首先是Okhttp的使用:
//缓存文件夹 File cacheFile = new File(getExternalCacheDir().toString(), "cache"); //缓存大小为10M int cacheSize = 10 * 1024 * 1024; //创建缓存对象 Cache cache = new Cache(cacheFile, cacheSize); OkHttpClient client = new OkHttpClient .Builder() //.addInterceptor(new LoggingInterceptor())//日志拦截器 .cache(cache) .build(); Request request = new Request.Builder() .url("http://www.baidu.com") .build(); client.newCall(request).enqueue(new Callback() { @Override public void onFailure(Call call, IOException e) { Log.d("OkHttp", "Call Failed:" + e.getMessage()); } @Override public void onResponse(Call call, Response response) throws IOException { Log.d("OkHttp", "Call succeeded:" + response.message()); } });
先来看一下Request包含的有通讯的信息
url:发起通讯的地址
method:通讯方式
public final class Request { final HttpUrl url; final String method; final Headers headers; final RequestBody body; final Object tag; private volatile CacheControl cacheControl; // Lazily initialized. Request(Builder builder) { this.url = builder.url; this.method = builder.method; this.headers = builder.headers.build(); this.body = builder.body; this.tag = builder.tag != null ? builder.tag : this; }
总流程图:
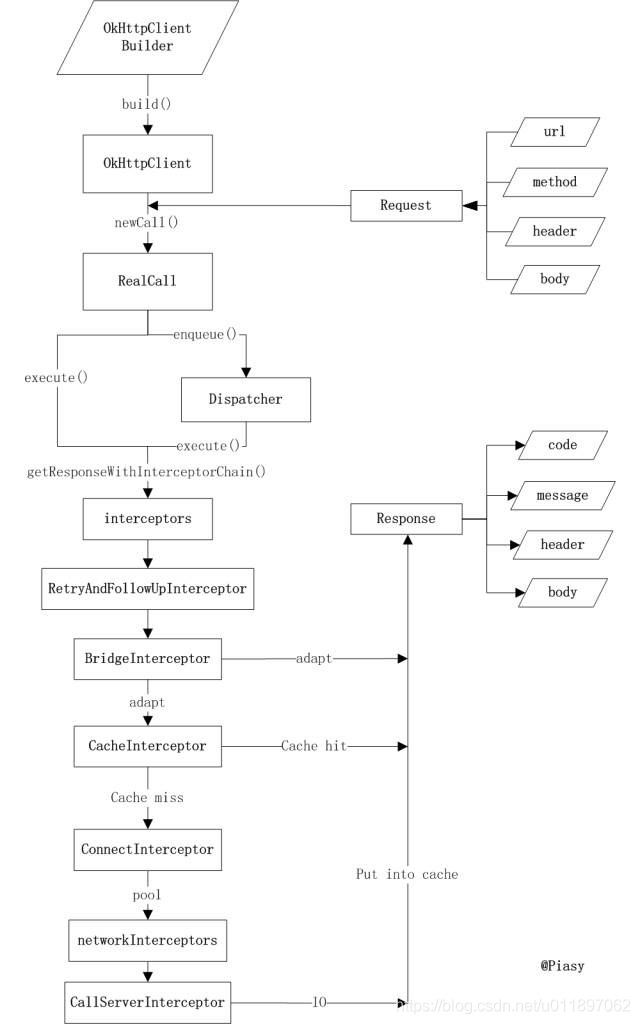
Part1:主体流程
下面我们先来摸清这个框架的主干部分,刚开始看的时候,先沿一条线下来,细枝末节先不要太关心:
我们来看看newCall:
client.newCall(request).enqueue(new Callback() { @Override public Call newCall(Request request) { return new RealCall(this, request, false /* for web socket */); } final class RealCall implements Call { RealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) { final EventListener.Factory eventListenerFactory = client.eventListenerFactory(); this.client = client; this.originalRequest = originalRequest; this.forWebSocket = forWebSocket; this.retryAndFollowUpInterceptor = new RetryAndFollowUpInterceptor(client, forWebSocket); // TODO(jwilson): this is unsafe publication and not threadsafe. this.eventListener = eventListenerFactory.create(this); }
可以看出:Call是一个接口,而RealCall是Call的一个具体实现。client.newCall(request)里面是生成一个RealCall的实例
Recall同时持有client和request,
所以:
client.newCall(request).enqueue(new Callback() {
实际上执行到的是RealCall的enqueue:
@Override public void enqueue(Callback responseCallback) { synchronized (this) { if (executed) throw new IllegalStateException("Already Executed"); executed = true; } captureCallStackTrace(); client.dispatcher().enqueue(new AsyncCall(responseCallback)); }
这里的responseCallback就是我们最外层的回调接口,暂时先不管这个。
重点看这行代码:
client.dispatcher().enqueue(new AsyncCall(responseCallback));
dispatcher是client持有的一个调度器,我们找到Dispatcher这个类里面的enqueue方法:
synchronized void enqueue(AsyncCall call) { if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) { runningAsyncCalls.add(call); executorService().execute(call); } else { readyAsyncCalls.add(call); } }
