今天,我们就先聊一下spark中的DAG以及RDD的相关的内容
1.DAG:有向无环图:有方向,无闭环,代表着数据的流向,这个DAG的边界则是Action方法的执行
2.如何将DAG切分stage,stage切分的依据:有宽依赖的时候要进行切分(shuffle的时候,
也就是数据有网络的传递的时候),则一个wordCount有两个stage,
一个是reduceByKey之前的,一个事reduceByKey之后的(图1),
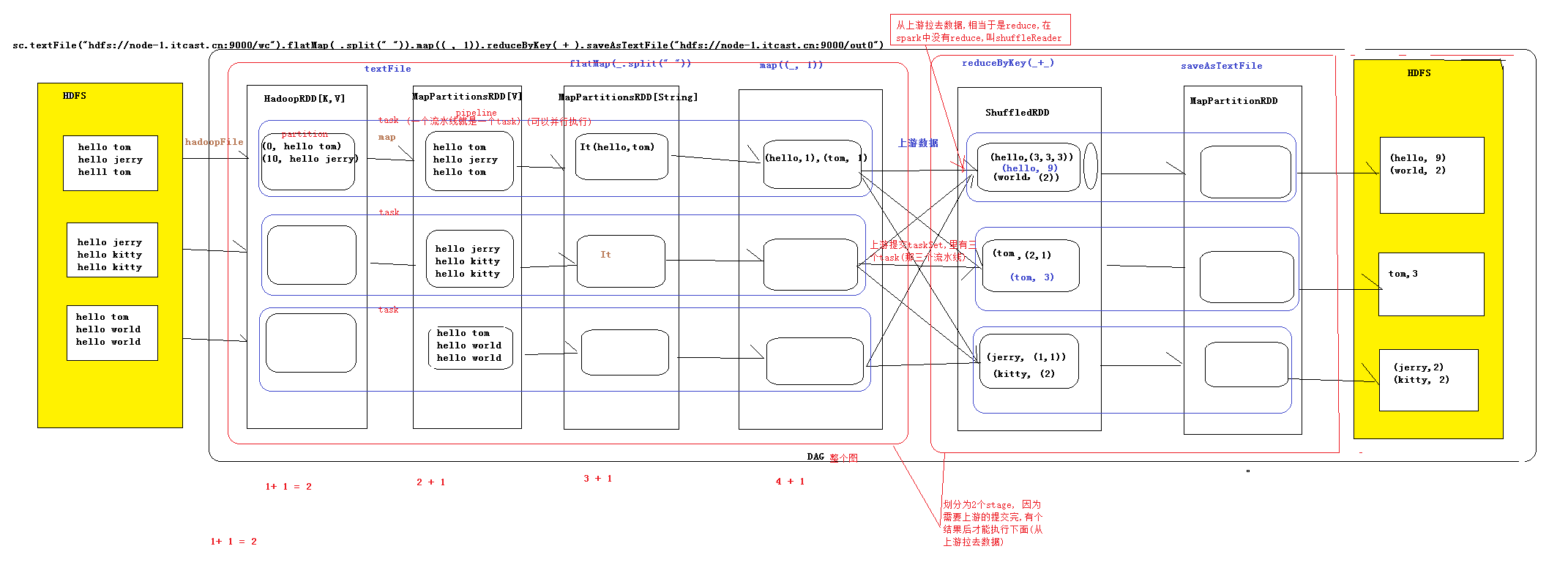
则我们可以这样的理解,当我们要进行提交上游的数据的时候,
此时我们可以认为提交的stage,但是严格意义上来讲,我们提交的是Task
sets(Task的集合),这些Task可能业务逻辑相同,就是处理的数据不同
3.流程
构建RDD形成DAG遇到Action的时候,前面的stage先提交,提交完成之后再交给
下游的数据,在遇到TaskScheduler,这个时候当我们遇到Action的方法的时候,我们
就会让Master决定让哪些Worker来执行这个调度,但是到了最后我们真正的传递的
时候,我们用的是Driver给Worker传递数据(其实是传递到Excutor里面,这个里面执行
真正的业务逻辑),Worker中的Excutor只要启动,则此后就和Master没有多大关系了
4.宽窄依赖
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)以及
宽依赖(wide dependency).

窄分区的划分依据,如果后面的一个RDD,前面的一个RDD有一个唯一对应的RDD,
则此时就是窄依赖,就相当于一次函数,y对应于一个x,而宽依赖则是类似于,前面的
一个RDD,则此时一个RDD对应多个RDD,就相当于二次函数,一个y对应多个x的值
5.DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成
DAG,根据RDD的之间的依赖关系的不同将DAG划分为不同的stage,对于窄依赖,
partition的转换处理在stage中完成计算,对于宽依赖,由于有shuffle的存在,只能在
partentRDD处理完成后,才能开始接下来的计算,因此宽依赖是划分stage的依据
一般我们认为join是宽依赖,但是对于已经分好区的join来说,我们此时可以认为这个
时候的join是窄依赖