在对短期数据的预测分析中,我们经常用到时间序列中的指数平滑做数据预测,然后根据不同。
下面我们来看下具体的过程
x<-data.frame(rq=seq(as.Date('2016-11-15'),as.Date('2016-11-22'),by='day'),
sr=c(300,697,511,1534,1155,1233,1509,1744))
xl<-ts(x$sr) #构建时间序列
plot.ts(xl)
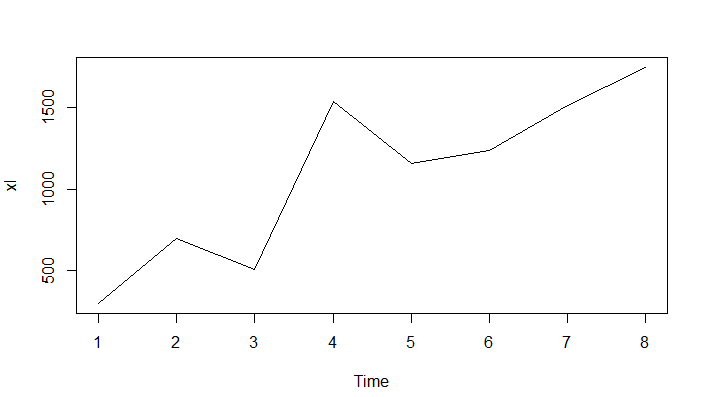
从上图的结果来看,这是一个增长趋势的时间序列。
模型选择上我们可以依据以下标准进行判断,自己要选用的时间序列算法。
简单指数平滑法——处于恒定水平和没有季节性变动的时间序列。
霍尔特指数平滑法——有增长或下降趋势的,但没有季节性因素的时间序列
霍尔特-温特指数平滑法——有增长或下降趋势,且有季节性变动趋势的时间序列
按照上面的的时间序列趋势来看,数据有增长的趋势,不存在季节性因素,这里我们要选择霍尔特指数平滑法。
接下来我们构建时间序列模型
model<-HoltWinters(xl,gamma=FALSE,l.start=300,b.start=200)
这里的参数,gamma 是用于霍尔特-温特指数平滑法,这里要用false屏蔽,同样构建简单指数平滑时也要把beta参数屏蔽,l.start 通常用的是时间序列的第一个值,b.start表示斜率,这里需要个人基于数据增长趋势给一个预估值,也可以用简单的方法,把较近的两个值进行相见得到一个预估值。
model
Holt-Winters exponential smoothing with trend and without seasonal component.
Call:
HoltWinters(x = xl, gamma = FALSE, l.start = 300, b.start = 200)
Smoothing parameters:
alpha: 0.2437346
beta : 0.01562883
gamma: FALSE
Coefficients:
[,1]
a 1717.1539
b 203.1948
从模型结果来看
alpha 和 beta 参数来看都相对较低(在0到1之间),数值较低说明较远的时间点上的数值权重较高。
plot(model)
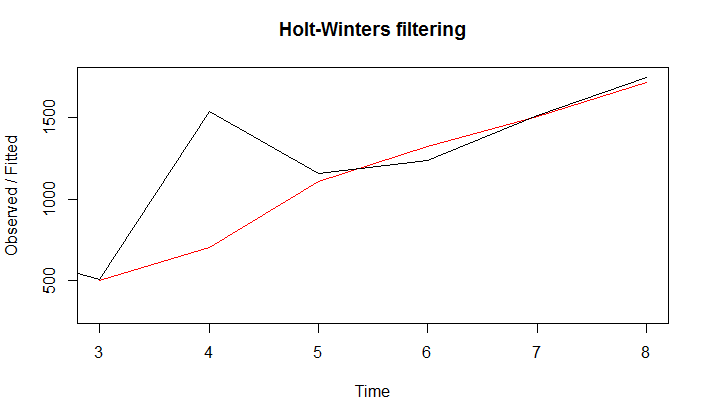
从模型的预测值和实际值来看,预测后期的数据重合度较高,整体上模型预测效果应该相对不错。
library(forecast)
premodel<-forecast.HoltWinters(model, h=7) #预测未来7天的数据走势
premodel
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
9 1920.349 1481.805 2358.892 1249.654 2591.044
10 2123.543 1671.763 2575.324 1432.605 2814.482
11 2326.738 1861.705 2791.772 1615.531 3037.946
12 2529.933 2051.626 3008.240 1798.425 3261.441
13 2733.128 2241.522 3224.733 1981.282 3484.974
14 2936.323 2431.390 3441.255 2164.095 3708.550
15 3139.517 2621.227 3657.808 2346.861 3932.174
plot.forecast(premodel)

从增长趋势来看预测结果吻合度较高。
接下来,我们要检验下模型的预测误差是否非存在自相关性,
premodel$residuals
Time Series:
Start = 1
End = 8
Frequency = 1
[1] NA NA 11.000000 831.277018 46.457606 -90.251162 4.704513 35.498288
查看模型预测误差情况,里面存着NA值,我们需要先去掉
b<-premodel$residuals[-which(is.na(premodel$residuals))]
acf(b,lag.max=7,plot=TRUE)
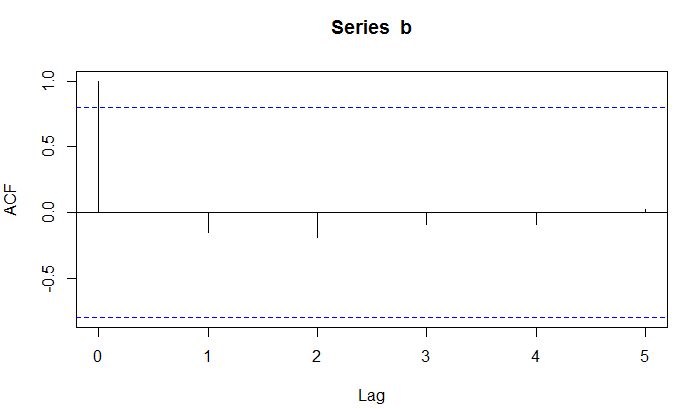
从结果来看,模型滞后5阶内都没有超出置信边界。
Box.test(premodel$residuals,lag=5, type="Ljung-Box")
Box-Ljung test
data: premodel$residuals
X-squared = 1.01, df = 5, p-value = 0.9618
检验的结果来看p值较大,可能存在自相关性。由于样本整体较小,预测误差服从零均值,方差不变的正太分布可能性较小。
整体上来看,上面的预测走势应该是相对比较接近真实情况,这里也给我们一个反思的地方,要使得模型具有足够的说服力,样本数据应该较大的情况下才能得出更准确的预测模型。