可以看出,runningAsyncCalls,这里是线程池里面的概念,先看executorService().execute(call)
来看一下call:
final class AsyncCall extends NamedRunnable { public abstract class NamedRunnable implements Runnable {
可以看出,AsyncCall是一个Runnable,所以executorService().execute(call)执行的时候,实际上执行的是AsnycCall里面的execute()方法:
@Override protected void execute() { boolean signalledCallback = false; try { Response response = getResponseWithInterceptorChain(); if (retryAndFollowUpInterceptor.isCanceled()) { signalledCallback = true; responseCallback.onFailure(RealCall.this, new IOException("Canceled")); } else { signalledCallback = true; responseCallback.onResponse(RealCall.this, response); } } catch (IOException e) { if (signalledCallback) { // Do not signal the callback twice! Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e); } else { responseCallback.onFailure(RealCall.this, e); } } finally { client.dispatcher().finished(this); } }
Response response = getResponseWithInterceptorChain()通过后续的层层调用,得到返回值,这句代码后续进行详细解析。
然后调用responseCallback.onResponse(RealCall.this, response);通过callback返回最终结果给上层。
以上部分总结:
client.newCall(request).enqueue(new Callback() {
执行流程: RealCall.enqueue(Callback)->client.dispatcher.enqueue(Callback)->通过Dispatcher的线程池执行AsyncCall.excute,Response response = getResponseWithInterceptorChain();
最后通过responseCallback.onResponse返回最终的结果。
Part2:
接着往下分析:
找到关键的语句:
Response result = getResponseWithInterceptorChain();
这句是这个框架比较核心的思想:拦截器,通过一个个的拦截器,通过递归串联起来:
Response getResponseWithInterceptorChain() throws IOException { // Build a full stack of interceptors. List<Interceptor> interceptors = new ArrayList<>(); interceptors.addAll(client.interceptors()); interceptors.add(retryAndFollowUpInterceptor); interceptors.add(new BridgeInterceptor(client.cookieJar())); interceptors.add(new CacheInterceptor(client.internalCache())); interceptors.add(new ConnectInterceptor(client)); if (!forWebSocket) { interceptors.addAll(client.networkInterceptors()); } interceptors.add(new CallServerInterceptor(forWebSocket)); Interceptor.Chain chain = new RealInterceptorChain( interceptors, null, null, null, 0, originalRequest); return chain.proceed(originalRequest); }
首先是interceptors.addAll(client.interceptors()),这里面的intterceptors是哪里来的呢,从代码可以看出是由client来的,其实就是我们初始化client的时候,由用户
添加的new OkHttpClient.Builder().addInterceptor(new LoggingInterceptor()).build();这里面的LoggingInterceptor就是我们用户自己定义的interceptor,从上面的代码
我们可以看到interceptors是一个list,说明client的addInterceptor可以添加多个。
我们看client的interceptors,是分为两种类型的, addInterceptor()和addNetworkInterceptor() ,通过 addInterceptor() 方法添加的拦截器是放在最前面的。通过 addNetworkInterceptor() 方法添加的网络拦截器,则是在非 WebSocket 请求时,添加在 ConnectInterceptor 和 CallServerInterceptor 之间的。这两个的区别,可以看
这里:https://blog.csdn.net/qq_38219041/article/details/72935142?utm_source=blogxgwz1
addInterceptor() 添加应用拦截器
● 不需要担心中间过程的响应,如重定向和重试.
