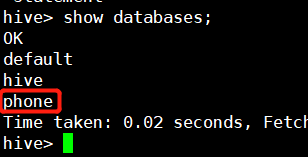
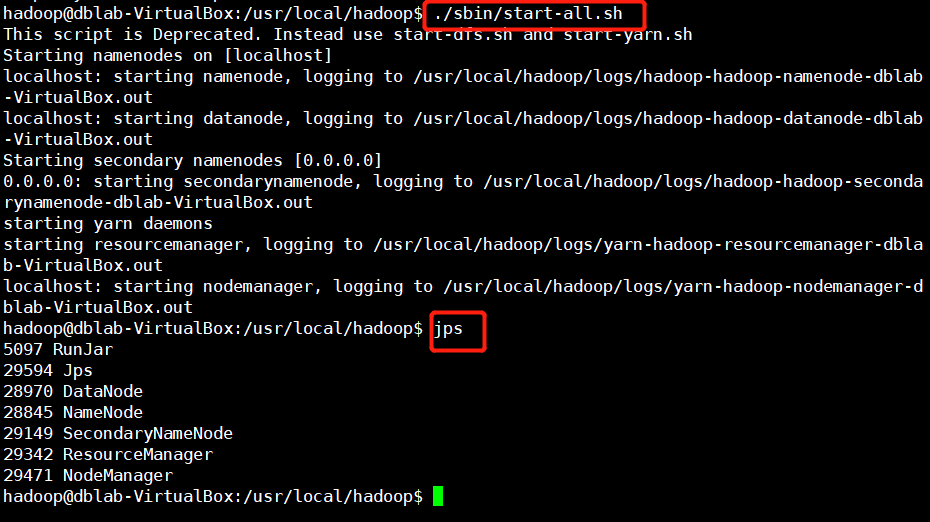
1. 进入Hadoop环境(在Hadoop安装目录下运行命令、若配置好ssh则可以直接运行启动命令)
2. 启动hive进程(按照网上或林子雨的配置教程来就可以,不再赘述)
进入到shell
![]()
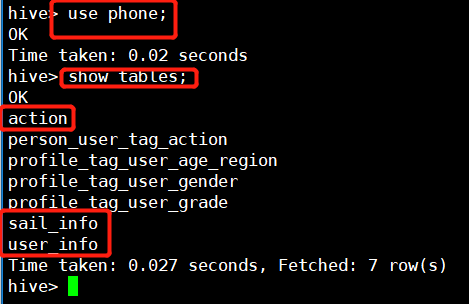
3.加载数据到hive数据库(在项目实操中不建议查询语句为select *,而应根据列名查询,若只是查看表结构及数据效果,建议加limit,不然要机子要崩~~沙卡拉卡)


hive> show tables; ##查看表 hive> desc formatted hive_table; ##描述表信息 desc hive_table hive> alter table 表名 rename to 新名; ##更改表名 hive> alter table 表名 add columns (列名 类型); ##增加列 hive> alter table 表名 change id test_id int; ##修改列名id为test_id hive> alter table 表名 change test_id id double after age; ## test_id改名为id并放到age后面 hive> alter table 表名 replace columns (cc int,bb string,id int); ##替换列(修改和替换全表的列) hive> truncate table stu_info; ##清除数据 truncate 只清除表的数据 hive> drop table stu_test; ##删除表以及表的元数据信息 hive> drop database hive_drop; #删除数据库 hive> drop database hive_test CASCADE; ##删除有表的数据库 hive> dese function when; ##查看函数用法 hive> dese function extended case; ##查看函数的详细用法
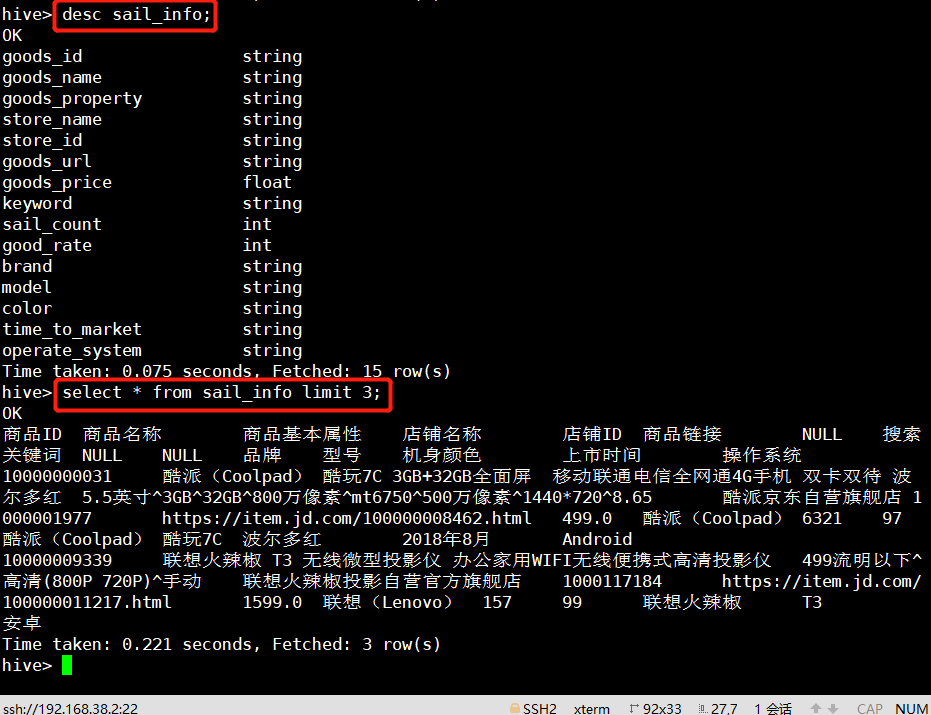
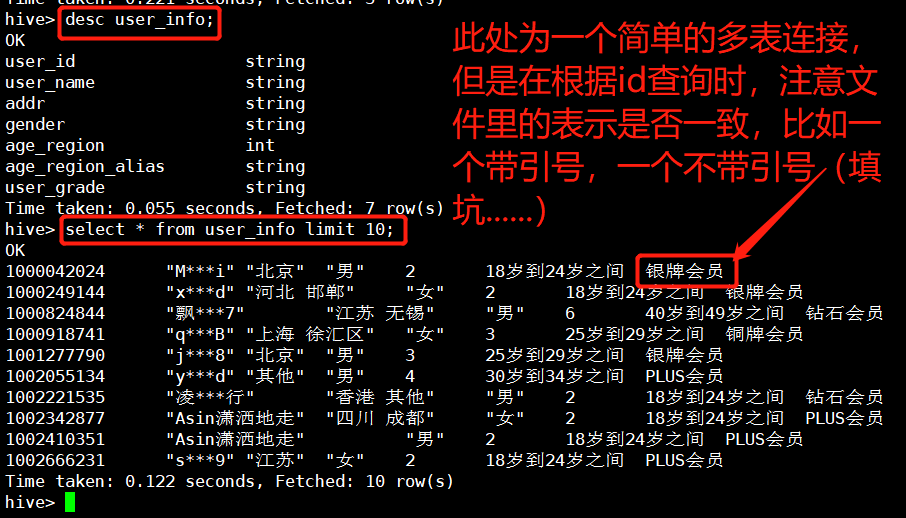
1. action表 use kettle; create table action1 ( user_id string , goods_id string, user_action int, deal_month string, deal_day string ) row format delimited fields terminated by ',' ; //通过逗号分隔 加载本地数据 load data local inpath ' 路径 ' into table action1; 合并deal_month deal_day为deal_time,通过“-”拼接,保存到新表 create table action as select user_id ,goods_id ,user_action ,concat(deal_month ,'-',deal_day ) as deal_time from action1; 查看新表结构 desc action; 查看数据 select * from 表名 limit 100; 导出表数据到本地文件 insert overwrite local directory ' 本地路径 ' row format delimited fields terminated by ',' select * from 表名; //路径的引号不要留空格,路径下导出的文件只能存本次导出的文件,下次导出时文件会被覆写 2. sail_info表 注意编码,scv转成txt时选择编码结构(一般UTF-8),否则会有乱码 建表 create table sail_info ( goods_id string,goods_name string,goods_property string,store_name string, store_id string,goods_url string,goods_price float,keyword string,sail_count int,good_rate int,brand string,model string,color string,time_to_market string,operate_system string) row format delimited fields terminated by ',' ; 