1. 动态路由的匹配器?
不知道这种叫啥名,啥用法,暂且叫做匹配器吧。
Flask自带的匹配器可以说有四种吧(保守数字,就我学到的)
- 动态路由本身,可以传任何参数字符串或者数字,如:<username>
- 只能传整形数字,如:<int:user_id>
- 只能传浮点型数字,如:<float:num>
- 只能传path路径,如:<path:url>
举个例子
1 from flask import Flask 2 3 app = Flask(__name__) 4 5 @app.route('/user/<int:user_id>' 6 def user(user_id): 7 return 'Hello,%d' %user_id 8 9 if __name__ == '__main__': 10 app.run(debug=True)
这个user的路由只能响应整型的数字路径,不能输入字符串的
当然上面的很简单,接下来,我要定义一个使用更广泛,功能更强大的
正则匹配器
1 #coding:utf-8 2 3 from flask import Flask 4 from werkzeug.routing import BaseConverter 5 6 #定义正则转换器的类 7 class RegexConverter(BaseConverter): 8 def __init__(self,url_map,*items): 9 super(RegexConverter, self).__init__(url_map) 10 self.regex=items[0] 11 12 app = Flask(__name__) 13 #实例化 14 app.url_map.converters['regex']=RegexConverter 15 16 @app.route('/user/<regex("([a-z]|[A-Z]){4}"):username>', methods=['POST', 'GET']) 17 def user(username): 18 return 'Hello,%s' % username 19 20 if __name__ == '__main__': 21 app.run(debug=True)
我们在转化器中规定,只能是四个英文字符才能被这个路由匹配,多余或者少于都不行
我们来看看效果,先输入Bikmin,五个字符,Not Found
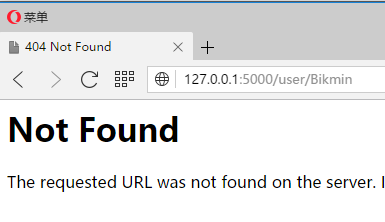
再来输入正确的字符数字:Ming

现在已经成功@@
2. HTML中的过滤器
HTML中经常要使用各种转换器
最常见的就是safe了(这是自带的)
更多官方过滤器请查看: List of Builtin Filters
我们先举个safe的例子了解下这个过滤器是如何作用的
#Sample.py
@app.route('/home') def hone(): return render_template('index.html',title='<h1>Hello,World!</h1>')
#index.html
<body> {{ title }} </body>
运行,输出如图
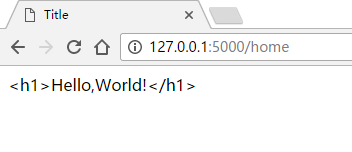
这是为什么呢?因为Jinjia2处于安全考虑,没有进行转义
这种情况下,我们就可以使用safe转化器了(自带的)
将#index.html 改为
<body> {{ title|safe }} </body>
再次运行,输出如图
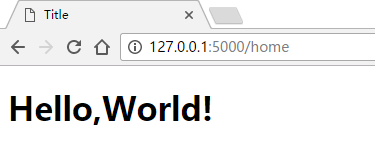
附:上面这种情况除了过滤器起之外,还有另一种方法:块
#index.html
<body> {% autoescape false %} {{ title }} {% endautoescape %} </body>
同样的,我们也许需要自定义我们自己的过滤器
这里我们就自定义个,可以将markdown语法的文件进行转义输出到页面的过滤器
首先要先安装markdown这个库
pip install markdown
#Sample.py
1 # coding:utf-8 2 3 from flask import Flask,render_template 4 5 app = Flask(__name__) 6 7 @app.route('/home') 8 def hone(): 9 return render_template('index.html',title='## header 2') 10 11 # 这里定义一个过滤器,取名为'md' 12 @app.template_filter('md') 13 def md_to_html(txt): 14 from markdown import markdown 15 return markdown(txt) 16 17 18 if __name__ == '__main__': 19 app.run(debug=True)
现在我们就可以使用md这个过滤器了
#index.html
<body> {{ title|md }} </body>
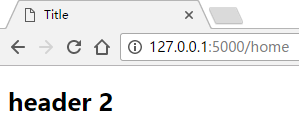
运行,查看结果

这时我们发现,markdown语法(##)已经转换成html格式的<h2>标签,说明起作用了
当然我们还需要用前面讲过的safe进行 转义
#index.html
<body> {{ title|md|safe }} </body>
至此,我们已经学会了如何自定义一个过滤器了
-------------------------------------------------以下内容,扩展,选择性学习-------------------------------------------------
在日常工作中,我们不能只对变量进行md转换吧?
我们可能会从一个文本中进行读取,然后渲染到html页面中
这时我们就要定义一个函数,读取文本内容到内存中,赋值给变量,在对其进行md转换。
首先我们要写一个markdown格式的文件,注意不要用notepad来写,读取的时候会有编码错误,调都调不回来
建议使用Pycharm来新建一个http_methods.md的文件并写入:
# 常见的HTTP方法 ## GET 浏览器告知服务器:只获取页面的信息发给我 这是常用的方法 ## POST 浏览器告知服务器:想在URL中发布新信息 并且,服务器必须确保数据已存储且只存储一次 这是HTML中发送表单数据到服务器的一种方法
代码如下:
#Sample.py
1 # coding:utf-8 2 3 from flask import Flask,render_template 4 5 app = Flask(__name__) 6 7 @app.route('/home') 8 def hone(): 9 return render_template('index.html',title='## header 2') 10 11 @app.template_filter('md') 12 def md_to_html(txt): 13 from markdown import markdown 14 return markdown(txt) 15 16 def read_md_file(filename): 17 with open(filename) as md_file: 18 content = reduce(lambda x,y:x+y,md_file.readlines()) 19 return content.decode('utf-8') 20 21 # 注意:这里很重要,作用是把read_md_file()这个函数注册到所有的Jinjia模板中 22 # 不然html中会找不到这个函数而出错 23 @app.context_processor 24 def inject_methods(): 25 return dict(read_md=read_md_file) 26 27 # read_md是html使用的函数名,read_md_file是上面定义的函数名 28 29 if __name__ == '__main__': 30 app.run(debug=True)
#index.html
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 {{ read_md('http_methods.md')|md|safe }} 9 </body> 10 </html>
运行,结果如下
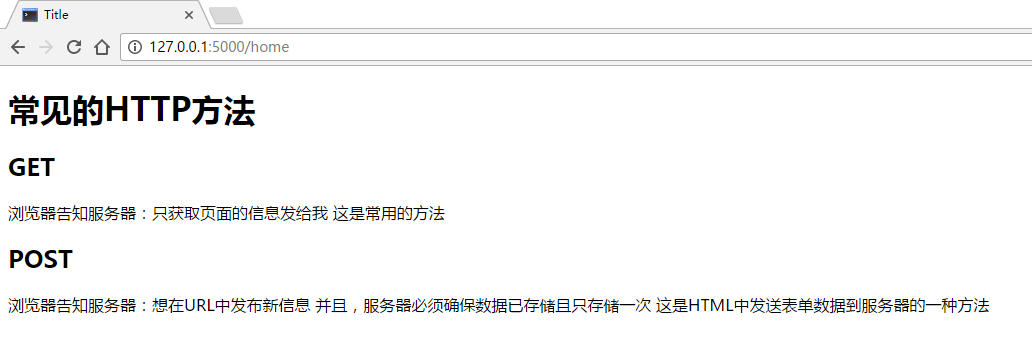
已经打到我们想要的效果@@
