实上并不是很难.你只要假定它是一个表达式并对他求值.下标优先级高于间接访问,但由于括号的存在,首先执行的还是间接访问,所以p是个指针,但它指向什么呢?接下来是下标引用,所以p指向某种类型的数组.这个声明表达式中没有更多的操作符,所以每个数组的每个元素都是整数.
所以第二个声明加初始化后是下面这个样子:
int (p)[10] = matrix;
它使p指向matrix的第1行.
**但是不能这样声明: Int (p)[] = matrix; 这样数组的长度不见了. **
有的编译器能捕捉到这样的错误,有的捕捉不到.
2.5 作为函数参数的多维数组
作为函数参数的多维数组名的传递方式和一维数组名相同--实际传递的是个指向数组第一个元素的指针.但是,两者之间的区别在于,多维数组的每个元素本身是另外要给数组,编译器需要知道它的维数,以便为函数形参的下标表达式进行求值.这里有两个理智,说明了他们之间的区别:
int vertor[10];
func1(vector):
参数vector的类型是指向整型的指针,所以 func1的原型可以是下面两种中的任何一种:
void func1(int *vec);
void func1(int vec[]);
作用于vec上面的指针运算把整型的长度作为它的调整因子.
对于矩阵
int matrix[3][10];
func2(matrix);
这里的参数matrix的类型是指向包含10个整型元素的数组的指针.func2的原型可以是下面两种形式中的任何一种
void func2( int (*mat)[10] );
void func2 (int mat[][10] );
mat的第一个下标根据包含10个元素的整型数组的长度进行调整,接着第二个下标根据整型的长度进行调整,这个原先的matrix数组一样.
这里的关键在于,编译器必须知道第2个以及以后各维的长度才能对各下标进行求值,因此在原型中必须声明这些维的长度.第1维的长度并不需要,因为计算下标值时用不到它.
注意:
把func2 写成下面是不正确的:
void func2(int **mat);
把mat声明为一个指向整型指针的指针,它和指向整型数组的指针并不是一回事.
2.6 初始化
对于多维数组,数组元素的存储顺序就变得非常重要.
一种是只给出一个常常的初始序列的值
int matrix[2][3] = {10, 11, 12, 13, 14, 15 };
第二种,基于多维数组实际上是福大元素的一维数组这个概念.
例如 声明
int tow_dim[3][5];
int tow_dim[3][5] = {*, *, *} ;//*代表一个复杂元素
int tow_dim[3][5] = {
{0, 1, 2, 3, 4,},
{10, 11, 12, 13, 14,},
{20, 21, 22, 23, 24}
};
使用缩进是非必须的,但是这样做更加有利于阅读.
3、指针数组
除了类型之外,指针变量和其他变量很相似.正如你可以创建整型数组一样,你也可以声明指针数组.
例如:
int api[10];
为了弄清楚这个复杂的声明,我们假定它是一个表达式,并对它进行求值.
下标优先级高于间接访问,所以在这个表达式中,首先执行下标引用.因此,api是某种类型的数组(它包含10个元素).在取得一个数组元素之后,随机执行的是间接访问操作.这个表达式不再有其他操作符,所以它的结果是一个整型.
对数组的某个元素执行间接访问操作后,我们得到一个整型值,所以api肯定是个数组,它的元素类型是指向整型的指针.
关于运算符优先级:
运算符优先级.
什么地方会用到指针数组呢?
例子:
//数组
char const keyword[] = {
"do",
"for",
"if",
"register",
"return",
"switch",
"while"
};
#define N_KEYWORD
( sizeof(keyword)/sizeof(keyword[0]) )
sizeof(keyword)是整个数组所占用的字节数.而sizeof(keyword[0])的结果则是每个元素所占的字节数.这两个值相除就是数组元素的个数.
这个数组可以用于计算一个C源文件中关键字个数的程序中.
思考
如果这样声明呢?
char const keyword[][9] = {
"do",
"for",
"if",
"register",
"return",
"switch",
"while"
};
这个声明创建了一个矩阵:它每行的长度刚好容纳最长的关键字
char const keyword[][9]的内存布局:
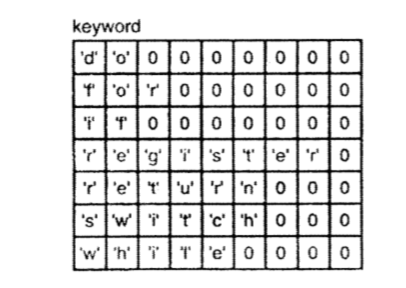
char const keyword[]的内存布局
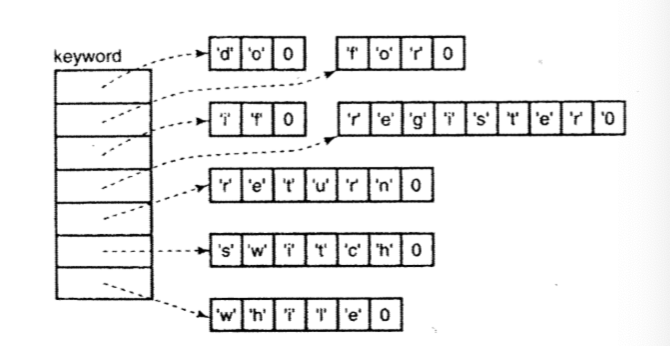
矩阵的存储方式看上去效率低一些,因为它的每一行的长度都被固定为刚好能容纳最长的关键字.但是它不需要任何指针.
另外,指针数组本身也要占用空间,但是每个字符串常量占据的内存空间只能是它本身的长度.
如果字字符集中字符串的长度都差不多,那么用矩阵的方式紧凑些,
如果字符集中字符串的长度千差万别,甚至有超长字符串,可以用指针数组.
人们时常选择指针数组方案,但是略微改动
char const *keyword[] = {
"do",
"for",
"if",
"register",
"return",
"switch",
"while",
NULL
};
在表的末尾增加了一个NULL指针.这个NULL指针使函数在搜索这个表时能够检测到表的结束,而无需预先知道表的长度.
for( kwp = keyword_table; *kwp != NULL; kwp++)