● 总是只调用一次,即使HTTP响应是从缓存中获取.
● 观察应用程序的初衷. 不关心OkHttp注入的头信息如: If-None-Match.
● 允许短路而不调用 Chain.proceed(),即中止调用.
● 允许重试,使 Chain.proceed()调用多次.
addNetworkInterceptor() 添加网络拦截器
● 能够操作中间过程的响应,如重定向和重试.
● 当网络短路而返回缓存响应时不被调用.
● 只观察在网络上传输的数据.
● 携带请求来访问连接.
接下来的重点是这句话:
Interceptor.Chain chain = new RealInterceptorChain( interceptors, null, null, null, 0, originalRequest); return chain.proceed(originalRequest);
interceptors的循环调用就在这里面了,那我们看一下这里面是如何实现的:
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec, RealConnection connection) throws IOException { if (index >= interceptors.size()) throw new AssertionError(); calls++; // If we already have a stream, confirm that the incoming request will use it. if (this.httpCodec != null && !this.connection.supportsUrl(request.url())) { throw new IllegalStateException("network interceptor " + interceptors.get(index - 1) + " must retain the same host and port"); } // If we already have a stream, confirm that this is the only call to chain.proceed(). if (this.httpCodec != null && calls > 1) { throw new IllegalStateException("network interceptor " + interceptors.get(index - 1) + " must call proceed() exactly once"); } // Call the next interceptor in the chain. RealInterceptorChain next = new RealInterceptorChain( interceptors, streamAllocation, httpCodec, connection, index + 1, request); Interceptor interceptor = interceptors.get(index); Response response = interceptor.intercept(next); // Confirm that the next interceptor made its required call to chain.proceed(). if (httpCodec != null && index + 1 < interceptors.size() && next.calls != 1) { throw new IllegalStateException("network interceptor " + interceptor + " must call proceed() exactly once"); } // Confirm that the intercepted response isn't null. if (response == null) { throw new NullPointerException("interceptor " + interceptor + " returned null"); } return response; }
可以看到,RealInterceptorChain的参数index第一次传进来的时候为0,来看porceed这个方法里面,重点是下面这句话:
// Call the next interceptor in the chain. RealInterceptorChain next = new RealInterceptorChain( interceptors, streamAllocation, httpCodec, connection, index + 1, request); Interceptor interceptor = interceptors.get(index); Response response = interceptor.intercept(next);
这里先new一个RealInterceptorChain,index为在原来的基础上+1,然后从前面的interceptors这个list里面,根据index取出相对应的一个interceptor,然后这个RealInterceptorChain作为一个参数传进interceptor.intercept
这时候我们就要回过头去看一下,说了这么久的interceptor到底是什么:
interceptors.add(new BridgeInterceptor(client.cookieJar())); public final class BridgeInterceptor implements Interceptor { public interface Interceptor { Response intercept(Chain chain) throws IOException; interface Chain { Request request(); Response proceed(Request request) throws IOException; Connection connection(); } }
