这篇博文不介绍基础的RNN理论知识,只是初步探索如何使用Tensorflow,之后会用笔推导RNN的公式和理论,现在时间紧迫所以先使用为主~~
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import tensorflow.examples.tutorials.mnist.input_data as input_data
from tensorflow.contrib import rnn
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
trainimgs, trainlabels, testimgs, testlabels
= mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
ntrain, ntest, dim, nclasses
= trainimgs.shape[0], testimgs.shape[0], trainimgs.shape[1], trainlabels.shape[1]
print ("MNIST loaded")
dim_input = 28 #28*1
dim_hidden = 128 #28*128
dim_output = 10 #
nsteps = 28
weight = {
"hidden":tf.Variable(tf.random_normal([dim_input,dim_hidden])),
"out" :tf.Variable(tf.random_normal([dim_hidden,dim_output]))
}
biases = {
"hidden":tf.Variable(tf.random_normal([dim_hidden])),
"out" :tf.Variable(tf.random_normal([dim_output]))
}
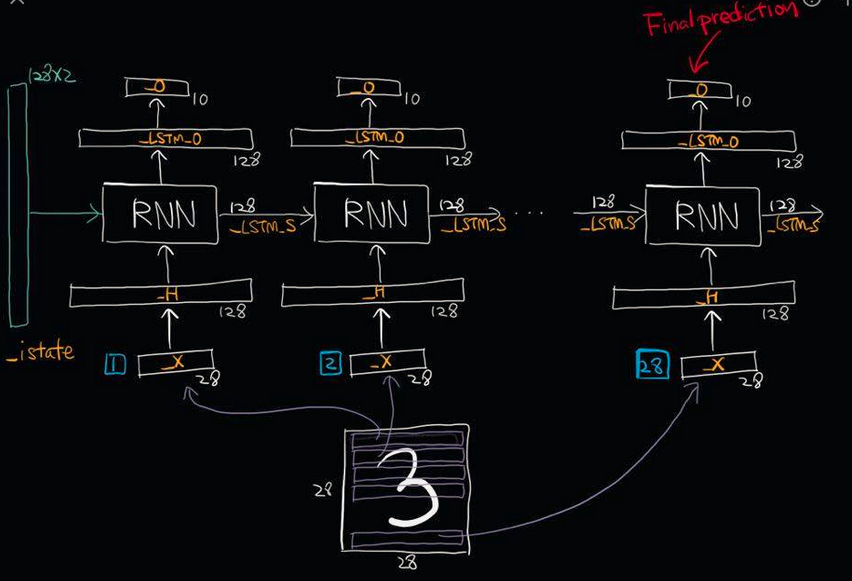
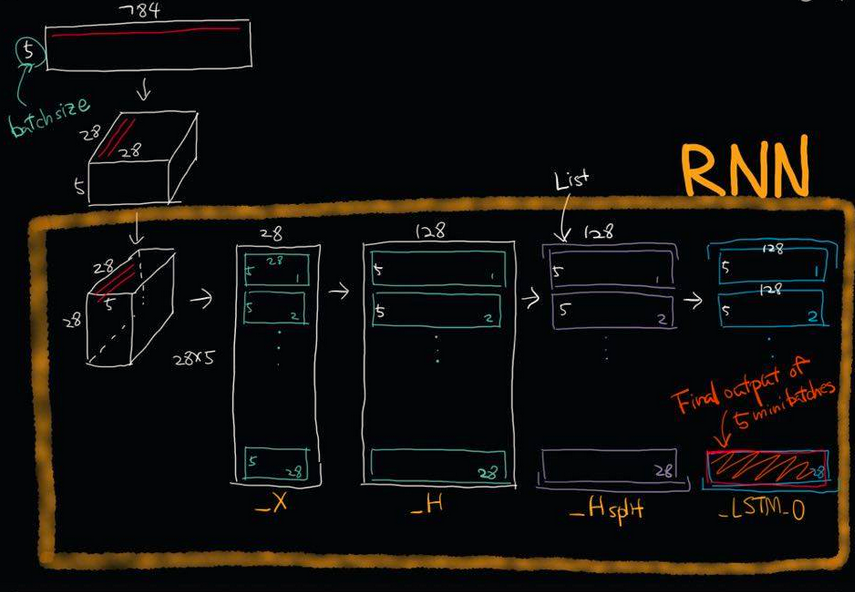
def RNN(_X,_W,_b,_nsteps,_name):
#[batchsize,nsteps*dim_input]-->>[batchsize,nsteps,dim_input]=[num,28,28]
_X = tf.reshape(_X,[-1,28,28])
#-->>[nsteps,batchsize,dim_input]==[28,num,28]
_X = tf.transpose(_X,[1,0,2])
#-->>[nsteps*batchsize,input]==[28*num,28]
_X = tf.reshape(_X,[-1,28])
#这里是共享权重,nsteps个weights全部一样的.
