1.Hive简介
Hive是构建在hadoop之上的数据操作平台;
Hive是一个SQL解释引擎,它将SQL转译成MapReduce作业,并在hadoop上运行;
Hive表是HDFS的一个文件目录,一个表名对应一个目录名,如果存在分区表的话,则分区值对应子目录名;
2.Hive的历史由来
Hive是有Facebook开发的,构建与hadoop集群之上的数据仓库应用,2008年Facebook将Hive项目贡献给Apache,成为开源项目之一;
hadoop与Hive组建称为Facebook数据仓库的发展史;
mysql:随着数据量增加,某些查询需要几个小时甚至几天才能完成,当数据量达到1T时,mysql进程垮掉;
Oracle:可以支撑几个T的数据,但每天收集用户点击流数据(每天约400个G)时,Oracle开始无法支撑;
hadoop:有效的解决了大规模数据的存储与统计分析的问题,但是MapReduce程序对于普通分析人员说使用过于复杂;
Hive:对外提供了类似SQL语法的HQL语句的数据接口,自动将HQL语句编译转化为MR作业后在hadoop上运行,降低了开发人员使用hadoop时对数据分析的难度;
3.Hive的体系结构

Hive作为hadoop的数据仓库处理工具,它所有的数据都存储在hadoop兼容的文件系统中;Hive在加载数据的过程中不会对数据进行任务的修改,只是将数据移动到HDFS中Hive设置的指定目录下;因此,Hive不支持对数据的改写和添加,所有的数据都是在加载的时候设定的;
Hive的设置特点:
(1)支持索引,加快数据查询;
(2)不同的存储类型,例如:纯文本文件,HBase中的文件;
(3)将元数据保存在关系型数据库中,减少了在查询中执行语义的检查时间;
(4)可以直接使用存储在hadoop文件系统中的数据;
(3)内置大量的用户UDF来操作时间,字符串和其他数据挖掘工具,支持用户扩展UDF来完成内置函数无法完成的操作;
(4)类SQL的查询方式,将SQL查询转换为MapReduce的JOB在hadoop集群上执行;
(5)编码与hadoop同样采用UTF-8;
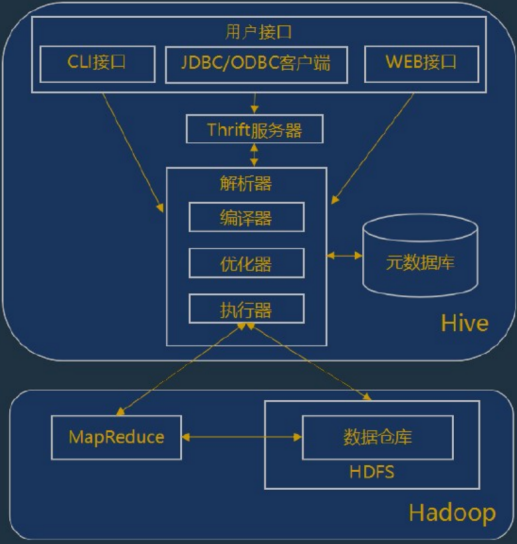
用户接口:
(1)CLI:CLI启动的时候,会同时启动一个Hive副本;
(2)JDBC客户端:封装了Thrift,java应用程序可以通过指定的主机和端口连接到了另一个进程中的Hive服务;
(3)WEB接口:通过浏览器访问Hive服务;
Thrift服务器:
基于Socket通讯,支持跨语言;Hive的Thrift服务简化了在多编程语言中运行Hive命令,绑定支持C++,JAVA,PHP和Ruby语言;
解析器:
(1)编译器:完成HQL语句的从词法分析,语法分析,编译优化以及执行计划的生成;
(2)优化器:是一个演化组件,当前它的规则是:列修剪,谓词下压;
(3)执行器:会顺序执行所有的JOB;如果Task链不存在依赖关系,可以采用并发方式执行JOB;
元数据库:
Hive的数据有两个部分组成:数据文件和元数据;元数据用于存放Hive库的基础信息,它存储在关系型数据库中,如mysql,Derby;元数据包括:数据库信息,表的名字,表的列和分区及其属性,表的属性,标的数据所在目录等;
hadoop:
Hive的数据文件存储在HDFS中,大部分的查询有MapReduce构成,不过对于包含*的查询,比如select * from lbl不会生成MapReduce作业;
4.Hive的运行机制
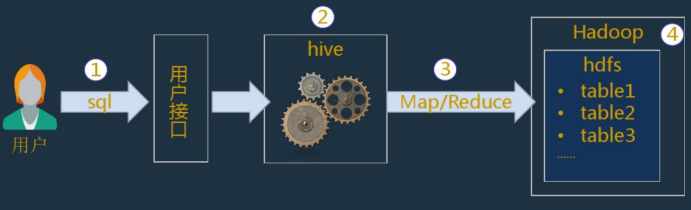
(1)用户通过用户接口连接Hive,发布Hive SQL;
(2)Hive解析查询并制定查询计划;
(3)Hive将查询转换为MapReduce作业;
(4)Hive在hadoop上执行MapReduce作业;
5.Hive的应用场景(优势)
(1)解决了传统关系型数据库在大数据处理上的瓶颈,适合大数据的批量处理;
(2)充分利用集群的CPU计算资源,存储资源,实现并行计算;
(3)Hive支持标椎SQL语法,免去了编写MR程序的过程,提升开发效率;
(4)具有良好的扩展性,拓展功能很方便;
6.Hive的应用场景(缺点)
(1)Hive的HQL表达能力有限:有些复杂运算HQL不易表达;
(2)Hive的效率低:Hive自动生成MR作用,通常不够智能;HQL调优困难,粒度较粗,可控性差;
(3)针对Hive运行效率低下等问题,促使人们去寻找一种更快,更具有交互性的分析框架;SparkSQL的出现则有效的提高了SQL在hadoop上的分析效率