interceptort定义一个接口,各个具体的拦截器实现这个接口,我们用户自己定义的拦截器也都是实现这个接口,
前面提到的:
Response response = interceptor.intercept(next);
其实就是每个具体拦截器的方法intercept:
@Override public Response intercept(Chain chain) throws IOException { Request userRequest = chain.request(); Request.Builder requestBuilder = userRequest.newBuilder(); RequestBody body = userRequest.body(); if (body != null) { MediaType contentType = body.contentType(); if (contentType != null) { requestBuilder.header("Content-Type", contentType.toString()); } long contentLength = body.contentLength(); if (contentLength != -1) { requestBuilder.header("Content-Length", Long.toString(contentLength)); requestBuilder.removeHeader("Transfer-Encoding"); } else { requestBuilder.header("Transfer-Encoding", "chunked"); requestBuilder.removeHeader("Content-Length"); } } if (userRequest.header("Host") == null) { requestBuilder.header("Host", hostHeader(userRequest.url(), false)); } if (userRequest.header("Connection") == null) { requestBuilder.header("Connection", "Keep-Alive"); } // If we add an "Accept-Encoding: gzip" header field we're responsible for also decompressing // the transfer stream. boolean transparentGzip = false; if (userRequest.header("Accept-Encoding") == null && userRequest.header("Range") == null) { transparentGzip = true; requestBuilder.header("Accept-Encoding", "gzip"); } List<Cookie> cookies = cookieJar.loadForRequest(userRequest.url()); if (!cookies.isEmpty()) { requestBuilder.header("Cookie", cookieHeader(cookies)); } if (userRequest.header("User-Agent") == null) { requestBuilder.header("User-Agent", Version.userAgent()); } Response networkResponse = chain.proceed(requestBuilder.build()); HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers()); Response.Builder responseBuilder = networkResponse.newBuilder() .request(userRequest); if (transparentGzip && "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding")) && HttpHeaders.hasBody(networkResponse)) { GzipSource responseBody = new GzipSource(networkResponse.body().source()); Headers strippedHeaders = networkResponse.headers().newBuilder() .removeAll("Content-Encoding") .removeAll("Content-Length") .build(); responseBuilder.headers(strippedHeaders); responseBuilder.body(new RealResponseBody(strippedHeaders, Okio.buffer(responseBody))); } return responseBuilder.build(); }
以上代码我们先追踪是如何实现循环调用interceptor,主要是以下这一句:
Response networkResponse = chain.proceed(requestBuilder.build());
看到这里,又调用了chain的proceed,而这个chain就是RealInterceptorChain,又回到了chain的proceed里面:
// Call the next interceptor in the chain. RealInterceptorChain next = new RealInterceptorChain( interceptors, streamAllocation, httpCodec, connection, index + 1, request); Interceptor interceptor = interceptors.get(index); Response response = interceptor.intercept(next);
