Redis常用数据类型对应的数据结构
Redis数据库
- Redis 是一种键值(Key-Value)数据库。相对于关系型数据库(比如 MySQL),也被叫作非关系型数据库。
- 常用的数据类型:
- 字符串、列表、字典、集合、有序集合。
列表(list)
- 支持存储一组数据。两种实现方法:
- 压缩列表(ziplist)
- 双向循环链表
- 压缩列表
- 数据量比较小的时候采用压缩列表的方式实现:
- 列表中保存的单个数据(有可能是字符串类型的)小于 64 字节;
- 列表中数据个数少于 512 个。
- 非基础数据结构,类似数组,通过一片连续的内存空间,来存储数据,与数组不同的是,它允许存储的数据大小不同:
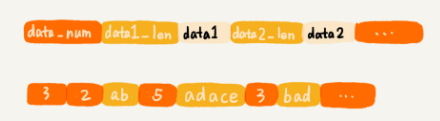
- 数据量比较小的时候采用压缩列表的方式实现:
-
双向循环链表
-
数据量比较大的时候使用(不满足压缩列表的两个条件时)
- redis的实现方式
- 额外定义一个 list 结构体,来组织链表的首、尾指针,还有长度等信息
-
// 以下是C语言代码,因为Redis是用C语言实现的。 typedef struct listnode { struct listNode *prev; struct listNode *next; void *value; } listNode; typedef struct list { listNode *head; listNode *tail; unsigned long len; // ....省略其他定义 } list;
-
字典(hash)
- 用来存储一组数据对。每个数据对又包含键值两部分。
- 两种实现方式:
- 刚刚讲到的压缩列表
- 散列表
- 散列表:
- 散列函数:MurmurHash2这种运行速度快、随机性好的哈希算法作为哈希函数。
- 哈希冲突: 使用链表法来解决。
- 动态扩容、缩容:
- 当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右。
- 当装载因子小于 0.1 的时候,Redis 就会触发缩容,缩小为字典中数据个数的大约 2 倍大小。
- 大量的数据搬移耗时问题:Redis 使用渐进式扩容缩容策略,将数据的搬移分批进行,避免了大量数据一次性搬移导致的服务停顿:
- 当装载因子触达阈值之后,只申请新空间,但并不将老的数据搬移到新散列表中;
- 当有新数据要插入时,将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表;
- 每次插入一个数据到散列表,都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了;
- 这样没有了集中的一次性数据搬移,插入操作就都变得很快了;
集合(set)
- 用来存储一组不重复的数据。
- 两种实现方法,一种是基于有序数组,另一种是基于散列表。
- 当存储的数据都是整数且存储的数据元素个数不超过 512 个时使用有序数组实现。
- 否则使用散列表实现。
有序集合(sortedset)
- 存储有序且不重复的数据
- 也是两种实现方法:
- 当所有数据的大小都小于 64 字节;且元素个数要小于 128 个 时,使用压缩列表
- 否则使用跳表
数据结构持久化
- 尽管 Redis 经常会被用作内存数据库,但是,它也支持数据落盘。
- 数据结构的持久化问题:
- 很多类型底层用到了散列表,散列表中有指针的概念,而指针指向的是内存中的存储地址。 那 Redis 是如何将这样一个跟具体内存地址有关的数据结构存储到磁盘中的呢?
- 两种思路:
- 清除原有的存储结构,只将数据存储到磁盘中。当需要从磁盘还原数据到内存的时候,再重新将数据组织成原来的数据结构。实际上,Redis 采用的就是这种持久化思路。
- 弊端:需要重新计算每个数据的哈希值,太耗时
- 保留原来的存储格式,将数据按照原有的格式存储在磁盘中。
- 我们拿散列表这样的数据结构来举例:
- 可以将散列表的大小、每个数据被散列到的槽的编号等信息,都保存在磁盘中。
- 有了这些信息,我们从磁盘中将数据还原到内存中的时候,就可以避免重新计算哈希值。
- 弊端:记录信息复杂,实现成本高。
- 清除原有的存储结构,只将数据存储到磁盘中。当需要从磁盘还原数据到内存的时候,再重新将数据组织成原来的数据结构。实际上,Redis 采用的就是这种持久化思路。
关于压缩列表
压缩列表优点:访问存取快速,节省内存。但是受到操作系统空闲内存限制。越大的连续内存空间越不容易申请到。所以用了其他数据结构比如链表替代。
压缩列表不支持随机访问。有点类似链表。但是比较省存储空间。Redis一般都是通过key获取整个value的值,也就是整个压缩列表的数据,并不需要随机访问。
小数据量时获取压缩列表所有数据直接顺序查找即可,因为量小,不会太影响查找性能;
大数据量时考虑查找性能和连续内存空间的申请,不再适合压缩列表。