版权声明:本文为博主原创文章,未经博主允许不得转载。
看到汇编中很多关于程序返回与中断返回时处理地址都很特别,仔细想想原来是流水线作用的效果。所以,决定总结学习下ARM流水线。
ARM7处理器采用3级流水线来增加处理器指令流的速度,能提供0.9MIPS/MHz的指令处理速度。
PS:
MIPS(Million Instruction Per Second)表示每秒多少百万条指令。比如0.9MIPS,表示每秒九十万条指令。
MIPS/MHz表示CPU在每MHz的运行速度下可以执行多少个MIPS,如0.9MIPS/MHz则表示如果CPU运行在1MHz的频率下,每秒可执行90万条指令。
如果CPU在20MHz的频率下,每秒可运行1800万条指令。MIPS/MHz可以很好的反映CPU的速度。
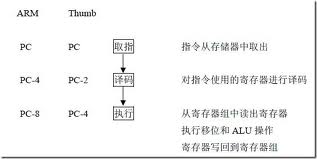
3级流水线如上图所示(PC为程序计数器),流水线使用3个阶段,因此指令分3个阶段执行。
⑴ 取指从存储器装载一条指令
⑵ 译码识别将要被执行的指令
⑶ 执行处理指令并将结果写会寄存器
以前学过的51单片机,因为比较简单,所以它的处理器只能完成一条指令的读取和执行后,才会执行下一条指令。这样,PC始终指向的正在“执行”的指令。
而对于ARM7来说因为是3级流水线,所以把指令的处理分为了上面所述的3个阶段。
所以处理时实际是这样的:ARM正在执行第1条指令的同时对第2条指令进行译码,并将第3条指令从存储器中取出。
所以,ARM7流水线只有在取第4条指令时,第1条指令才算完成执行。
下图生动形象的说明了3级流水线的处理机制
下面一句话很关键:无论处理器处于何种状态,程序计数器R15(PC)总是指向“正在取指”的指令,而不是指向“正在执行”的指令或者正在“译码”的指令。
人们一般会习惯性的将正在执行的指令作为参考点,即当前第1条指令。
所以,PC总是指向第3条指令,
或者说PC总是指向当前正在执行的指令地址再加2条指令的地址。
处理器处于ARM状态时,每条指令为4个字节,所以PC值为正在执行的指令地址加8字节,即是:
PC值 = 当前程序执行位置 + 8字节
处理器处于Thumb状态时,每条指令为2字节,所以PC值为正在执行的指令地址加4字节,即是:
PC值 = 当前程序执行位置 + 4字节
下面一个例子就很好的说明了这个问题。
- 0x4000 ADDPC,PC,#4 ;正在被执行的指令,将地址值PC+4写入PC
- 0x4004 ...;正在被译码的指令
- 0x4008 ...;正在被取指的指令,PC=0x4008
- 0x400C ...;PC+4=0x400C
另外补充说明就是根据以上描述,流水线只有被指令填满时才能发挥最大效能,即每时钟周期完成一条指令的执行(仅单周期指令)。
如果程序发生跳转,流水线会被清空,这将需要几个时钟才能使流水线被再次填满。因此,尽量地少使用跳转指令可以提高程序的执行效率。
以上就是对ARM73级流水线的一个总的认识,参考来自学习ARM时的教材——《ARM嵌入式系统基础教程(第二版)》。