删除表中某列为空的一行,重新存储 create table if not exists 表名 as select * from name where length(列名)>1; 3. user.info表 创建 create table if not exists default.user_info(userid string,username string,address string,gender string,birthday string) row format delimited fields terminated by ' '; 将日期转为年龄再转存另一个表 create table if not exists user_info_age as select userid,username,address,gender,round(datediff('2019-9-8 15:00:00',regexp_replace(concat(birthday,'15:00:00'),"""," "))/365) from user_info limit 50 导出 insert overwrite local directory '/home/hadoop/data' row format delimited fields terminated by ',' select * from user_info_age; 年龄区段 select userid,age, case when (age<18) then '1' when (18<=age<=24) then '2' when (25<=age<=29) then '3' else '7' end as regin from user_info_age; 去掉空行: create table if not exists name as select * from name where length(lie)>1; 年龄区段转存新表 create table if not exists user_info_regin as select userid,username,address,gender,case when (age<18) then '1' when (age between 18 and 24) then '2' when (age between 25 and 29) then '3' when (age between 30 and 34) then '4' when (age between 35 and 39) then '5' when (age between 40 and 49) then '6' else '7' end as regin from user_info_age_true; 为年龄划分类别 create table if not exists user_info_regin_alias as select userid,username,address,gender,regin,case when (regin=1) then '18岁以下' when (regin=2) then '18岁到24岁之间' when (regin=3) then '25岁到29岁之间' when(regin=4) then '30岁到34岁之间' when (regin=5) then '35岁到39岁之间' when (regin=6) then '40岁到49岁之间' else '50岁以上' end as user_age_regin_alias from user_info_regin; 删除user_info_regin_alias中的userid字段的“” create table if not exists user_info as select regexp_replace(userid,""",""),username,address,gender,regin,user_age_regin_alias from user_info_regin_alias; 连接user与comment表获得userrank字段 create table if not exists userinfo as select user_info.userid,user_info.username,user_info.address,user_info.gender,user_info.regin,user_info.user_age_regin_alias,comment_ture.userrank from user_info join comment_ture on user_info.userid = comment_ture.userid;
表结构及数据处理结果效果如下: