1.导入依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>E:/jdk1.8.0_73/jdk1.8.0_73/lib/tools.jar</systemPath>
</dependency>
</dependencies>
2.编写WcMapper
package com.wn.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.junit.Test;
import java.io.IOException;
public class WcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text word=new Text();
private IntWritable one=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到这一行数据
String line = value.toString();
//按照空格切分数据
String[] words = line.split(" ");
//遍历数组
for (String word:words){
this.word.set(word);
context.write(this.word,this.one);
}
}
}
3.编写WcReducer
package com.wn.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WcReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable total=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//做累加
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//包装结果并输出
total.set(sum);
context.write(key,total);
}
}
4.编写WcDriver
package com.wn.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取一个Job实例
Job job = Job.getInstance(new Configuration());
//设置类路径
job.setJarByClass(WcDriver.class);
//设置mapper和reducer
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
//设置mapper和reducer输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入的数据
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
5.运行打包
打包完成后,会在对应的target目录下生成.jar文件
6.上传并执行
6.1 使用【rz】命令将.jar文件上传到hadoop上
6.2 运行wordcount程序
hadoop jar hadoop-1.0-SNAPSHOT.jar com.wn.wordcount.WcDriver /input.txt /output
执行完成后会在HDFS上生成对应的output文件
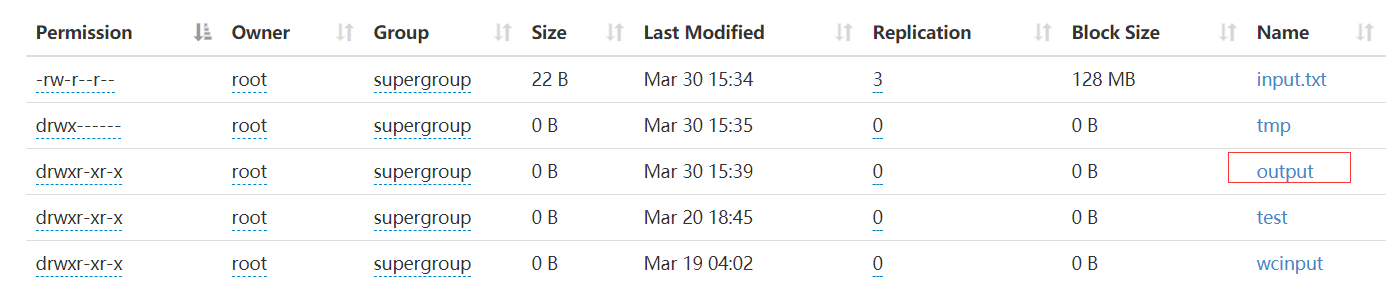
6.3 查看运行结果
hadoop fs -cat /output/*

7.WordCount流程
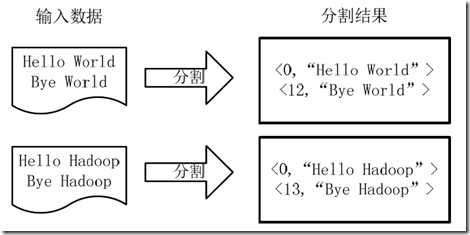
7.1 将文件拆分成splits,由于测试用的文件较小,所以每个文件为一乐splits,并将文件按行分割形成<key,value>对,key为偏移量,value为文本行;这一步有MapReduce框架自动完成;
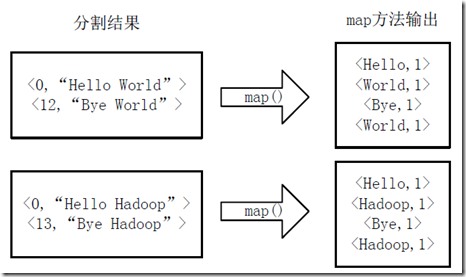
7.2 将分给好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对;
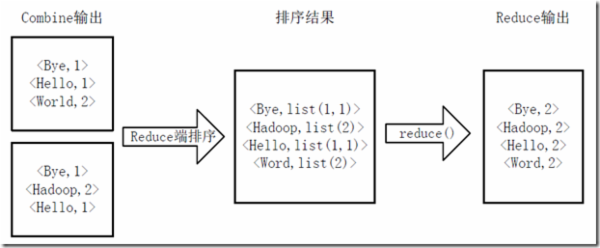
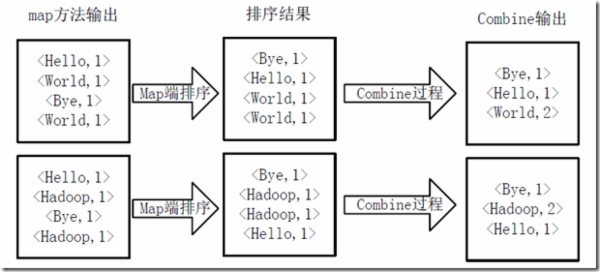
7.3 得到map方法输出的<key,value>对后,mapper会将他们按照key值进行排序,并执行Combine过程,将key值相同的value累加,得到mapper的最终输出结果;
7.4 reducer先对从mapper接收的数据进行排序,在交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为wordcount的输出结果;