1.静态内部类和非静态内部类的区别
如果你不需要内部类对象与其外围类对象之间有联系,那你可以将内部类声明为static。这通常称为嵌套类(nested class)。Static Nested Class是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化。而通常的内部类需要在外部类实例化后才能实例化。想要理解static应用于内部类时的含义,你就必须记住,普通的内部类对象隐含地保存了一个引用,指向创建它的外围类对象。然而,当内部类是static的时,就不是这样了。嵌套类意味着:
1. 嵌套类的对象,并不需要其外围类的对象。
2. 不能从嵌套类的对象中访问非静态的外围类对象。
在静态嵌套类内部, 不能访问外部类的非静态成员, 这是由Java语法中"静态方法不能直接访问非静态成员"所限定,生成一个静态内部类不需要外部类成员:这是静态内部类和成员内部类的区别。静态内部类的对象可以直接生成:Outer.Inner in = new Outer.Inner();而不需要通过生成外部类对象来生成。
2.内存溢出
指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
3.匿名内部类的构造方法以及局部变量final
匿名内部类由于没有名字,所以它的创建方式有点儿奇怪。创建格式如下:
[java] view plain copy
- new 父类构造器(参数列表)|实现接口()
- {
- //匿名内部类的类体部分
- }
在这里我们看到使用匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有class关键字,这是因为匿名内部类是直接使用new来生成一个对象的引用。当然这个引用是隐式的。
在使用匿名内部类的过程中,我们需要注意如下几点:
1、使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
2、匿名内部类中是不能定义构造函数的。
3、匿名内部类中不能存在任何的静态成员变量和静态方法。
4、匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
5、匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
,内部类并不是直接调用方法传递的参数,而是利用自身的构造器对传入的参数进行备份,自己内部方法调用的实际上时自己的属性而不是外部方法传递进来的参数。
直到这里还没有解释为什么是final?在内部类中的属性和外部方法的参数两者从外表上看是同一个东西,但实际上却不是,所以他们两者是可以任意变化的,也就是说在内部类中我对属性的改变并不会影响到外部的形参,而然这从程序员的角度来看这是不可行的,毕竟站在程序的角度来看这两个根本就是同一个,如果内部类该变了,而外部方法的形参却没有改变这是难以理解和不可接受的,所以为了保持参数的一致性,就规定使用final来避免形参的不改变。
简单理解就是,拷贝引用,为了避免引用值发生改变,例如被外部类的方法修改等,而导致内部类得到的值不一致,于是用final来让该引用不可改变。
故如果定义了一个匿名内部类,并且希望它使用一个其外部定义的参数,那么编译器会要求该参数引用是final的
4.数据库设计三大范式
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
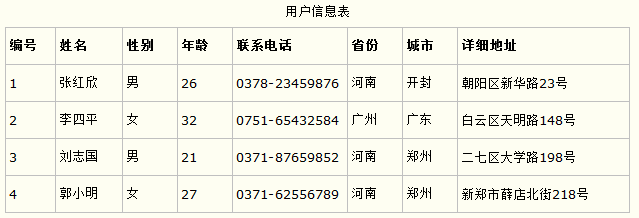
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
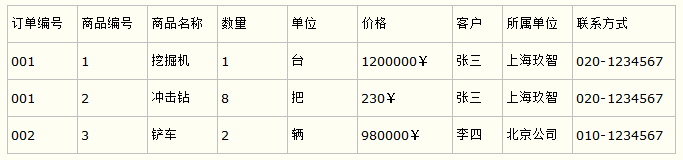
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
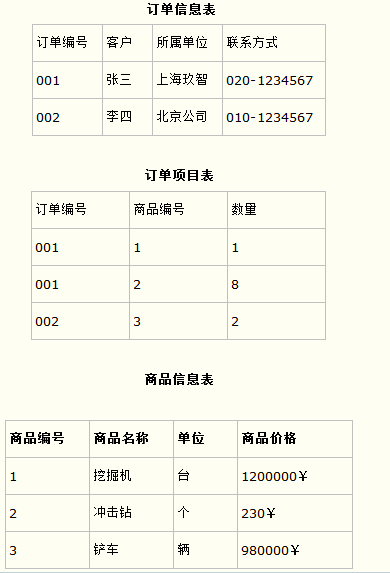
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
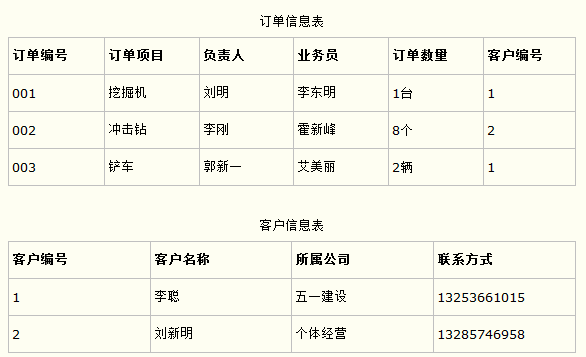
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
简单来说:
第一范式是不可拆分
第二是完全依赖
第三消除传递依赖