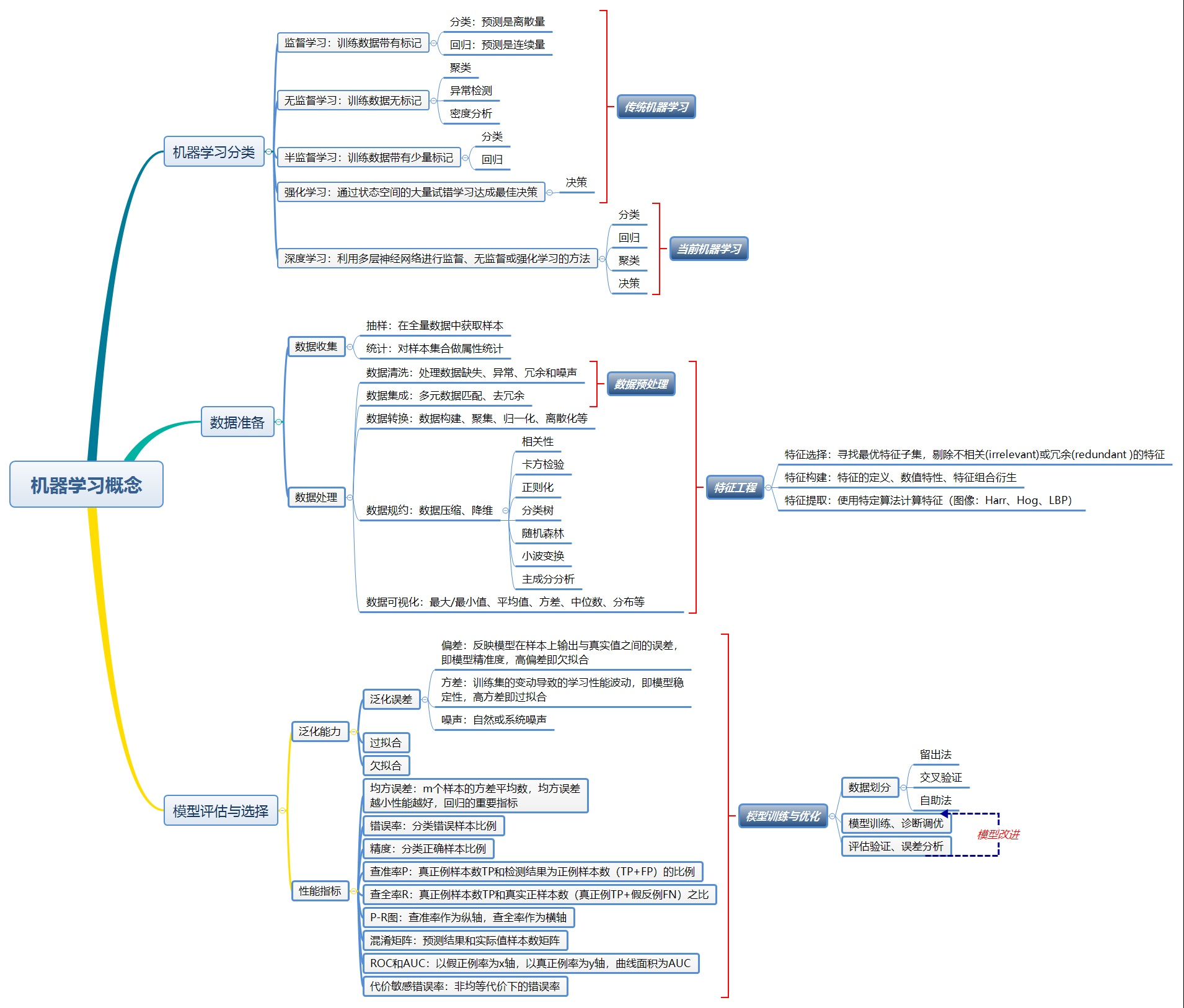
一、机器学习方法分类
监督学习:训练样本带标记(分类、回归)
无监督学习:训练样本无标记(聚类、异常检测)
半监督学习:训练样本带少量标记
强化学习:通过状态空间大量试错学习得最佳决策(决策)
深度学习:以上ML方法和深度神经网络的结合(分类、聚类、决策)
二、机器学习流程
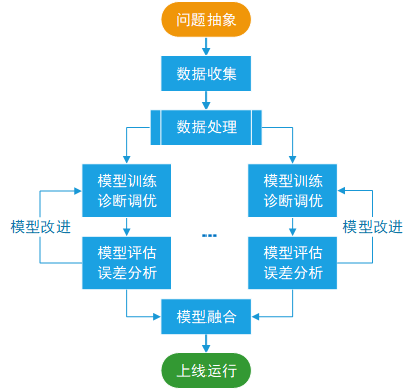
1. 实际问题抽象为数学问题
理解实际问题是机器学习的第一步,特征工程和模型训练都是非常费时的,深入理解问题,能避免走很多弯路。理解问题,包括明确可以获得的数据,机器学习的目标,是分类、回归还是聚类。如果都不是,将它们转变为机器学习问题。
2. 获取数据
获取数据包括获取原始数据以及从原始数据中从原始数据中提取数据。“ 数据决定机器学习结果的上限,而算法只是尽可能的逼近这个上限”,对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。不仅如此还要对评估数据的量级,样本数量、特征数量,估算训练模型对内存的消耗。如果数据量太大可以考虑减少训练样本、降维或者使用分布式机器学习系统。
3. 特征工程
特征工程包括从原始数据中特征构建、特征提取、特征选择,非常重要,特征工程做的好能发挥原始数据的最大效力,往往能够使得算法的效果和性能得到显著的提升,有时能使简单的模型的效果比复杂的模型效果好。数据挖掘的60%-80%时间花在特征工程上面,是机器学习非常基础而又必备的步骤。数据预处理、筛选显著特征、摒弃非显著特征等等都非常重要。
4. 模型训练、诊断调优
此过程根据对算法的理解调节参数,使模型达到最优。当然,能自己实现算法的是最牛的。模型诊断中至关重要的是判断过拟合、欠拟合,常见的方法是绘制学习曲线,交叉验证。通过增加训练的数据量、降低模型复杂度来降低过拟合的风险,提高特征的数量和质量、增加模型复杂来防止欠拟合。诊断后的模型需要进行进一步调优,调优后的新模型需要重新诊断,这是一个反复迭代不断逼近的过程,需要不断的尝试,进而达到最优的状态。
5. 模型验证、误差分析
模型验证和误差分析也是机器学习中非常重要的一步,通过测试数据,验证模型的有效性,观察误差样本,分析误差产生的原因,往往能使得我们找到提升算法性能的突破点。误差分析主要是分析出误差来源与数据、特征、算法关系。
6 . 模型融合
成熟的机器算法也就那么些,提升算法的准确度主要方法是模型的前端(特征工程、清洗、预处理、采样)和后端的模型融合。这篇博客中提到了模型融合的方法,主要包括统一融合,线性融合和堆融合。
7. 上线运行
这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。 不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性等。
FQA:为什么流程中有多个学习器并行的学习?
答:并不是说单个学习器是不行的,而是在精确度要求极高的场合,模型融合是提高准确度的重要方式,此外多源样本,可能也难以使用一个学习器训练模型;
reference:
https://www.cnblogs.com/wxquare/p/5484690.html
https://blog.csdn.net/huangfei711/article/details/79850989
三、模型评估与选择
1、泛化能力(模型对未知数据的预测能力)
- 泛化误差:偏差、方差、噪声之和;
- 过拟合:模型在训练样本上表现良好,但在测试样本上不能很好的预测;
- 欠拟合:模型在训练样本和测试样本上都不能很好的预测;
2、性能度量指标
- 均方误差,对给定样本集 D={(x1,y1), (x2,y2), (x3,y3), …, (xm,ym)}, 均方误差定义如下:

- 错误率,分类错误样本占样本总数的比例,定义:
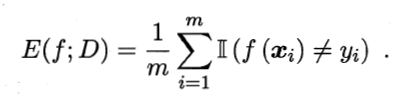
- 精度,分类正确样本占样本总数的比例
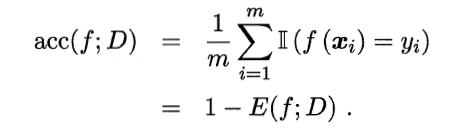
- 查准率/精确率(P),真正例样本数(TP)和所有预测结果为正例的样本数(真正例 TP+假正例 FP)之比,公式:
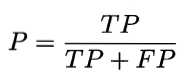
- 查全率/召回率(R),真正例样本数(TP)和所有预测结果为正例的样本数(真正例 TP+真反例 FP)之比,公式:
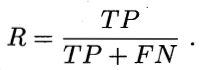
- P-R图,对于不同划分的样本,以查准率为纵轴,查全率为横轴作图,就得到P-R曲线,显示曲线的图即P-R图,示意:

说明:
1、将查准率和查全率相等的点成为平衡点(BEP),平衡点大的性能较好;
2、在没有交叉情况下,被“包住”的曲线对应的学习器性能弱于其外部曲线学习器;
平衡点(Break Event Point)的定义还是过于简化,更常用的是F1度量:
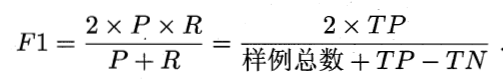
查准率和查全率是连个矛盾的指标,F1综合考虑了P和R的结果,当F1较高时则说明实验方法比较理想,又时候我们对查准率和查全率有不同的偏好,例如推荐系统希望尽可能少的打扰用户,推荐的内容使用户感兴趣的,此时我们更关注查准率,在逃犯行检索中,更希望尽可能少的漏掉逃犯,此时查全率更重要,F1的一边定义Fβ
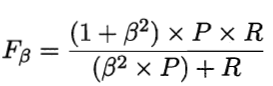
0 < β < 1查准率哟更发影响,β > 1 查全率有更大影响;
- 混淆矩阵,混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目。在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。
如有150个样本数据,这些数据分成3类,每类50个。分类结束后得到的混淆矩阵为:
预测
类1
类2
类3
实际
类1
43
5
2
类2
2
45
3
类3
0
1
49
每一行之和为50,表示50个样本,第一行说明类1的50个样本有43个分类正确,5个错分为类2,2个错分为类3;混淆矩阵可以很直观的发现问题在哪里;

- ROC和AUC,ROC(受试者工作特性曲线)以假正例率为x轴,真正例率为y轴,AUC是ROC曲线下的面积,面积越大分类效果越好。
举例,计算结果:
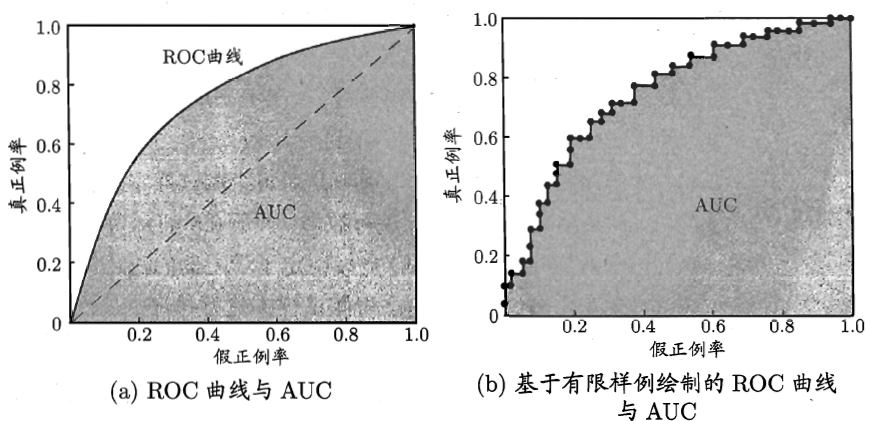
对角线虚线对应随机猜测某型
- 偏差,反应的是模型在样本上的输出和真实值之间的误差,即模型本身的精准度,高偏差即为欠拟合。
- 方差,反应的是同样大小的训练集的变动导致的学习型嫩干的波动,即刻画了数据扰动所造成的影响,即模型稳定性。高方差即为过拟合。

偏差和方差两者是有冲突的,称之为变差方差窘境(bias-variance dilemma),很难同时做到偏差和方差都很低,只能从偏差、方差和模型复杂度中找到一个平衡点。