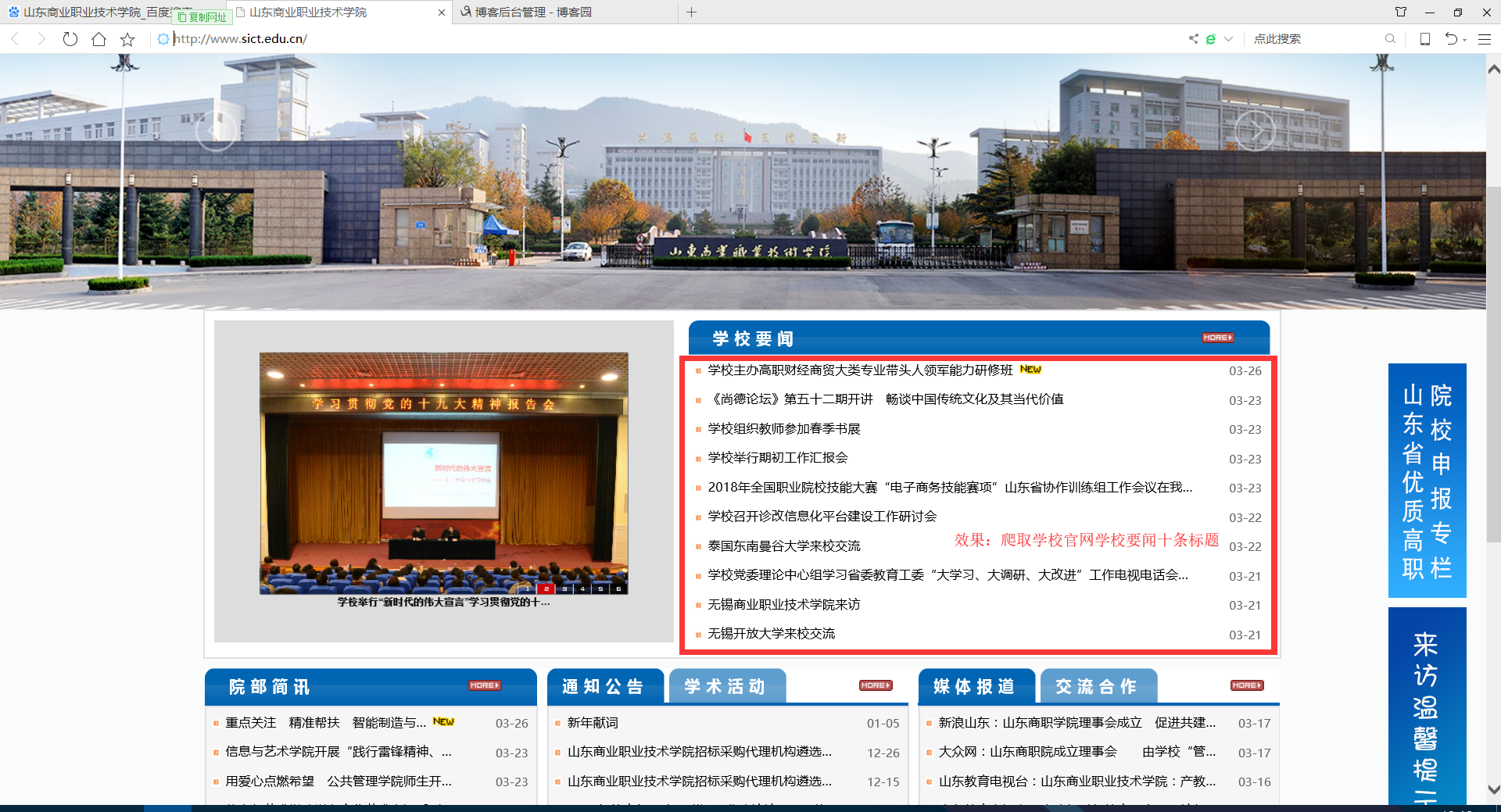
利用Python网络爬虫爬取学校官网十条标题
案例代码:
# __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urllib.request import re import pymysql # 创建一个类用于获取学校官网的十条标题 class GetNewsTitle: # 构造函数 初始化 def __init__(self): self.request = urllib.request.Request("http://www.sict.edu.cn/") # 需要爬取的网址 # 利用正则表达式筛选数据 self.my_re = re.compile( r'学校要闻.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'"a2" >(.*?)</a>.*?' + r'院部简讯') # 创建一个方法 def get_html(self): try: response = urllib.request.urlopen(self.request) # 获取目标网页源码 my_html = response.read().decode('GB2312').replace(" ", "") return my_html except urllib.request.HTTPError as e: print(e.code) print(e.reason) return # 创建一个函数,利用正则获取指定标题 def get_titles(self, my_html): news_titles = re.findall(self.my_re, my_html) return news_titles # 创建一个方法,把获取到的标题存入mysql数据库 def into_mysql(self, titles): for num in range(10): connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', db='school', charset='utf8') cursor = connection.cursor() sql = "INSERT INTO `newsTitles` (`title`) VALUES ('" + titles[0][num] + "')" cursor.execute(sql) connection.commit() cursor.close() connection.close() # 执行函数的入口 def start(self): self.into_mysql(self.get_titles(self.get_html())) print("存储成功!") # 实例化类 s = GetNewsTitle() # 调用方法开始执行 s.start()
效果:
