分区策略
1.分区原因
1.1 方便在集群中扩展,每个partition可以通过调整以适应它所在的机器,而一个topic又可以有多个partition组成,因此整个集群就可以适应任意大小的数据了;
1.2 可以提高并发,因为可以以partition为单位读写;
2.分区原则
将producer发送的数据封装成一个producerRecord对象;

2.1 指明partition的情况下,直接将指明的值直接作为partition值;
2.2 没有指明partition值,但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
2.3 即没有partition值又没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常用的round-robin算法
数据可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack,如果producer收到ack,就会进行下一轮的发送,否则重新发送数据;
1.何时发送ack?
确保有follower与leader同步完成,leader再发送ack,这样才能确保leader挂掉之后,能在follower中选举出新的leader;

2.副本同步策略
方案一:半数以上的follower同步完成,即可发送ack;
优点:延迟低;
缺点:选择新的leader时,容忍n台节点的故障,需要2n+1个副本;
方案二:全部的follower同步完成,才可以发送ack;
优点:选举新的leader时,容忍n台节点的故障,需要n+1个副本;
缺点:延迟高;
kafka选择了方案二,全部完成后发送ack:
1.同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案需要n+1个副本,而kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余;
2.虽然第二种方案的网络延迟会比较高,但网络延迟对kafka的影响较小;
3.ISR
采用第二种方案之后,摄像一下情景:leader接收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack,这个问题怎么解决?
leader维护了一个动态的in-sync-replica set(ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack,如果follower长时间未向leader不同数据,则该follower将被踢出ISR,该事件阈值由replica.time.max.ms参数设定,leader发生故障之后,就会从ISR中选举新的leader;
4.ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
所以kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择一下配置:
acks:
0:producer不等待broker的ack,这一操作提供了最低的延迟,broker一接收到还没哟写入磁盘就已经返回,当broker故障时有可能丢失数据;
1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
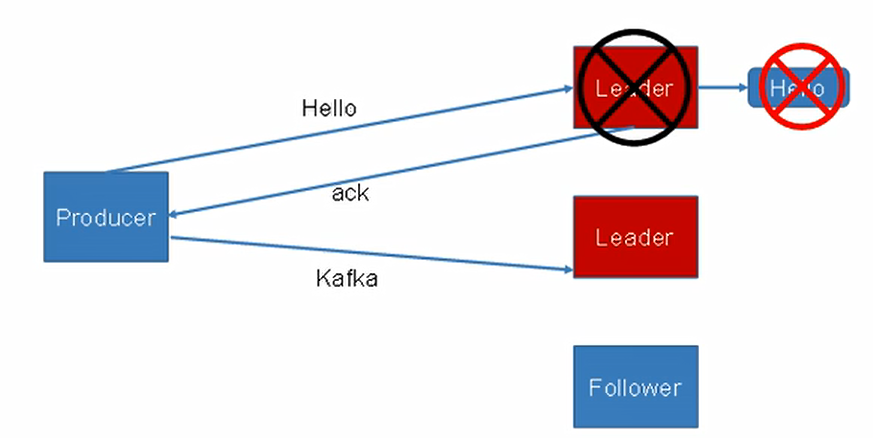
-1:producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack,但是如果在follower同步完成后,broker发送ack之前,leader发送故障,那么会造成数据重复;
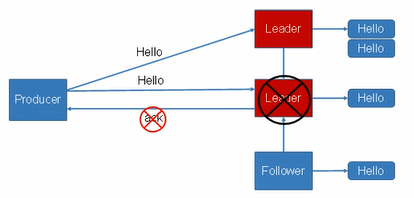
5.故障细节处理
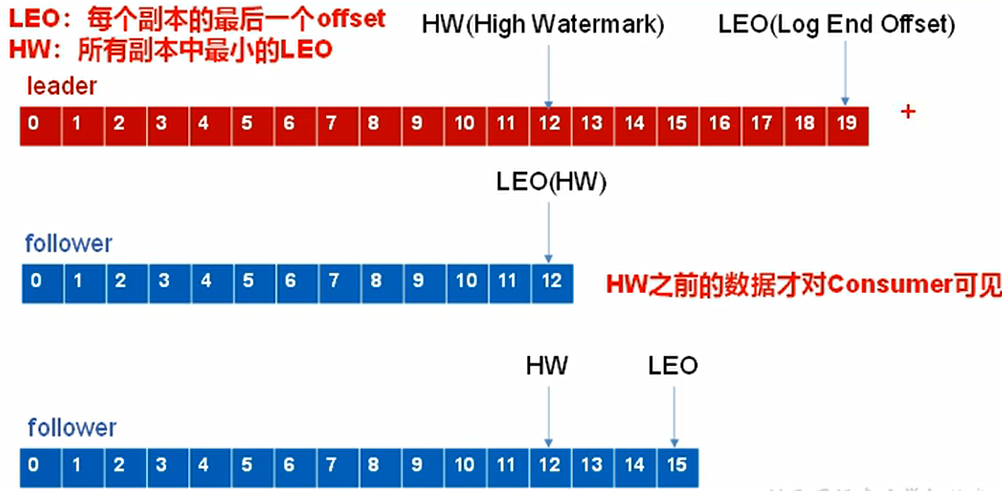
Log文件的HW和LEO
LEO:每个副本的最后一个offset
HW:所有副本最小的LEO(ISR队列最小的LEO)
1.follower故障
follower发生故障会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录上传的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步,等该follower的LEO大于等于partition的HW,即follower追上leader之后,就可以重新加入ISR了;
2.leader故障
leader发生故障之后,会从ISR中选择一个新的leader,之后,为了保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截取掉,然后从新出的leader同步数据;
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复;
6.Exactly Once语义
将服务器的ack级别设置为-1,可以保证producer到server之间不会丢失数据,即AtLeast Once语义,相对的,将服务器ack级别设置为0,可以保证生产者每条消息只会被发送一次,即AtMost Once语义;
AtLeast Once可以保证数据不丢失,但是不能保证数据不重复;相对的,AtLeast Once可以保证数据不重复,但是不能保证数据不丢失。但是,对于一些非常重要的信息,比如说:交易数据,下游数据消费者要求数据既不重复也不丢失,即Exactly Once语义,在0.11版本之前的kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重,对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大的影响。
0.11版本的kafka,引入一项重大的特征,幂等性,所谓的幂等性就是指producer不论向server发送多少次重复数据,server端只会持久一条,幂等性结合AtLeast Once语义,就构成了kafka的Exactly Once语义,即
AtLeast Once+幂等性=Exactly Once;
要启用幂等性,只需要将producer的参数中enable.idompotence设置为true即可,kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游,卡其幂等性的producer在初始化的时候会被分配一个PID,发往同一个partition的消息会附带sequenceNumber,而broker端会对<PID,Partition,SeqNumber>做缓存,当具有相同主键的消息提交时时,broker只会持久化一条。
但是PID重启就会变化,同时不同的partition也具有不同主键,所以幂等性无法保证跨分区跨回话的Exactly Once