通过index再次加1,调用下一个interceptor的intercept;所以拦截器list interceptors并不是通过for循环来获得每一个的拦截器,而是通过前面的index每次+1,然后
通过chain来串连起来。
由上可知,每个拦截器的重点位置就是看里面的intercept方法如何执行的,这里面都包括该拦截器的本身的业务处理以及调用下一个拦截器。
流程图:(责任链模式)
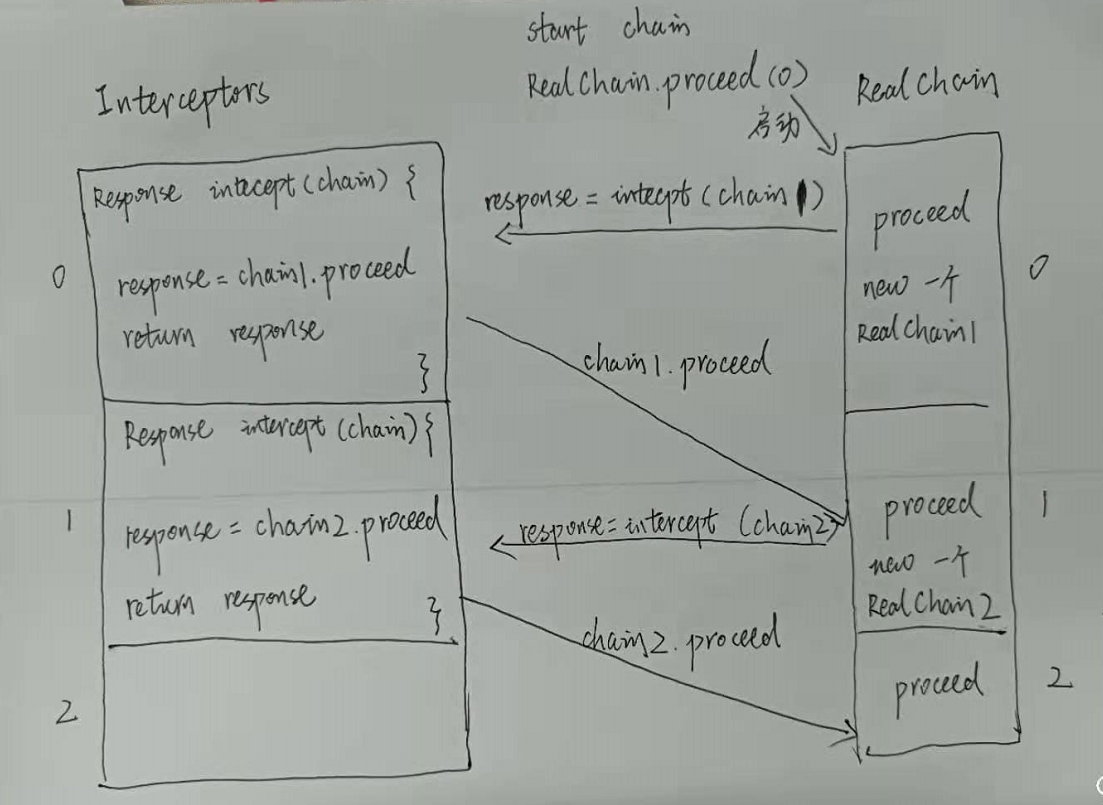
Part3:拦截器
BridgeInterceptor:转换应用层request数据为真正的网络请求数据:
先看一下BridgeInterceptor,拦截器我们都是从intercept方法入手:
@Override public Response intercept(Chain chain) throws IOException { Request userRequest = chain.request(); Request.Builder requestBuilder = userRequest.newBuilder(); RequestBody body = userRequest.body(); if (body != null) { MediaType contentType = body.contentType(); if (contentType != null) { requestBuilder.header("Content-Type", contentType.toString()); } long contentLength = body.contentLength(); if (contentLength != -1) { requestBuilder.header("Content-Length", Long.toString(contentLength)); requestBuilder.removeHeader("Transfer-Encoding"); } else { requestBuilder.header("Transfer-Encoding", "chunked"); requestBuilder.removeHeader("Content-Length"); } } if (userRequest.header("Host") == null) { requestBuilder.header("Host", hostHeader(userRequest.url(), false)); } if (userRequest.header("Connection") == null) { requestBuilder.header("Connection", "Keep-Alive"); } // If we add an "Accept-Encoding: gzip" header field we're responsible for also decompressing // the transfer stream. boolean transparentGzip = false; if (userRequest.header("Accept-Encoding") == null && userRequest.header("Range") == null) { transparentGzip = true; requestBuilder.header("Accept-Encoding", "gzip"); } List<Cookie> cookies = cookieJar.loadForRequest(userRequest.url()); if (!cookies.isEmpty()) { requestBuilder.header("Cookie", cookieHeader(cookies)); } if (userRequest.header("User-Agent") == null) { requestBuilder.header("User-Agent", Version.userAgent()); } Response networkResponse = chain.proceed(requestBuilder.build()); HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers()); Response.Builder responseBuilder = networkResponse.newBuilder() .request(userRequest); if (transparentGzip && "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding")) && HttpHeaders.hasBody(networkResponse)) { GzipSource responseBody = new GzipSource(networkResponse.body().source()); Headers strippedHeaders = networkResponse.headers().newBuilder() .removeAll("Content-Encoding") .removeAll("Content-Length") .build(); responseBuilder.headers(strippedHeaders); responseBuilder.body(new RealResponseBody(strippedHeaders, Okio.buffer(responseBody))); } return responseBuilder.build(); }
以上代码中,前半部分,chain.proceed(requestBuilder.build())前面,其实就是将最外层的代码,即用户层面定义的request:
Request request = new Request.Builder() .........
