sql调优大致分为两步:1 如何定位慢查询 2 如何优化sql语句。
定位慢查询
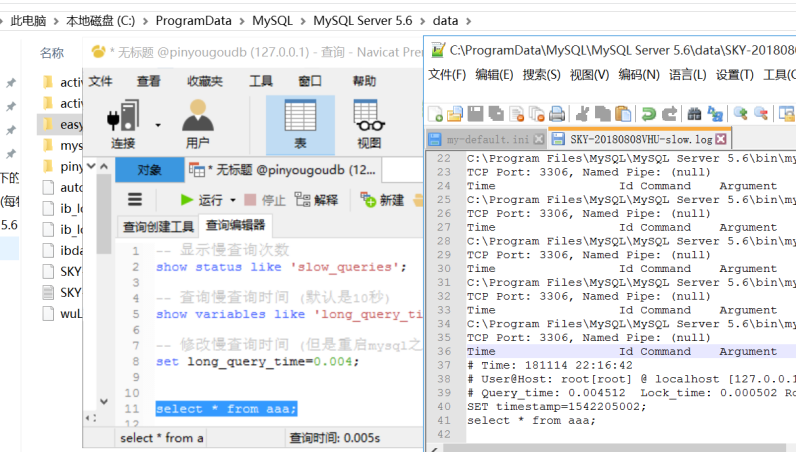
-- 显示到mysql数据库的连接数 -- show status like 'connections'; -- 显示慢查询次数 show status like 'slow_queries'; -- 查看慢查询阈值 (默认是10秒) show variables like 'long_query_time'; -- 修改慢查询时间 (但是重启mysql之后,long_query_time依然是my.ini中的值) set long_query_time=1; -- 此时再次查看mysql慢查询阈值就是刚设置的值了,一般sql执行时间超过1s,就是慢查询了。
如图:我们将慢查询时间设置为0.004s, 而select * from aaa; 执行花了0.005s,那么它就是慢查询,mysql会将慢查询语句直接写入日志文件中,我们就可以根据日志快速定位项目中的慢查询语句。
优化案例
查询只有命中索引才能高效,我们可以通过 explain 执行计划 来检查我们的sql语句是否命中了索引。
1:创建表, id为主键索引 CREATE TABLE ccc ( id int (5), name varchar(50), age int (3), PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 2:设置普通索引 create index 索引名 on 表 (列1,列名2); create index ccc_index on ccc(name); 3:查入数据 insert into ccc VALUES (1, '吴磊', 23); insert into ccc VALUES (2, '杰伦', 22); insert into ccc VALUES (3, '二狗', 24);
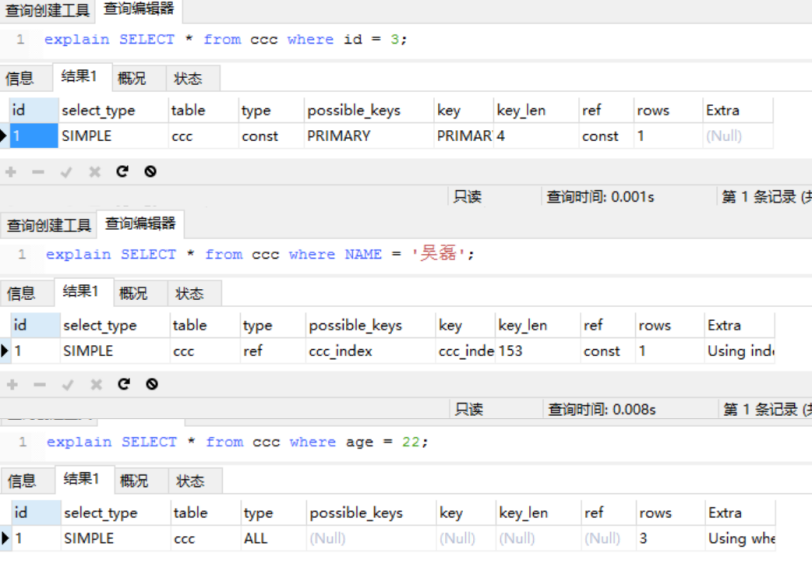
type:性能从好到差为 const、eq_ref、ref、range、indexhe , 为 ALL 则表示没有命中索引
sql调优总结:
1. like 模糊查询:不要以%开头,它会丢失索引
explain select * from ccc where name like "吴磊" 命中索引 explain select * from ccc where name like "吴磊%" 命中索引 explain select * from ccc where name like "%吴磊" 丢失索引 explain select * from ccc where name like "%吴磊%" 丢失索引
2. null判断用: is 代替 =
explain select * from ccc where name is null 命中索引 explain select * from ccc where name = null 丢失索引
3. select * from user where age >100比select * from user where age >= 101 效率要高;前者只查了一次,后者查了2次
4. group by 分组:默认分组后,还会排序,可能会降低速度,
在group by 后面增加 order by null 就可以防止排序。 select * from ccc group by age order by null
5. 关连查询代替子查询,因为子查询会将查出来的结果集在内存中创建处一张临时表。
6. 关联查询尽量大表在前小标在后,mysql是以右边的表为驱动表。 from table(大), table2(小)
7. 尽量保证where的过滤条件中,哪个条件过滤的数据多久放在语句前面
8. 尽量 用0代替null 用exits代替in 交集代替!= ..........
9. 避免使用or, 他会丢失索引。
10. 离散程度大的条件放前面:比如 where a = 12 and b = 3 ,如果b有100条数据 a只有10条,那么b放在前面。
11. 分页优化 select * from oper_log where type='BUY' and id>=(select id from oper_log where type='BUY' limit 1000000,1) limit 100