_H = tf.matmul(_X,_W['hidden']) + _b["hidden"]
_Hsplit = tf.split(_H,num_or_size_splits=nsteps,axis=0)
with tf.variable_scope(_name,reuse=tf.AUTO_REUSE):#重复使用参数节约空间,防止报错
#版本更新弃用
#scop.reuse_variables()
#设计一个计算单元
lstm_cell = rnn.BasicLSTMCell(128,forget_bias=1.0)
#版本更新已经弃用
#lstm_cell = rnn_cell.BasicLSTMCell(dim_hidden,forget_bias=1.0)
#利用RNN单元搭建网络,这里用的最简单的,其它以后在说
_LSTM_0,_LSTM_S = rnn.static_rnn(lstm_cell,_Hsplit,dtype=tf.float32)
#版本更新已经弃用
#_LSTM_O, _LSTM_S = tf.nn.rnn(lstm_cell, _Hsplit,dtype=tf.float32)
return tf.matmul(_LSTM_0[-1],_W["out"])+_b["out"]
#使用GPU按需增长模式
config = tf.ConfigProto(allow_soft_placement=True)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.3)
config.gpu_options.allow_growth = True
if __name__== "__main__":
learning_rate = 0.001
x = tf.placeholder(dtype=tf.float32,shape=[None,28*28],name="input_x")
y = tf.placeholder(dtype=tf.float32,shape=[None,10],name="output_y")
pred = RNN(x,weight,biases,nsteps,"basic")
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optm = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
accr = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(pred,1),tf.argmax(y,1)),dtype=tf.float32))
init = tf.global_variables_initializer()
print("RNN Already")
training_epochs = 50
batch_size = 16
display_step = 1
sess = tf.Session(config=config)
sess.run(init)
print("Start optimization")
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
#total_batch = 100
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data
feeds = {x: batch_xs, y: batch_ys}
sess.run(optm, feed_dict=feeds)
# Compute average loss
avg_cost += sess.run(cost, feed_dict=feeds) / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch: %03d/%03d cost: %.9f" % (epoch, training_epochs, avg_cost))
feeds = {x: batch_xs, y: batch_ys}
train_acc = sess.run(accr, feed_dict=feeds)
print(" Training accuracy: %.3f" % (train_acc))
feeds = {x: testimgs, y: testlabels}
test_acc = sess.run(accr, feed_dict=feeds)
print(" Test accuracy: %.3f" % (test_acc))
print("Optimization Finished.")
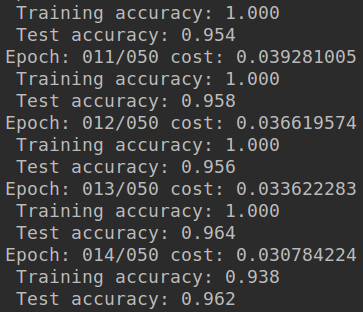
- 没有训练结束,使用的GTX1060训练了大概8分钟,如果训练结束感觉应该可以达到97%左右
- 因为是单层网络,深度不够,也没处理数据~~
- 这只是简单了解RNN工作流程,和如何用TF操作RNN
- 以后会慢慢补上~~
参考:
- 唐迪宇课程,因为版本问题会出现很多代码更新
- 其它中间忘记记录了,如有侵权请联系博主,抱歉~