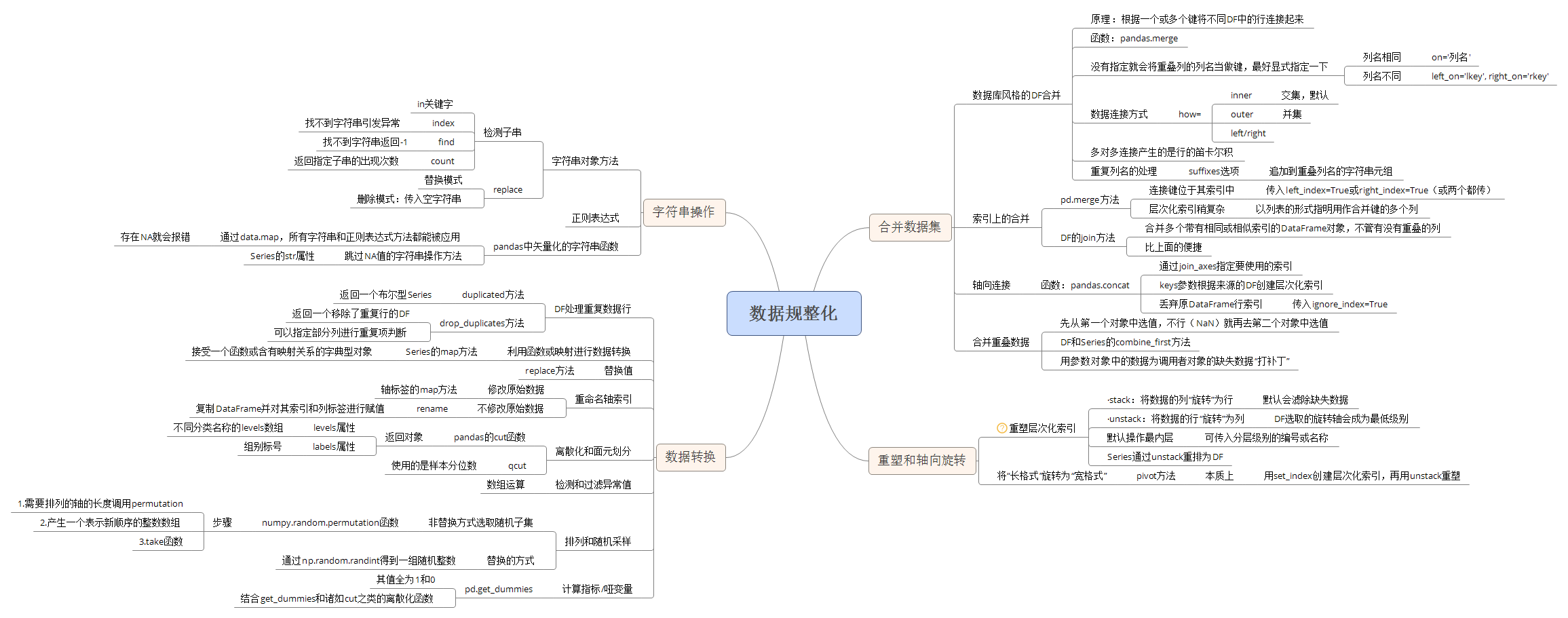
- 数据库风格的DataFrame合并(pandas.merge方法):
- 通过一个或多个键将行链接起来的
- 如果没有指定要用哪个列进行连接,merge就会将重叠列的列名当做键。最好显式指定一下(on=; left_on, right_on;)
- 默认情况下,merge做的是"inner"连接;结果中的键是交集。其他方式还有"left"、"right"以及"outer"。外连接求取的是键的并集,组合了左连接和右连接的效果。
- 多对多连接产生的是行的笛卡尔积
- 要根据多个键进行合并,传入一个由列名组成的列表即可


- 索引上的合并:
- DataFrame中的连接键位于其索引中,merge函数传入left_index=True或right_index=True(或两个都传)
- DataFrame还有一个join实例方法,它能更为方便地实现按索引合并(默认在连接键上做左连接)
- 对于简单的索引合并,你还可以向join传入一组DataFrame
- 轴向连接:

- 合并重叠数据:
- combine_first方法:用参数对象中的数据为调用者对象的缺失数据“打补丁”(先从第一个对象中选值,不行就再去第二个对象中选值)
重塑和轴向旋转:
- 重塑层次化索引:
- ·stack:将数据的列“旋转”为行。
- ·unstack:将数据的行“旋转”为列。
- 默认情况下,unstack操作的是最内层(stack也是如此)。传入分层级别的编号或名称即可对其他级别进行unstack操作。
- 如果不是所有的级别值都能在各分组中找到的话,则unstack操作可能会引入缺失数据。
- stack默认会滤除缺失数据,因此该运算是可逆的
- 将“长格式”旋转为“宽格式”:
- pivot方法:只是一个快捷方式而已:用set_index创建层次化索引,再用unstack重塑
数据转换:
- 移除重复数据:
- DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行
- drop_duplicates方法返回一个移除了重复行的Data-Frame
- 默认会判断全部列,你也可以指定部分列进行重复项判断
- 利用函数或映射进行数据转换:
- Series的map方法可以接受一个函数或含有映射关系的字典型对象
- map方法实现的是元素级转换
- 替换值:
- replace方法
- fillna方法,map
- 重命名轴索引:
- 可以通过函数或映射进行转换,从而得到一个新对象。
- 赋值给index属性,轴还可以被就地修改,而无需新建一个数据结构。
- 如果想要创建数据集的转换版(而不是修改原始数据),比较实用的方法是rename(结合字典型对象实现对部分轴标签的更新)
- 离散化和面元划分:
- cut函数:查看结果的codes属性和categories属性
- 圆括号表示开端,而方括号则表示闭端(包括)
- 如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元。
- qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分
- 检测和过滤异常值:
- 很大程度上其实就是数组运算
- 要选出全部含有“超过3或-3的值”的行,你可以利用布尔型DataFrame以及any方法
- np.sign这个ufunc返回的是一个由1和-1组成的数组,表示原始值的符号,将值限制在区间-3到3以内:np.sign(data) * 3
- 排列和随机采样:
- 通过需要排列的轴的长度调用permutation,可产生一个表示新顺序的整数数组
- 如果不想用替换的方式选取随机子集,则可以使用permutation:从permutation返回的数组中切下前k个元素,其中k为期望的子集大小。
- 要通过替换的方式产生样本,最快的方式是通过np.random.randint得到一组随机整数
- 计算指标/哑变量:
- 将分类变量转换为“哑变量矩阵”或“指标矩阵”:如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)
- get_dummies函数
- 一个对统计应用有用的秘诀是:结合get_dummies和诸如cut之类的离散化函数
字符串对象方法
- 字符串对象方法:
- 检测子串的最佳方式是利用Python的in关键字(当然还可以使用index和find)
- count函数,它可以返回指定子串的出现次数
- replace用于将指定模式替换为另一个模式。它也常常用于删除模式:传入空字符串。


- 正则表达式:

- pandas中矢量化的字符串函数:
- Series有一些能够跳过NA值的字符串操作方法。通过Series的str属性即可访问这些方法。