里面的各个参数转为真正的网络请求参数,包括Host、Connect、Accept-Encoding、User-Agent、Cookie等http的头部分头信息,通过:
Response networkResponse = chain.proceed(requestBuilder.build());
将这些信息传入到下一个拦截器去执行,请求阶段这个拦截器的作用已经结束,接下来就是调用:
Response.Builder responseBuilder = networkResponse.newBuilder()
.request(userRequest);
来等待下级拦截器的返回结果。所以拦截器的作用就是,我尽管完成我的那一部分工作,把我得到的请求交给下一个拦截器,中间的过程不用管,我就等待下一个拦截器返回结果,然后再将结果同样返回上一个拦截器。
return responseBuilder.build();
CacheInterceptor:缓存拦截器,从网络还是缓存获取数据:
接下来看一下CacheInterceptor:
@Override public Response intercept(Chain chain) throws IOException { Response cacheCandidate = cache != null ? cache.get(chain.request()) : null; long now = System.currentTimeMillis(); CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get(); Request networkRequest = strategy.networkRequest; Response cacheResponse = strategy.cacheResponse; if (cache != null) { cache.trackResponse(strategy); } if (cacheCandidate != null && cacheResponse == null) { closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it. } // If we're forbidden from using the network and the cache is insufficient, fail. if (networkRequest == null && cacheResponse == null) { return new Response.Builder() .request(chain.request()) .protocol(Protocol.HTTP_1_1) .code(504) .message("Unsatisfiable Request (only-if-cached)") .body(Util.EMPTY_RESPONSE) .sentRequestAtMillis(-1L) .receivedResponseAtMillis(System.currentTimeMillis()) .build(); } // If we don't need the network, we're done. if (networkRequest == null) { return cacheResponse.newBuilder() .cacheResponse(stripBody(cacheResponse)) .build(); } Response networkResponse = null; try { networkResponse = chain.proceed(networkRequest); } finally { // If we're crashing on I/O or otherwise, don't leak the cache body. if (networkResponse == null && cacheCandidate != null) { closeQuietly(cacheCandidate.body()); } } // If we have a cache response too, then we're doing a conditional get. if (cacheResponse != null) { if (networkResponse.code() == HTTP_NOT_MODIFIED) { Response response = cacheResponse.newBuilder() .headers(combine(cacheResponse.headers(), networkResponse.headers())) .sentRequestAtMillis(networkResponse.sentRequestAtMillis()) .receivedResponseAtMillis(networkResponse.receivedResponseAtMillis()) .cacheResponse(stripBody(cacheResponse)) .networkResponse(stripBody(networkResponse)) .build(); networkResponse.body().close(); // Update the cache after combining headers but before stripping the // Content-Encoding header (as performed by initContentStream()). cache.trackConditionalCacheHit(); cache.update(cacheResponse, response); return response; } else { closeQuietly(cacheResponse.body()); } } Response response = networkResponse.newBuilder() .cacheResponse(stripBody(cacheResponse)) .networkResponse(stripBody(networkResponse)) .build(); if (cache != null) { if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) { // Offer this request to the cache. CacheRequest cacheRequest = cache.put(response); return cacheWritingResponse(cacheRequest, response); } if (HttpMethod.invalidatesCache(networkRequest.method())) { try { cache.remove(networkRequest); } catch (IOException ignored) { // The cache cannot be written. } } } return response; }
首先是这一句:
Response cacheCandidate = cache != null ? cache.get(chain.request()) : null;
判断本地是否存在缓存,如果存在,直接用,如果不存在,则值为空继续往下,那这个cache又从哪里来呢,其实也是应用层定义的:
//缓存文件夹 File cacheFile = new File(getExternalCacheDir().toString(), "cache"); //缓存大小为10M int cacheSize = 10 * 1024 * 1024;
Cache cache = new Cache(cacheFile, cacheSize); OkHttpClient client = new OkHttpClient .Builder() //.addInterceptor(new LoggingInterceptor())//日志拦截器 .cache(cache)
这里定义了一个file存储cache,定义了名字、存储路径以及最大缓存容量,那是在哪个地方设置值进去呢:
// If we have a cache response too, then we're doing a conditional get.
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
我们先来看HTTP_NOT_MODIFIED看是什么意思:
/** * HTTP Status-Code 304: Not Modified. */ public static final int HTTP_NOT_MODIFIED = 304;
返回这个意思就是,当客户端再次请求数据的时候,这个时间到上次请求的时间段内,服务器的资源数据没有更新,所以对于客户端来说,没必要再次去服务器获取具体数据,直接从本地获取上一次的数据,然后return response。
如果说是网络资源已修改,或者是第一次请求,则使用下一层的网络请求返回response,然后将该response缓存在cache里面供下次的请求使用。